does anyone know what is Stable Diffusion by Automatic1111, why do we need it if I already have stab
does anyone know what is Stable Diffusion by Automatic1111, why do we need it if I already have stable diffusion in kohya_ss
 P
P N
N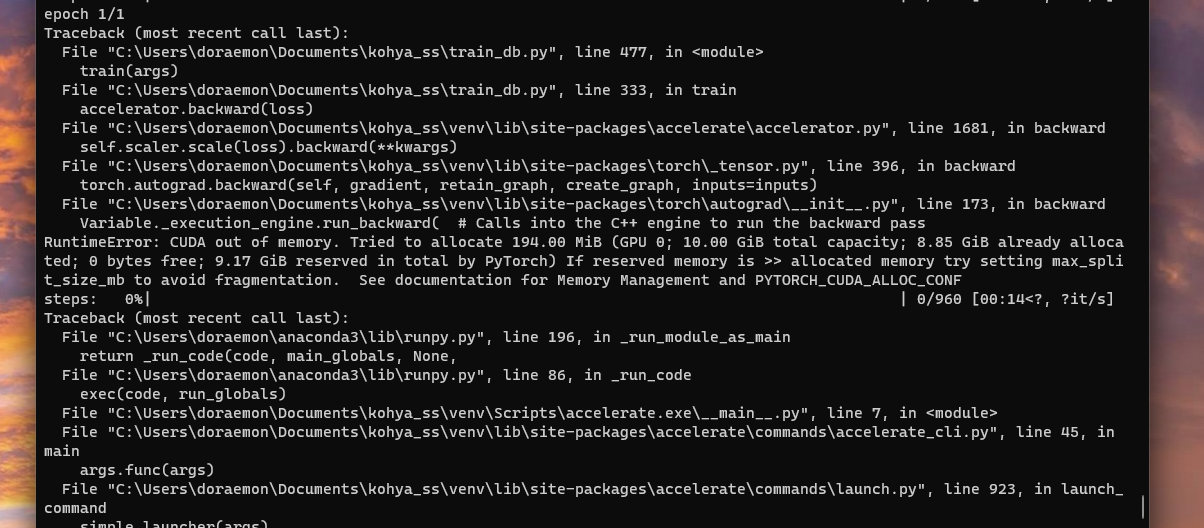 N
N N
