Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
@Dr. Furkan Gözükara Forge has a new tab that's called spaces, that install separately gradio extensions, maybe you can put any oneclick installer to promote you
T5 FP16 separate download and dev version from darkwood download? I'm sorry I didn't follow sources much and I'm confused in them, there are many different models everywhere, I'll be especially grateful if you give me sources from where to download or tutor
The old Automatic1111’s user interface of VAE selection is not powerful enough for modern models . Forge make minor modifications so that the UI is as close as possible to A1111 but also meet the d...
I've tried Florence2 for a training and it went good, was setting up another Lora today but this time I actually read the captions first and noticed Florence got some key details very wrong, which could possibly mess up the Lora a bit so I dunno. I wonder if Llava is better or there's a free local Captioning tool that is a lot more consistent
I'm doing some testing training flux on kohya but I'm having a bleeding problem, I'm training pictures of myself as a kid and as and adult and a friend, so the captions are "myname man" "myname boy" "myfriendname man" and the concepts bleed, this problem doesn't happen training sdxl models, there is no bleeding. maybe the problem is because I'm not training the text encoder?
Another question: the CLIP models, such as clip_l, are stored in separate files from the base model. If I use a concept that doesn’t exist in CLIP, such as ohwx or another non-existent word, would it still work during inference if it's not part of the model because the model was not trained? Additionally, if I train clip_l, would it be saved as a separate file? Currently, the text encoders are not in the same safetensors as the base model
The doubt arises because the text encoder is in a different file, and if I train it, would Koha save it as a separate file? In that case, should I also use my custom clip_l for inference? Ideally, the text encoders should be included in the same SafeTensor file, as happens in SDXL
Ye this is only lora but I think fine tuning has better optimizations we will see. Also I asked kohya since there is half model training but still uses 18 gb gpu
 F
F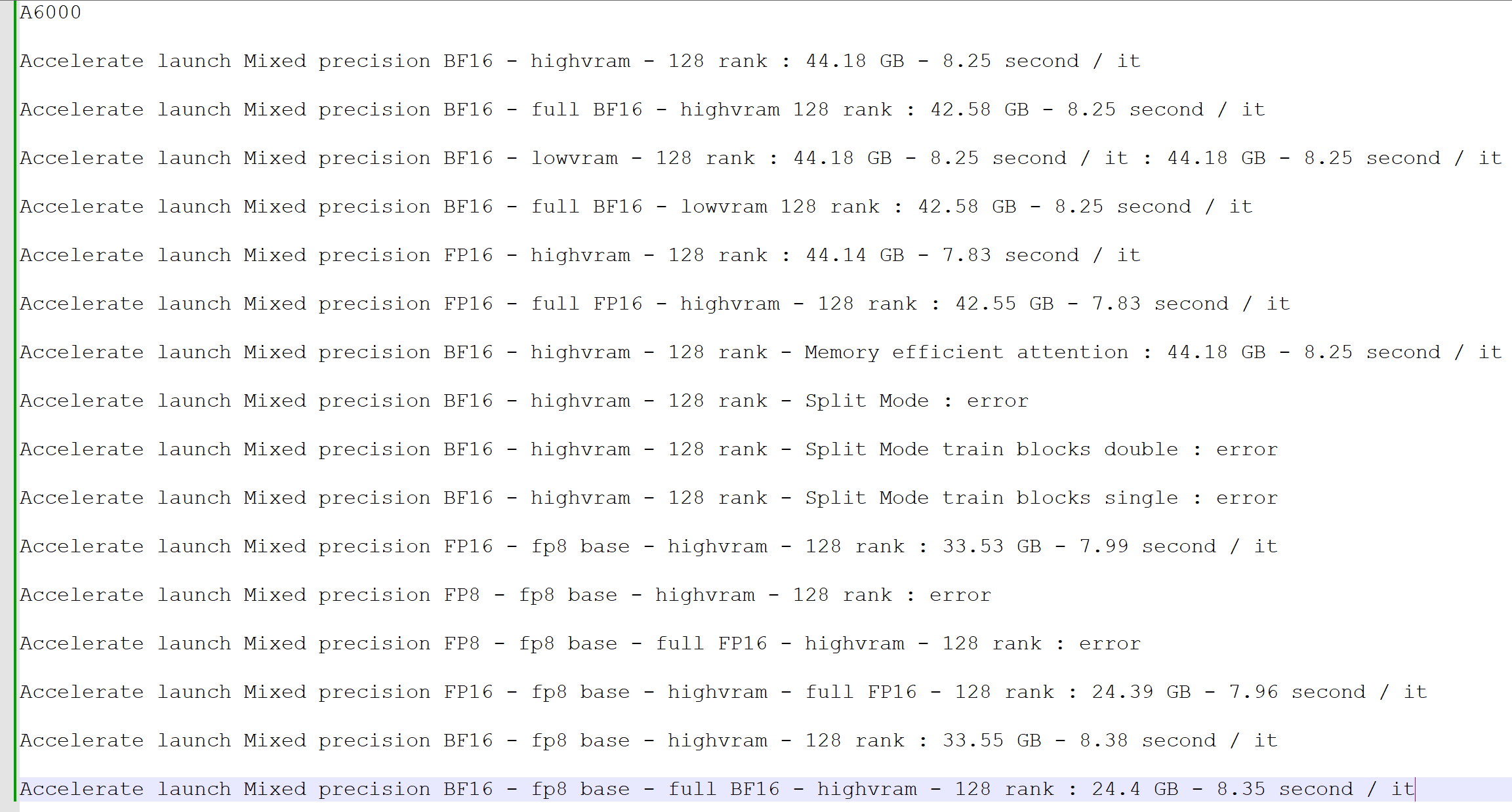
 I
I
 N
N J
J

 Y
Y
 �
�
 D
D






