Code not executed as expected
Hey Guys, I am using pythons dash package to build a website. My application is somewhat compute intensive. That is why I want to compute the results when the server starts, so that the website can use the cached results and is more responsive. But the code for the pre-computation is not being executed.
Right now the website consists of a single app.py file that contains the dash code.
At the top of my program I call:
Then comes my function definition precompute_and_save_figures() and below that all of the dash definitions for the website.
At the bottom I have my name equals main check and start the application:
Locally, on my Windows PC this works just fine and it computes all of the results I need. So I think it has something to do with the Procfile and how the Code is being executed. The Procfile looks like this:
When I deploy this I think it should at least print out the logging statements in the Deploy Logs. But that isn't the case. I also know it did not do the computation beforehand since the application is very slow.
How can I fix this? I appreciate your help!
Edit: I think I should also mention that the precompute_and_save_figures() function uses multiprocessing so it needs to be ecapsulated in a name == main block.
164 Replies
Project ID:
N/AN/A
when run with gunicorn (you should be running with gunicorn so don't change that)
__name__ will not equal __main__ so you have some minor refactoring to doI have moved the preprocessing part to another script because I am not sure how I need to call it within my app.py without causing trouble with the multiprocessing.
Now I am having a hard time figuring out how to start that script before the webserver starts.
Any Procfile commands that would be suited for this, maybe "release" or "worker" ? In the end I will need to run this preprocessing once per day. Any ideas?
if it needs to run once per day you'd need to use a python task scheduler in code
Can you explain your app a bit more? It sounds like your single app is doing two tasks. On Railway, if your app is doing multiple tasks then it should be split into two services
Especially if one part of the app should be run periodically and one part run 24/7
Some more info to the app:
As I previously said, I need to pre-compute the graphs. Calculating them in real-time is not possible because it takes a few minutes (~3 mins). The pre-computed graphs are then saved to an attached volume. Saving the graphs on a volume is cheaper than saving it in RAM or recomputing them each time they are needed, and the added latency of loading them from disk instead of RAM is fine.
Each time a user wants a specific graph it is loaded from the volume.
How can I split it into two services? Can that be done using the Procfile? Because right now all the code is in one private GitHub repository.
Do you mean I should make a second project just for the data pre-computation and use it as an API?
Is using Dockerfile recommended instead of using nixpacks?
This way I could also compute the necessary data during the build process.
Right now I configured a cron job to simply restart the project once per day. The downtime of a few minutes does not matter.
the volume is not available during the build process so you aren't saving the graphs to the volume that's for sure, you'd be saving them to the empherial container storage, but for your usecase I imagine that's perfectly fine.
my recommendation would be to split the graph rendering off into another separate railway service in the same project and have it render the graphs once during build, and then again each day on an internal in code scheduler, add a simple api to the service to return the graphs and only expose the service over the private network, then your main site would request the graphs and display them for the users
Okay, I understand.
If I'm saving the graphs to the container storage instead of the volume am I being charged for that? Like the volume costs 0.1 $ per GB does the container storage also cost?
Also if I'm doing a Docker build, does the build process cost me money?
There are two more problems with my current setup: The cron job I set up is just saying "Skipped" and sometimes when I push new code it automatically deploys, but then just says "Ready" in blue instead of "Active" in green, but when I go on the website it says Server Error. How can I fix these issues?
If I'm saving the graphs to the container storage instead of the volume am I being charged for that?nope, hobby gets 100gb of shared ephemeral container storage included for no extra cost, and i highly doubt some graphs are using anywhere near 100gb.
Also if I'm doing a Docker build, does the build process cost me money?all builds are dockerfile builds whether you use nixpacks or not, nixpacks is just generating a dockerfile for you automatically, the build process is free.
There are two more problems with my current setup: The cron job I set up is just saying "Skipped" and sometimes when I push new code it automatically deploys, but then just says "Ready" in blue instead of "Active" in green, but when I go on the website it says Server Error. How can I fix these issues?thats not an issue with railway, cron jobs are not meant for what you are using them for, cron jobs are meant for code that does one thing and then exits after theyve done the thing, your service is a long lived service, you dont want railways cron for anything youre doing, you want to do what i said above
100GB is plenty for my 1MB plotly graphs.
Good to know.
Oh I see. I will try to implement the changes you suggested. Thank you so much 🙂
no problem!
One thing that comes to mind.
