it will produice only one lora right , i mean i lora set(16 epochs) of two faces..
it will produice only one lora right , i mean i lora set(16 epochs) of two faces..
 DD
DD TT
TT
 J
J MGGG
MGGG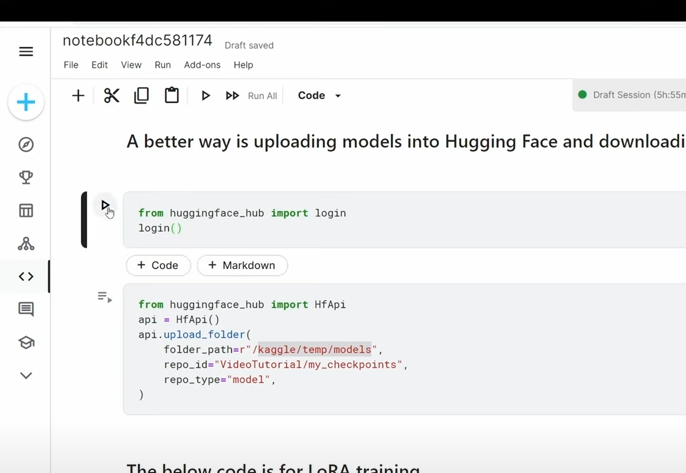 GDMDDD
GDMDDD F
F GGDDD
GGDDD FGFFM
FGFFM AMDFMF
AMDFMF
 L
L VVV
VVV B
B B
B V
V
 D
D FFFFF
FFFFF https://www.patreon.com/SECourses
https://www.patreon.com/SECourses F https://www.patreon.com/SECourses
F https://www.patreon.com/SECourses F https://www.patreon.com/SECourses
F https://www.patreon.com/SECourses F https://www.patreon.com/SECourses
F https://www.patreon.com/SECourses F https://www.patreon.com/SECourses
F https://www.patreon.com/SECourses




