© 2026 Hedgehog Software, LLC
Twitter
GitHub
Discord
System
Light
Dark
More
Communities
Docs
About
Terms
Privacy
Search
Star
Feedback
Setup for Free
DB loads insanely slow - Neon
N
Neon
•
3y ago
•
49 replies
ill-bronze
DB loads insanely slow
Hello
, we
’re using wundergraph
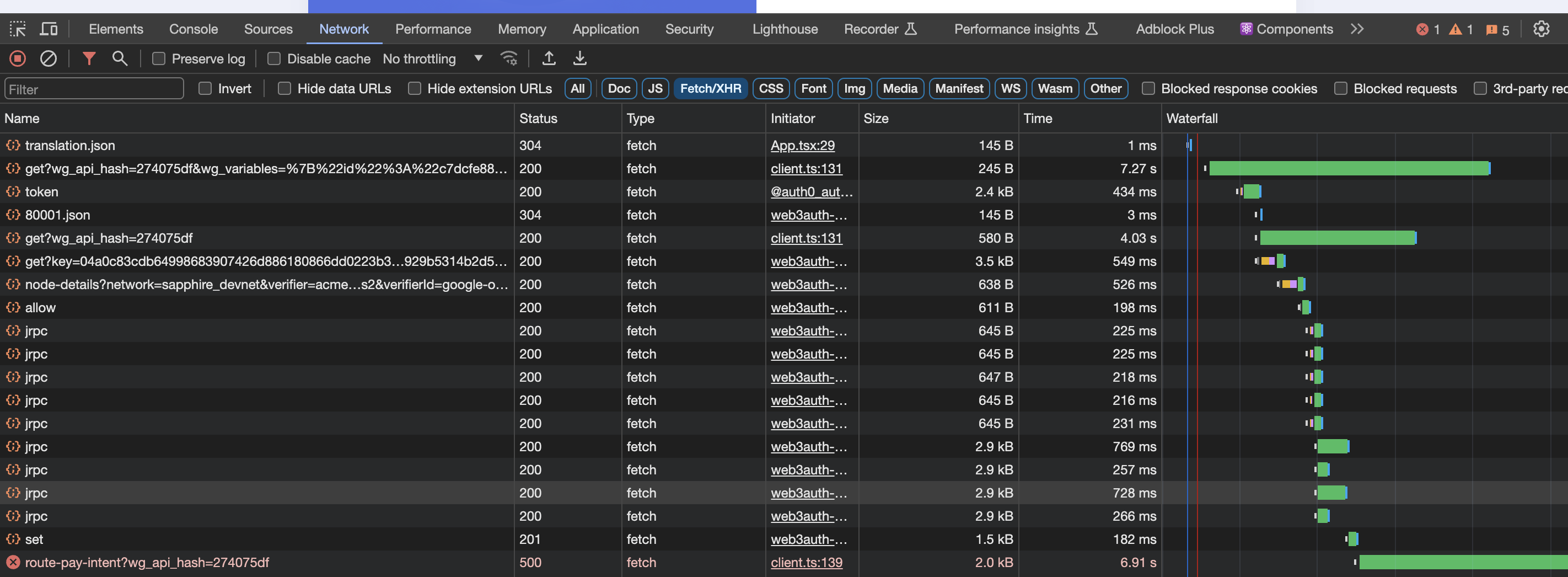
+ neon and noticing load times of up to 7 seconds for a simple query
. We are on the free plan as we
’re testing things out but is it really supposed to be this slow
?
Neon
Join
The official Neon Database Discord
10,545
Members
View on Discord
Resources
ModelContextProtocol
ModelContextProtocol
MCP Server
Similar Threads
Was this page helpful?
Yes
No
Recent Announcements
Similar Threads
DB speed is slow
N
Neon / ❓|questions-and-answers
7mo ago
Cloudflare worker slow DB connection and termination
N
Neon / ❓|questions-and-answers
4w ago
DB Suspended?
N
Neon / ❓|questions-and-answers
10mo ago
DB error
N
Neon / ❓|questions-and-answers
11mo ago