Im using environment variables to set what graphs I want to generate and are available. I guess they don't get updated once the Docker container is started?
you would need to redeploy for the new variables to be available
I see
Would it be possible to use a cron job or a service with schedule to redeploy other services within the project?
absolutely, this won't care if your deployment is already running https://railway.app/template/fwH-l3
but please, before you go deploying that, tell me your usecase because I don't think that is the best option
I would just redeploy my main service each day and update the graphs with it
Also is there anywhere a dashboard on website usage or do I have to implement that myself?
Like how many users there were on a day/week/month
as I've previously mentioned I strongly think you should use an in code scheduler
that's something you need to implement yourself
You said the deployments are free. So why not use the docker build process to compute for 2 minutes and save that money on my side?
Never mind. If I can calculate correctly that's only a few cents per month.
that's far from the optional solution
In another help thread you mentioned that one can download the volume data via a script? How exactly would that work?
all volume access has to be done by the service the volume is attached to
I still don't understand how I am supposed to download it.
Do I need to create a download page on my website?
yes you would, but first what kind of data do you want to get off?
The graphs which are stored in json format
are you even storing them on the volume? from your previous messages you were only storing them in the container storage and not a volume
Yes because I didn't know how. I will first need to implement your suggestion. Then I can also mark this thread as solved. But I don't have that much time until next weekend
yep separate micro service to generate and serve the graphs and an in code scheduler to re-generate the graphs without re-deploying the service
Wait, do I use the same repository for this? Will the micro service just be in its own directory with its own Procfile? And then connect the volume to the micro-service
yes you could use the same repo with a folder named "graph-service" in it that hosts the code for this graph generation service, then deploy another railway service into your project and set the root directory in the service settings then railway will deploy from that folder in your repo
and I genuinely don't see why you need a volume, just use the container storage
The data is valuable. Otherwise I need to pay for a service that provides historical data.
I can reuse the data I save on the volume for further graphs
true true, I thought you didn't care about keeping the data around considering how you currently are re-generating on every deploy
Yea right now im just testing. But keeping the data for further graphs could be a very nice feature of my website
sounds good
Would the following project setup work if I set the root directories correctly?
The django app would be 1 service and the microservice the other service in my project.
The microservice would send the graphs from the volume to the django app and would save new files to the volume every 24 hours with the help of the scheduler.
The microservice however needs "my_python_package" for computing the graphs.
looks perfect, you would just need to integrate
my_python_package into microserviceCan I also move the code from microservice and my_python_package into my_project. Then set the root directory to "/" for the microservice.
And for the django app service I set the root directory to "/django_app/" ?
not ideal, you want to keep the structure you have shown, putting stuff in the root directory is not ideal
Or will the microservice then contain all the files of my django app as well?
Okay thank you 👍
Do I pay for communication between two services in the same project?
you wont as long as you use the private network to do all communication
Is there an example on how to do that?
Like for the microservice. Lets say im using fastapi. What address do I use? Just 0.0.0.0?
use
::
here is a guide with everything you could need and more https://docs.railway.app/guides/private-networkingAh nice. Thank you 😄
Do I have to merge the requirements from my python package and the microservice and put them into the directory microservice?
Or will nixpacks use all found requirements.txt ?
nixpacks will only install the packages from a single requirements.txt found in the set directory
Finally have some time again.
I got two services running as described above.
1st one is the django app, 2nd one is the api that manages the files. The second service was also supposed to have a scheduler that runs every 24 hours.
However, I am unsure how to do that. This Procfile setup doesn't seem to work:
The main.py runs once on startup and then sets the scheduler.
But the process is always killed mid way.
My script is using multiprocessing. Is this why its killed? Or is the Procfile setup wrong?
I removed the multiprocessing. It seems to work now. Can I simply enable it when I use the Pro version of railway?
multiprocessing shouldn’t be the issue. my theory is that the second script ending is sending a sigkill, causing the container to be killed off. What’s the purpose of the second script?
as in, can it be moved to a separate service and set up as a proper cron job?
since your first command is django, I’m assuming it’s some kind of migration script
Brody said this would work so I tried it haha
My 2nd service is just providing charts to the django service via an API. I attached a volume to this 2nd service. The main.py initializes the scheduler that runs a script to compute the charts. the gunicorn starts the API that simply gets the saved charts from the volume
I would split the services further. I don’t see a reason why your main.py and gunicorn have to be in the same service.
