Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
@Dr. Furkan Gözükara I have accumulated 500k images for faces and 100k images for landscape photography. I think we can achieve realistic generations with such a huge dataset. I want to divide each dataset into multiple mini-datasets so that we can train mini-models of each and later merge the mini-models into a single huge model. I am looking for collaborators because it is going to be a huge model, we need a team to make it efficient and quick. I am even and for suggestions. I am looking to caption the images using minigpt4. Can you please collaborate or is anyone interested?
want to collaborate with people who can help me with training as I am new, to training I am looking for people who have a gpu so that we can use the machine power to train the model as it cannot be trained using 1 or 2 gpus(if thats the case it would take forever) and we even need to caption them so we gpu power for that. the dataset is gonna be split into multiple datasets, so those mini datasets can either be trained on colab or locally through gpus. I want to make faces realistic so that SD can come close to MJ. In SD as of now, all I see is waifu faces. Waifus faces are polished and dont have much detail in their faces like freckles, spots, etc. In case of male faces they dont have facial hair. Yep I am planning to include NSFW as thats the superior thing that SD has that no other image generators have I had accumulated 700k images from various subreddits.
@Dr. Furkan Gözükara no matter what i do i can get dreambooth extension to successfully create Lora and the Kohya gui wont work for me either. you do remote assistance/installation if were a part of your patreon ?
Best Stable Diffusion and AI Tutorials, Guides, News, Tips and Tricks - Stable-Diffusion/Generate-Studio-Quality-Realistic-Photos-By-Kohya-LoRA-Stable-Diffusion-Training-Full-Tutorial.md at main · ...
Hey @Dr. Furkan Gözükara is it possible to generate the same model (same face/ hair/ body proportions) but in different poses or backgrounds in stable diffusion? I been trying to generate a consistent character but am having a difficult time
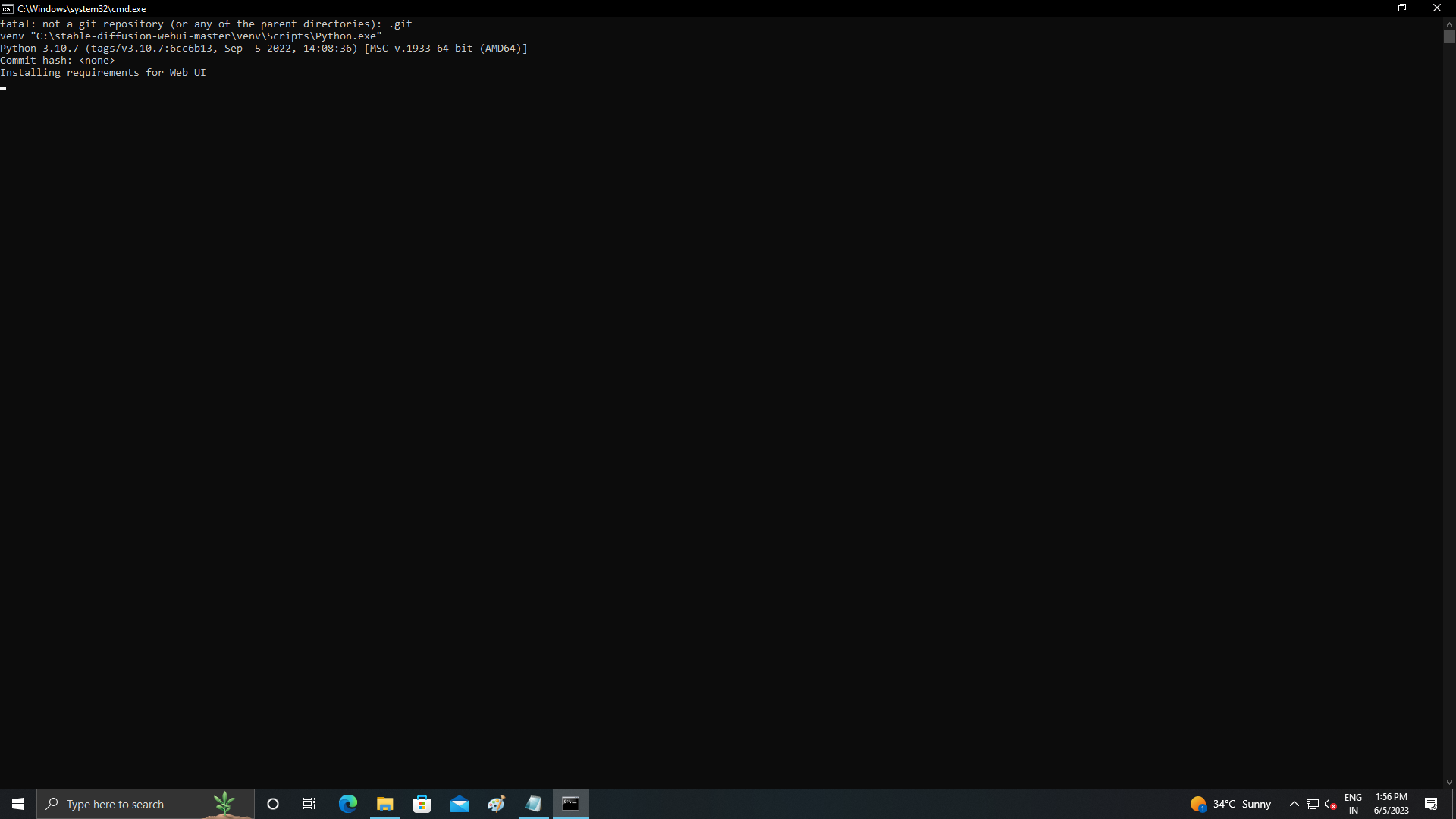
File "D:\voice cloning\tortoise-tts-fast\scripts\tortoise_tts.py", line 15, in <module> from tortoise.api import MODELS_DIR, TextToSpeech ModuleNotFoundError: No module named 'tortoise.api' Please help! I really need to get this tts model working.
Hey guys , i want to use lora models in stable diffusion, but i don't know how to update or use lora inside stable diffusion, i tried to update my repository but can't, any help for this , thanks in advance
I cannot see something like this after the installation, and i don't know how to use lora models, i cannot find lora checkpoint in my models tab in stabel diffusion
Hi, i want to fine tune a conditioned img2img stable diffusion model on the FFHQ aging dataset. The aim to create a model where you can age a picture of yourself. But i have trouble creating the training process in torch and i can't find any related work. Does sombody know anything related or can help me?
 E
E
 F
F Q
Q D
D
 J
J C
C T
T A
A A
A

 S
S




