Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
Hi everyone, in you experience, is a larger training set better than a smaller one in dreambooth? Like do i get better results with 10 pictures of myself or 100? Or do I just get overtraining?
Hi, I'm trying to train a LORA model in Dreambooth on Automatic1111. I got it to kind of work a few times but now I can't seem to get good results. It seems like using a class data set along with my images makes the result worse. If I share my parameters/data info could someone give me some tips on what to change?
does anyone know how to update the Lora models in Auto1111 when you click refresh. I actually have to quite the terminal and relaunch from scratch. Refresh Lora tab and reload webui, neither refresh the new model in. Any thoughts?
I just got some pretty good results with this data and these settings:
42 training images of myself in different situations/lighting caption .txt files that go along with the images RealisticVisionV20 as a source checkpoint
Saving -Use Lora -use Lora extended -100 steps/epochs -batch size 2 -use gradient checkpointing -0.00001 unet learning rate -constant_with_warmup LR scheduler -other settings from all the vids, 8bit AdamW, fp16, xformers -Scale prior loss (checked, did not edit values) -no sanity prompt
Concepts -Used directory with photos of me, and .txt files with the token I assigned replacing my name -no class data -instance token is my name without vowels -class token is man -instance and class prompts are [filewords] -sample prompt boxes are blank -no class img gen
I'd rate the results i'm getting 7 or 8 out of 10, any tips appreciated
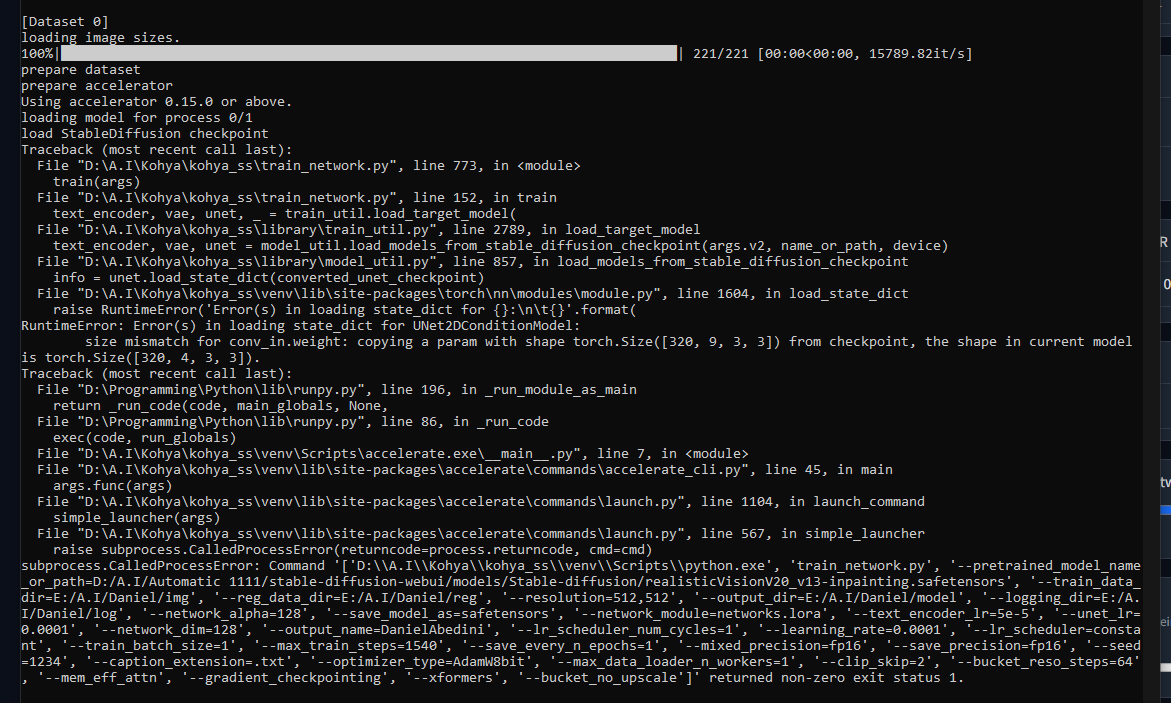
Hi @Furkan Gözükara SECourses got a question. Trying to update StableTuner to Torch2.0. I am looking at your tut. Yours is venv/Scripts/activate... But i installed virtual environment with miniconda3. So would i do the same in envs/ST/Scripts/activate (ST is the name of the environment).. everything else the same?
a atempted to use merge checkpoint and use an inpaint model with the dreambooth model and then put vanilla 1.5 as C and do add difference, but it completly messes up the dreambooth model and makes the trained subject barley useable..
try something like "photo of fashion model walking in the street in london in the style of i-D magazine 2000's by mario testino, masterpiece, film camera
but the problem is that it doesn't take dreambooth in to account.. I'm sure it works on ordinary models but for dreambooth it seems to completly mess up the trained part of the dreambooth model, almost as if it's too much of a specific part of the model, where ordinary models have a more general training data..
 N
N F
F H
H S
S
 A
A R
R D
D