Just wanted to avoid more inter-process communication
that’s not an issue so long as you use the private urls. You will not be charged for networking
Okay I guess im making another service.
How would I send the computed charts from the new 3rd service to the 2nd service without an API?
I need to send the data because I want to save the charts on a volume that is attached to service 2 / the api
ah I see. could you add an endpoint to your api service that receives the data? that would be the most efficient way imo
I see now why you were trying to start them in the same service
one last thing to try before creating the new service, flip around the start commands
eg: do gunicorn … && main.py rather than the other way around. Perhaps having the long-running program first will work?
okay thanks
One more thing.
Right now I set an env variable API_PORT manually to tell my django app where the API is and I overwrite the PORT env variable in the API service to start it at this port.
Can I do this any simpler?
No, that sounds right. Hardcoding the url would be the simpler way
which shouldn’t be a problem since you’re hardcoding the PORT already
Okay
I changed the order of the commands. The API is running but it doesnt seem to run the python script.
Django service:
requests.exceptions.ConnectionError: HTTPConnectionPool(host='api.railway.internal', port=7777): Max retries exceeded with url: /read_data?var1=value1&var2=value2(Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f1221c10c40>: Failed to establish a new connection: [Errno 111] Connection refused'))
/read_data is my api endpoint
API service: Listening at: http://0.0.0.0:7777 (10)
Do I have the wrong url?
seems like it. can I see your code?
That's basically all the code for the request in my views.py in the django service
The api looks like this and the Procfile command you already know.
The link api.railway.internal is straightup copied from the private networking tab in railway.
That looks fine to me, are you following the same method to connect to your API from your other service?
What do you mean?
Nevermind, please send your app that runs on a schedule. I will need to see your code to help you further
I dont think the scheduled app has anything to do with that.
Is your scheduled app not attempting to push the data it generates as I described?
Where is this error occuring
The error is happening at this line
It looks like it can't build a connection
Which service is this happening in
The django service, which is requesting a specific chart from the API service.
The django service is the one that runs on a schedule?
This is my understanding of your app atm.
Django service - Runs on a schedule and generates (?) a file that your API service needs
API service - Is an API
Other service - communicates with your API
Is this correct?
No. The microservice is the api + scheduler.

I disabled the whole scheduler thing
But that doesnt matter. It still builds no connection to the API
Was this working before all the changes you made today?
No. I only wrote the microservice today.
Got it. Back to the code that you sent above, you should not have to specify a port. Internal networking works differently to public networking. Additionally, I believe it should be https rather than http
Please make those changes and let me know if it works
like this
just removing the port and adding https ?
yes
https://docs.railway.app/guides/private-networking
I read that differently in the docs.
In that case, I'm wrong. Is the api logging the request at all?
Now im getting: requests.exceptions.ConnectionError: HTTPSConnectionPool(host='microservice.railway.internal', port=443): Max retries exceeded with url: /read_data?ticker=SPY&chart_type=open_interest (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7fa504407cd0>: Failed to establish a new connection: [Errno 111] Connection refused'))
Its just using port 443.
Nope. The API is not getting anything.
Then I'm out of ideas
@Brody when you get a sec, private networking stuff
No worries. Time to sleep for me. Thank you.
no prob
Only thing I can add to this is that it was working on my machine when I was using localhost.
no 😆
op, for when you get back online, what port is the micro service running on?
I assumed 7777 since this is what I have set the PORT variable to
Log from microservice
then the url needs to be
http://microservice.railway.internal:7777Thats what I have in my Django service that tries to use the microservice
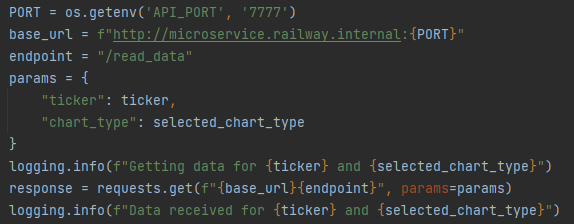
i assume API_PORT is set to 7777?
yes
and what error do you get
this one
adam was wrong in telling you to use https and port 443, please show me the new error with the code you had just shown me
Well this was with the change Adam provided. But same error happens just with port 7777
please show me the new error with the code you had just shown me
the code that uses http and port 7777 in the url
Had to put it in a txt otherwise i reach character limit
okay progress
what is the start command you currently have for the micro service?
