or if you have them already hit the down arrow on models and choose an XL compatible one
or if you have them already hit the down arrow on models and choose an XL compatible one
 N
N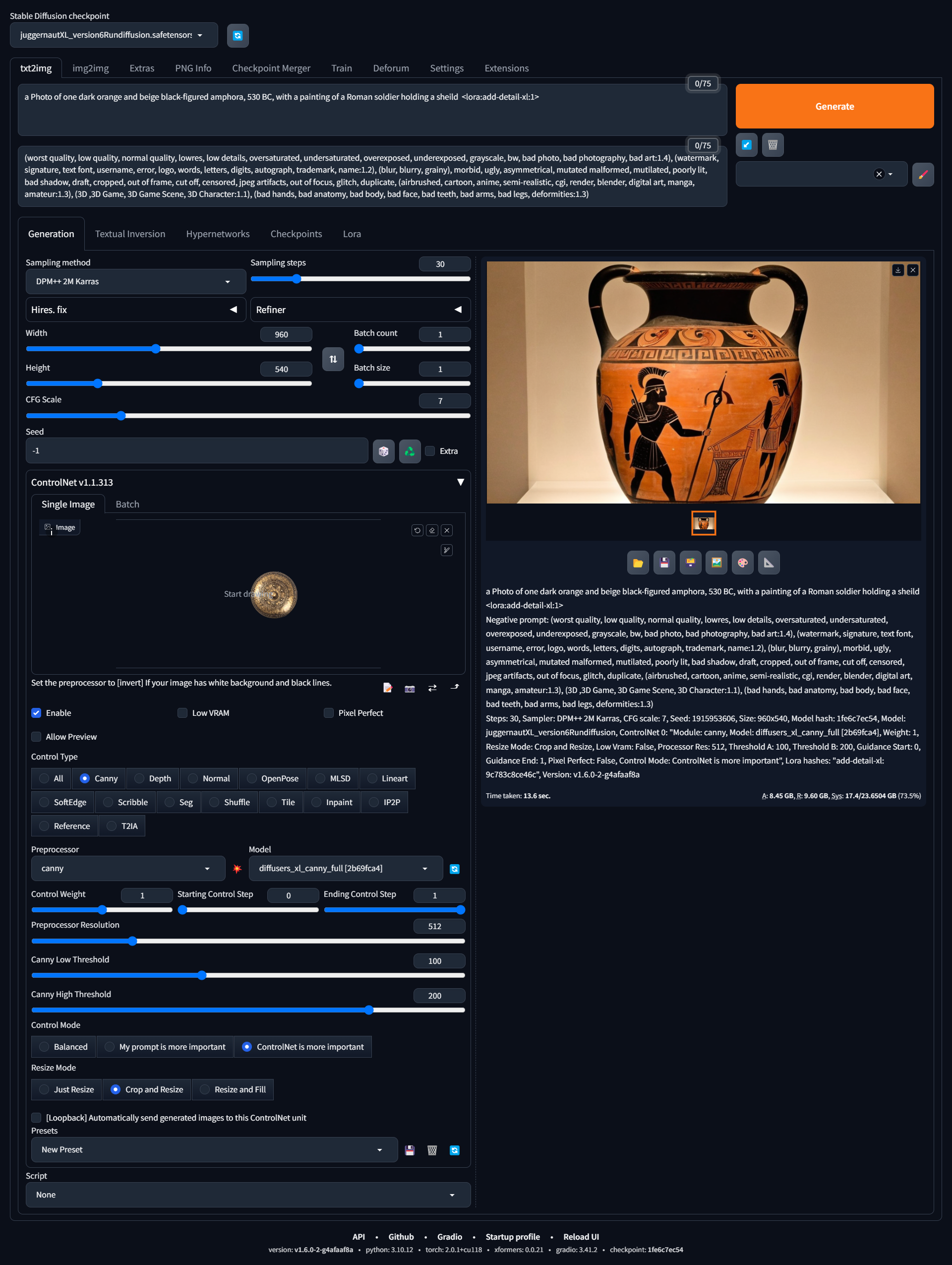 N
N E
E E
E it was kinda warm in here since it's winter, but yeah. If you're not overclocking and you have a well ventilated case, I would say don't worry about it. NN
it was kinda warm in here since it's winter, but yeah. If you're not overclocking and you have a well ventilated case, I would say don't worry about it. NN