N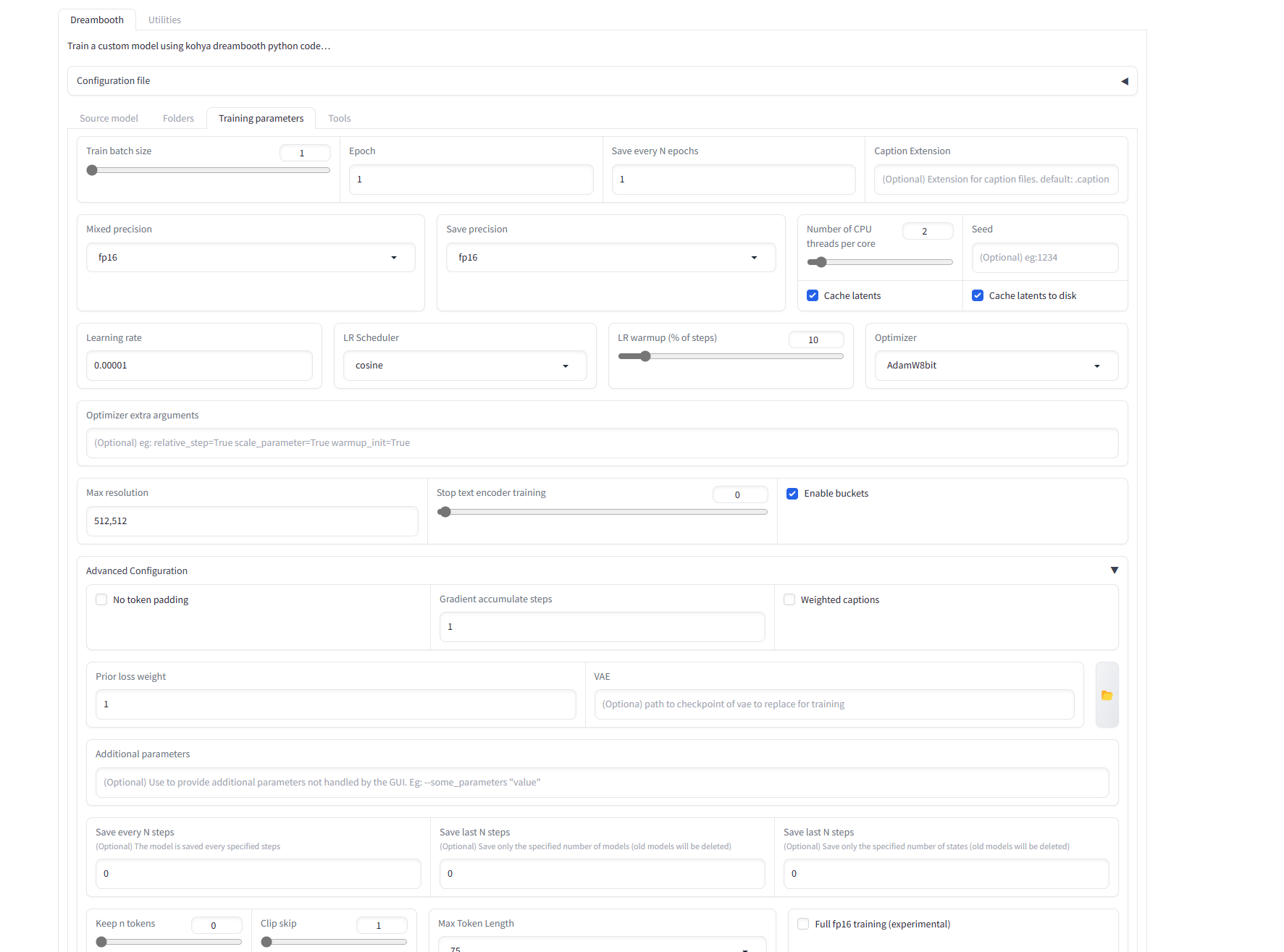
 K
K https://www.patreon.com/SECourses
https://www.patreon.com/SECourses K
K D
D S
S AA
AA AA
AA
 H
H M
M
 M
M FFFFFFFFFFFFFFFA
FFFFFFFFFFFFFFFA F
F DFFDFDDDAHAH
DFFDFDDDAHAH B
B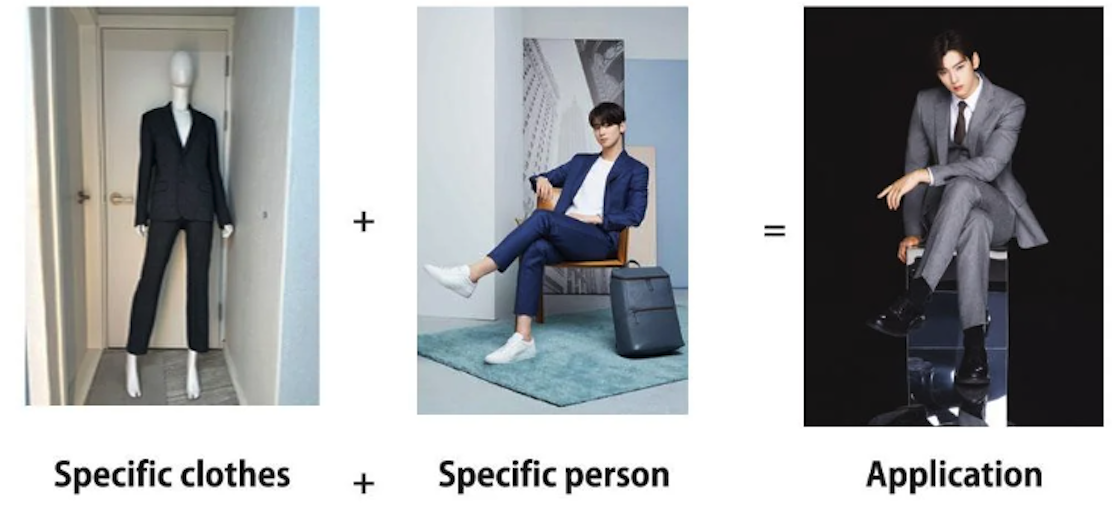
 FBDD
FBDD