Just this: web: gunicorn api:app
but I set the PORT variable to 7777
`
change to
web: gunicorn api:app -b [::]:$PORT
let that redeploy, then try the connection again from your django appCould you look at the multiprocessing error. Couldnt resolve it. I was guessing it was caused because I only have 2 vCPUs
will that prevent you from testing after you've made that suggested change?
i am
just did an oopsie typed in app:api not api:app
that's okay, that was my typo too
Okay microservice is now saying: [2024-01-29 10:41:08 +0000] [8] [INFO] Listening at: http://[::]:7777 (8)
And the request gets thorugh
nice
awesome
This was my original problem
I implemented it the way you said. 1 django service and a microservice for sending the chart with a scheduler.
what does main.py do
thats the scheduler
pretty sure you'd want to run that as another railway service
okay
what about the multiprocessing
any idea why it fails?
just eating too many ressources?
what error where you getting? "killed"?
yes
/bin/bash: line 1: 10 Killed python main.py
then that's very likely caused by running into your trial plan resource limits
okay thanks
upgrade to hobby and then work on splitting your scheduler off into another railway service
The request is coming through to the api but theres still an error:
Do gunicorn and fastapi not work together?
fastapi requires you run it with uvicorn or hypercorn
i see
so same command just with hypercorn?
I recommend hypercorn
web: hypercorn api:app -b [::]:$PORT ?
depends, is this the micro service?
yes
didn't you say it was previously working?
on localhost yes
but i wasnt using gunicorn
just exposing the port
your code calls the private domain, that isn't going to work locally regardless of if you are using gunicorn/uvicorn/hypercorn. but you told me it worked?
I wasn't using exactly this code
alright, moving on, your micro service is fastapi, correct?
I meant that the code is working. But the networking in between not.
yes
i installed hypercorn added it to requirements and changed the procfile to this web: hypercorn api:app -b [::]:$PORT
hypercorn api:app --bind [::]:$PORTits --bind
yeah
okay this time, test it on railway
I am testing it on railway.
its working
thank you
no problem
I rewrote a bunch. Now I have a third service. I assume the procfile looks like this:
worker: python scheduled_task.py
and then set the cron job on the railway website or put it somehow in the Procfile?
by my guess, you're using an in code scheduler, therefore you don't use railways cron scheduler.
but to further answer this question, have you split the scheduler code off into a completely separate repo?
no just a different directory
with the root set to this dir
okay cool, then a Procfile with
web: <your start command> will do just finei will try thanks
remember, you're using an in code scheduler, you don't want to use railways cron scheduler
Why do I need "web:" and not worker?
let me go check if worker is even supported, Procfile's are a heroku thing after all
ideally you would be using railway.json
I will just try both 😛
nope
Is there a "Best Practices" documentation for railway?
yeah, you ask me
 ❤️
❤️while somewhat of a joke, it's kinda true, there is no docs on the most efficient / correct way to use railway
this results in a lot of people's projects just barely working because they aren't using railway to its fullest ability
just use web in your Procfile, I can't see any mention of worker, so likely won't work
What else do you recommend except railway.json, are Dockerfiles any good?
I use dockerfiles for all my personal projects, but if you don't have a reason to use it, then stick to nixpacks
It happened like 2 or 3 times now that I get logged out of railway and get a 404. When I try to log back in with github I get:
Just hang tight, issue with Railway
i see, how often does that happen?
Usually not often
Just having issues handling high traffic
never had this happen to me before, rest assured its extremely rare
you aren't actually logged out, it's the front-end not being able to call the backend to check if you're authenticated, so no need to try to log back in
Good to know
incident has been called, keep an eye on #🚨|incidents for updates
I saw you also have an API and CLI for railway. Is this still usable while this error occurs on the website?
the cli uses the same api system as the dashboard does, so no the cli wouldn't be usable during an ongoing issue with the api
thats unfortunate
what ya need the cli for right now? just curious
Nothing I just thought it could be used as an alternative to deploy and check the logs and stuff
ah, gotcha
Its me again. For E-Mail authentication, do I just provide the login data as an environment variable for the service and trust you that you dont read that ?
wdym "trust you that you dont read that ?"
Well can't mods/admins read how my application is build?
1. im a discord mod, i cant even see the name of your project unless you showed me
2. your service variables are encrypted
yeah i didnt mean the discord mods
good to know