make batch size 1 and gradient accumulation steps 1
make batch size 1 and gradient accumulation steps 1
 FF
FF X
X FFF
FFF TFT
TFT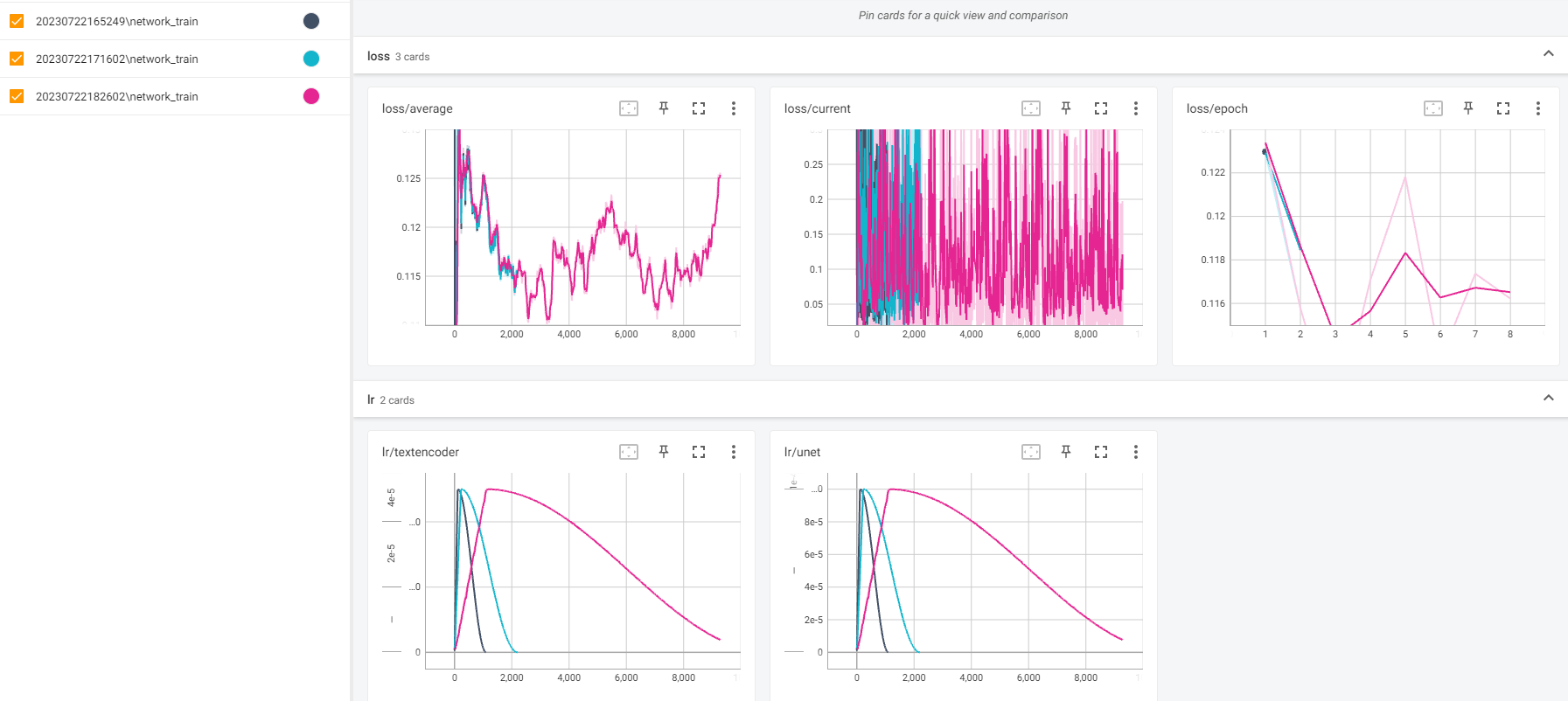 T
T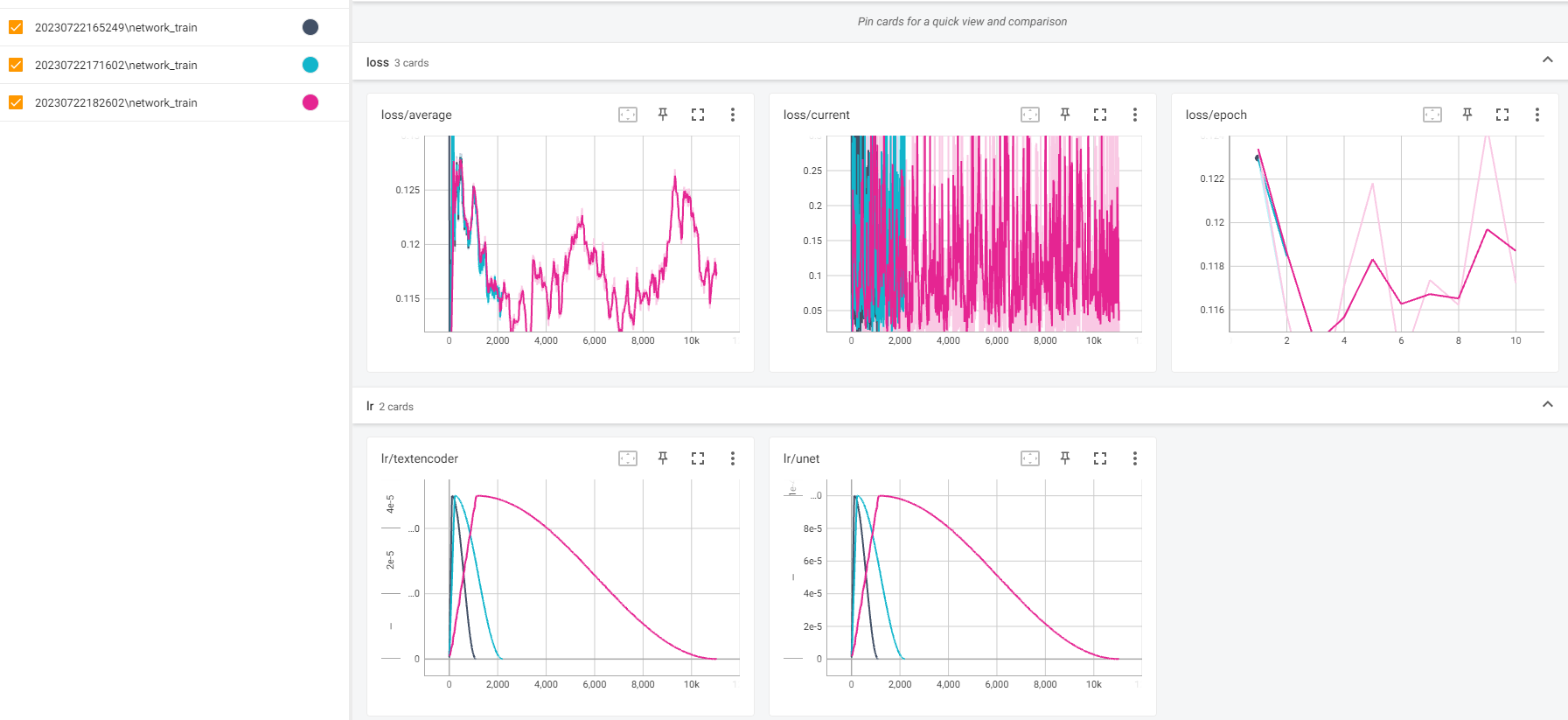 T
T H
H X
X U
U
 K
K K
K
 DKD
DKD DFFXFFX
DFFXFFX FFFFFUF
FFFFFUF AFFAFUU
AFFAFUU# Uncomment to disable TCMalloc
#export NO_TCMALLOC="True"FFF AF
AF C
C Thanks you very much
Thanks you very much K
K
 O
O Z
Z O
O# Uncomment to disable TCMalloc
#export NO_TCMALLOC="True"