 DD
DD FFFFFFFFFFF
FFFFFFFFFFF
 FFFF
FFFF DDD
DDD D
D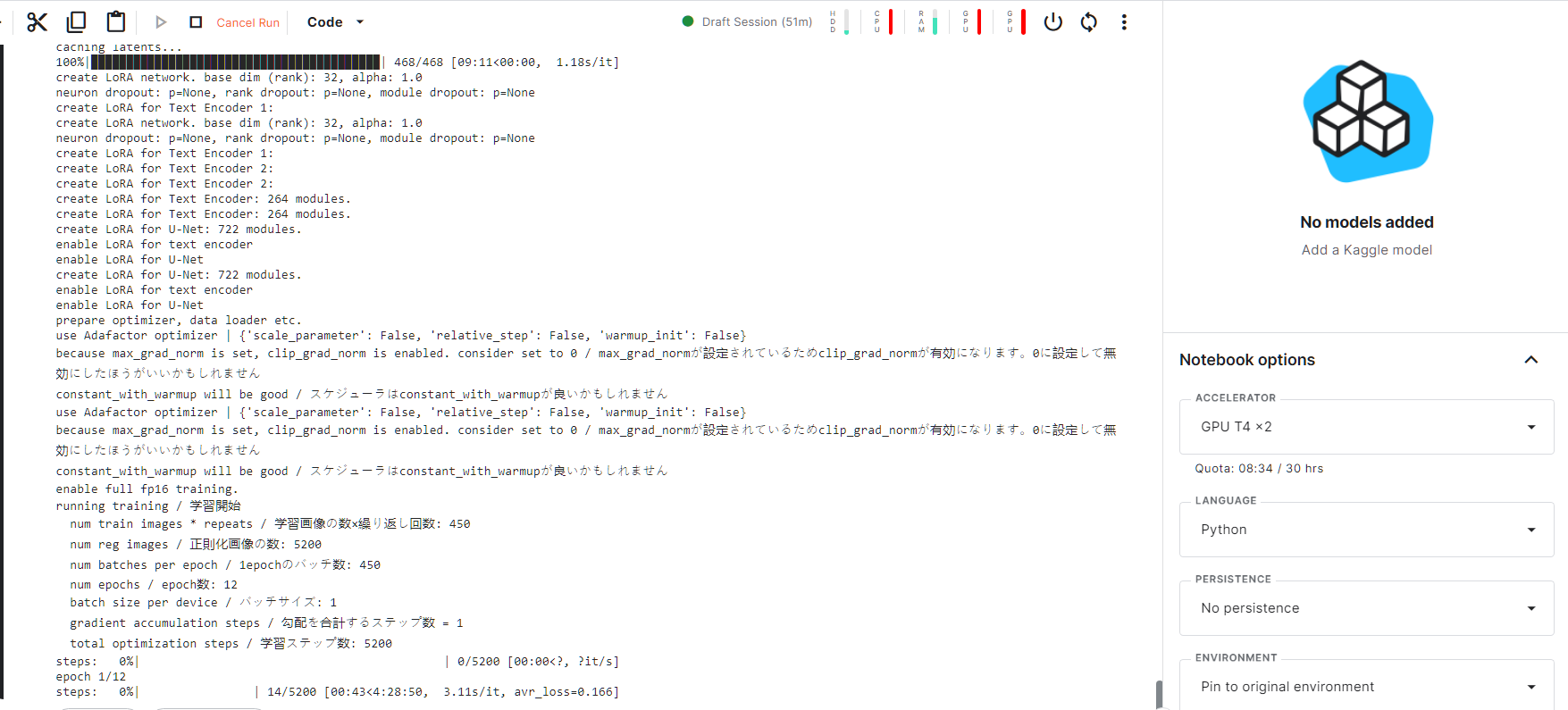 DFFDDD
DFFDDD BBDDDDD
BBDDDDD DD
DD DDD
DDD FD Is there a way to retain all the files/setups ? before i come to hit the train button ,gpu time of 1 hour is lost.. DD
FD Is there a way to retain all the files/setups ? before i come to hit the train button ,gpu time of 1 hour is lost.. DD S
S

![Digital [Starburst]](https://cdn.discordapp.com/avatars/220961909447458817/8ecbbb3132fc6e44312f3d6d2ae3df69.webp?size=16)


