good job, from a first glance it does not look like it is changing that much? what is your impressio
good job, from a first glance it does not look like it is changing that much? what is your impression
 FFF
FFF BBFF
BBFF S
S MFMM
MFMM M
M RFF
RFF FR
FR K
K | RunPod CLI for pod management. Contribute to runpod/runpodctl development by creating an account on GitHub.
| RunPod CLI for pod management. Contribute to runpod/runpodctl development by creating an account on GitHub.
 TMFFFFFTFFFT
TMFFFFFTFFFT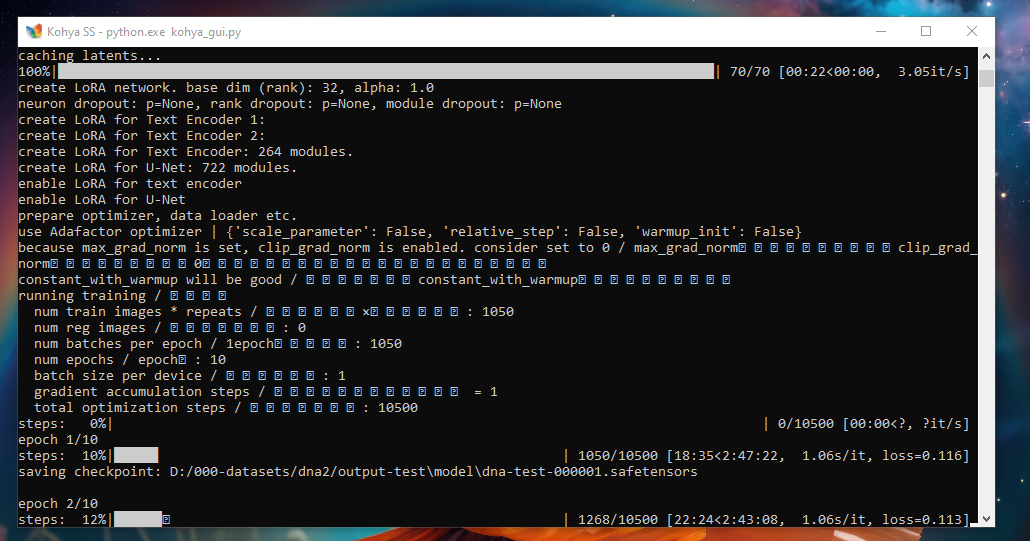 TTFFF
TTFFF SS
SS LSLL
LSLL MM
MM KSMS
KSMS






