I am interested in GANs for true deep fake training but i still didnt have time to look at that yet
I am interested in GANs for true deep fake training but i still didnt have time to look at that yet
 F
F AF
AF![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=40) D
D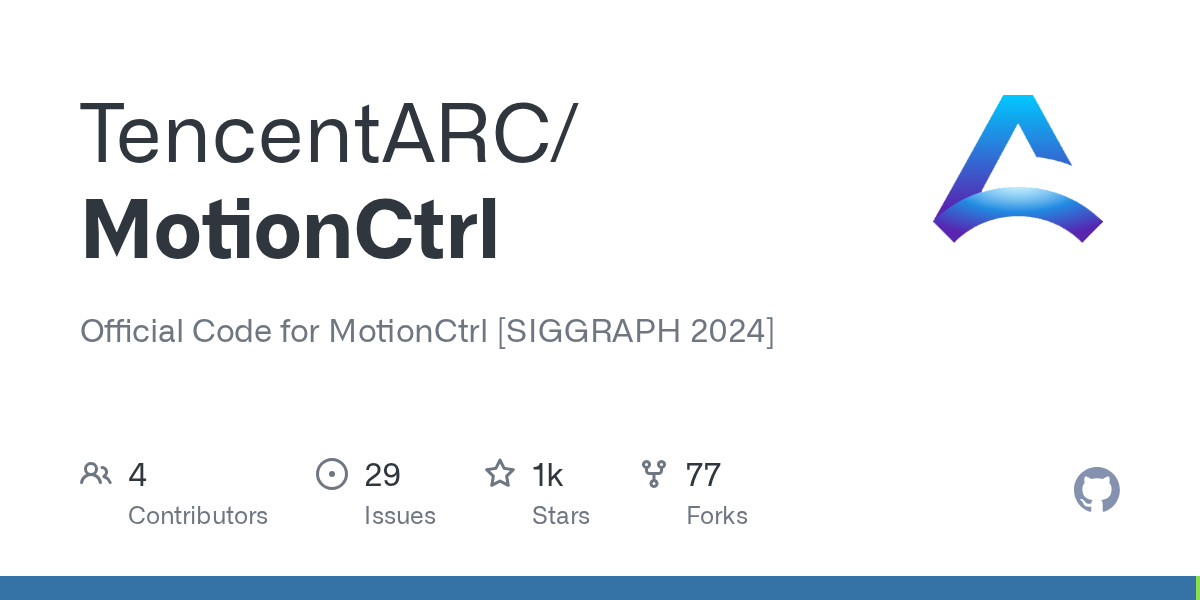 F
F A
A DF
DF D
D RFFFFRRF
RFFFFRRF WADFAF
WADFAF D
D DD
DD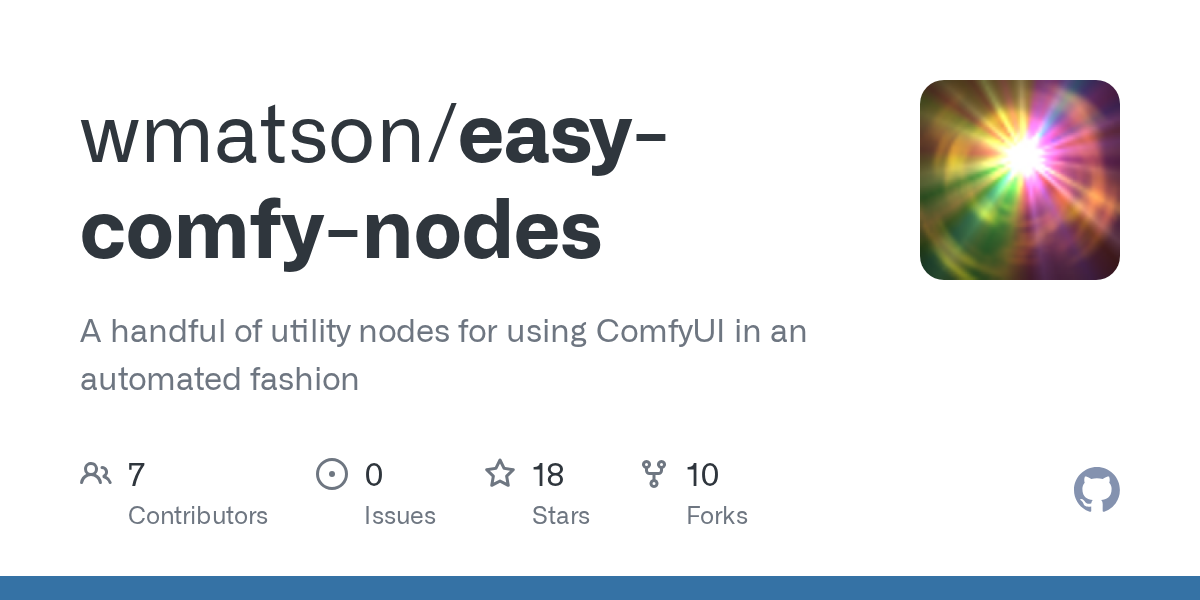 D
D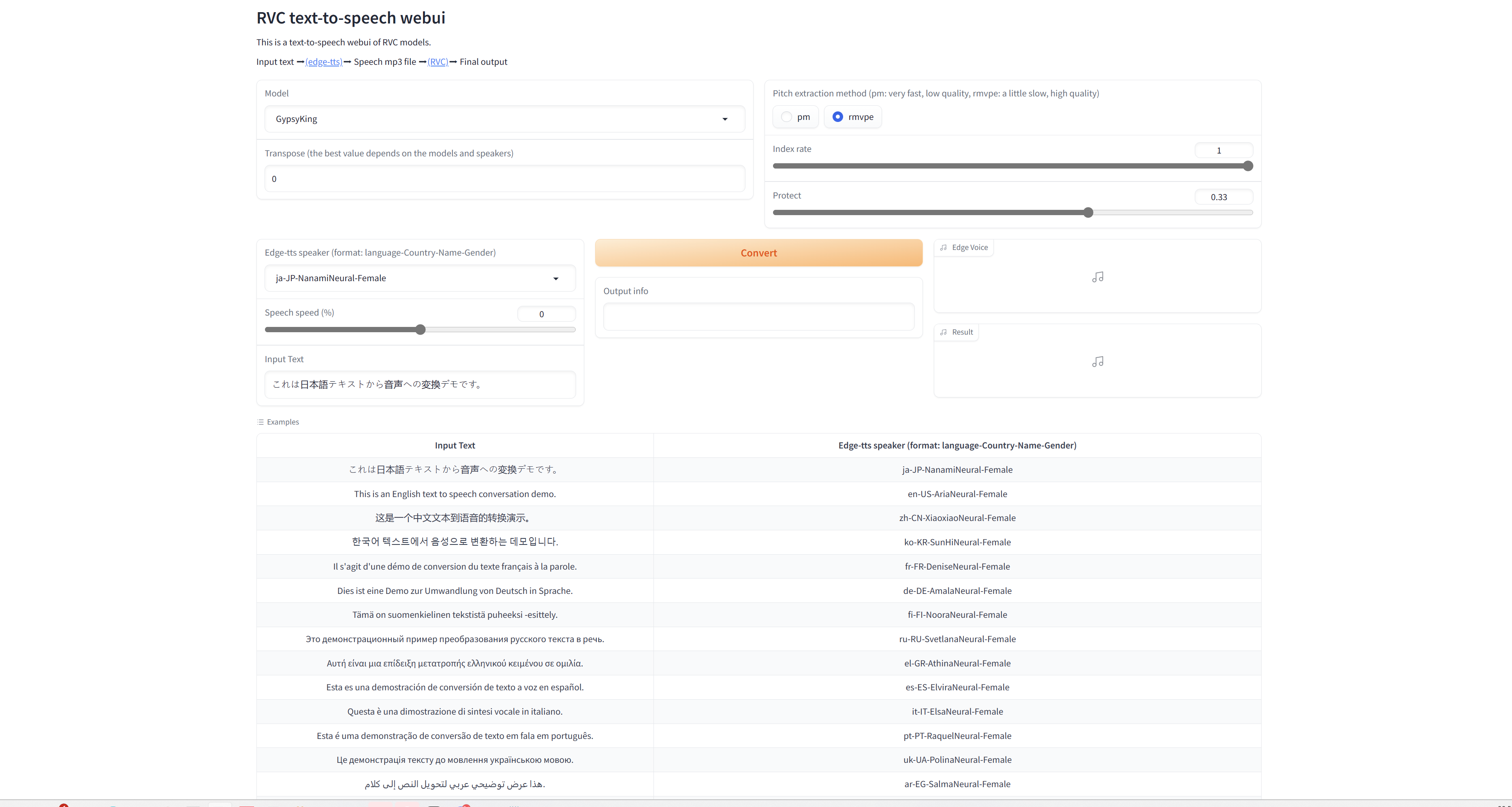 FD
FD DDFD
DDFD M
M FFFFAFFF
FFFFAFFF U
U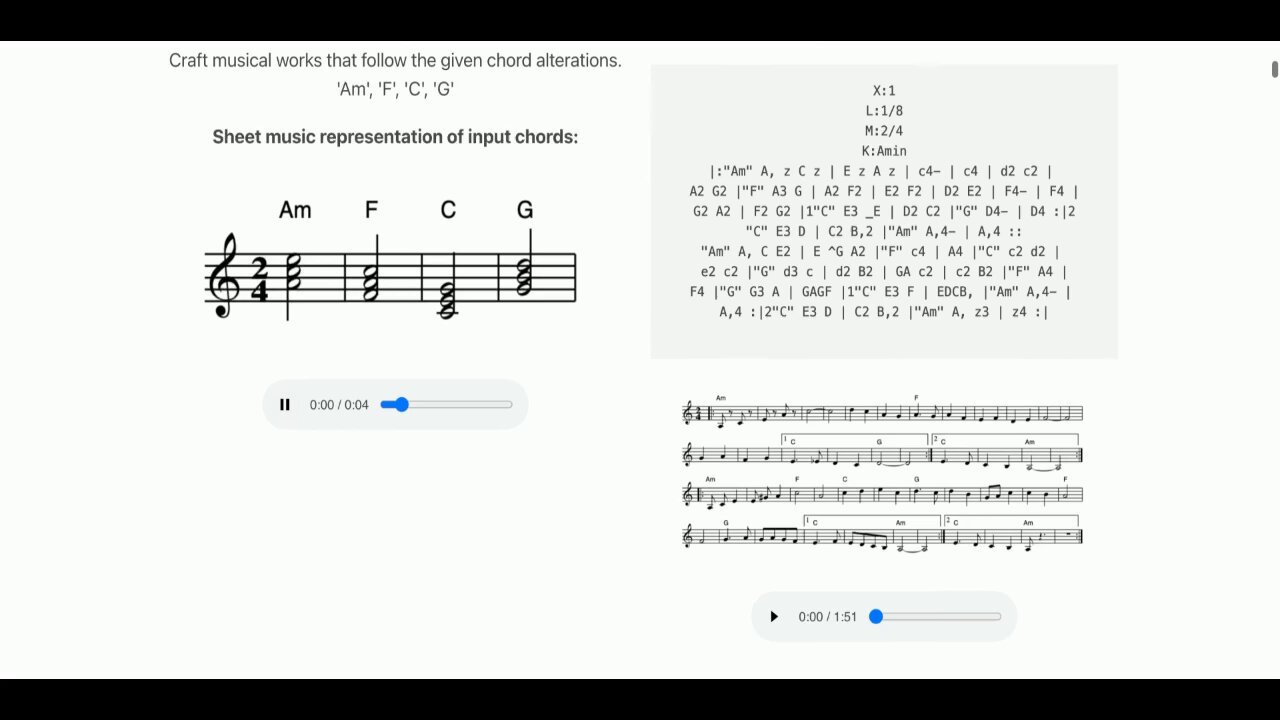

2/27/24, 4:51 AM
UFU

 Generation for multi-aspect ratios
Generation for multi-aspect ratios Improved human-centric fine detail.
Improved human-centric fine detail.

2/27/24, 7:20 PM
UUFF
![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=16)



