Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
Among the widely used parameter-efficient fine-tuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full fine-tuning (FT). In this work, we first introduce a novel weight decomposition analysis t...
Get more from SECourses: Tutorials, Guides, Resources, Training, FLUX, MidJourney, Voice Clone, TTS, ChatGPT, GPT, LLM, Scripts by Furkan Gözü on Patreon
Replace SD3Tokenizer with the original CLIP-L/G/T5 tokenizers. Extend the max token length to 256 for T5XXL. Refactor caching for latents. Refactor caching for Text Encoder outputs Extract arch...
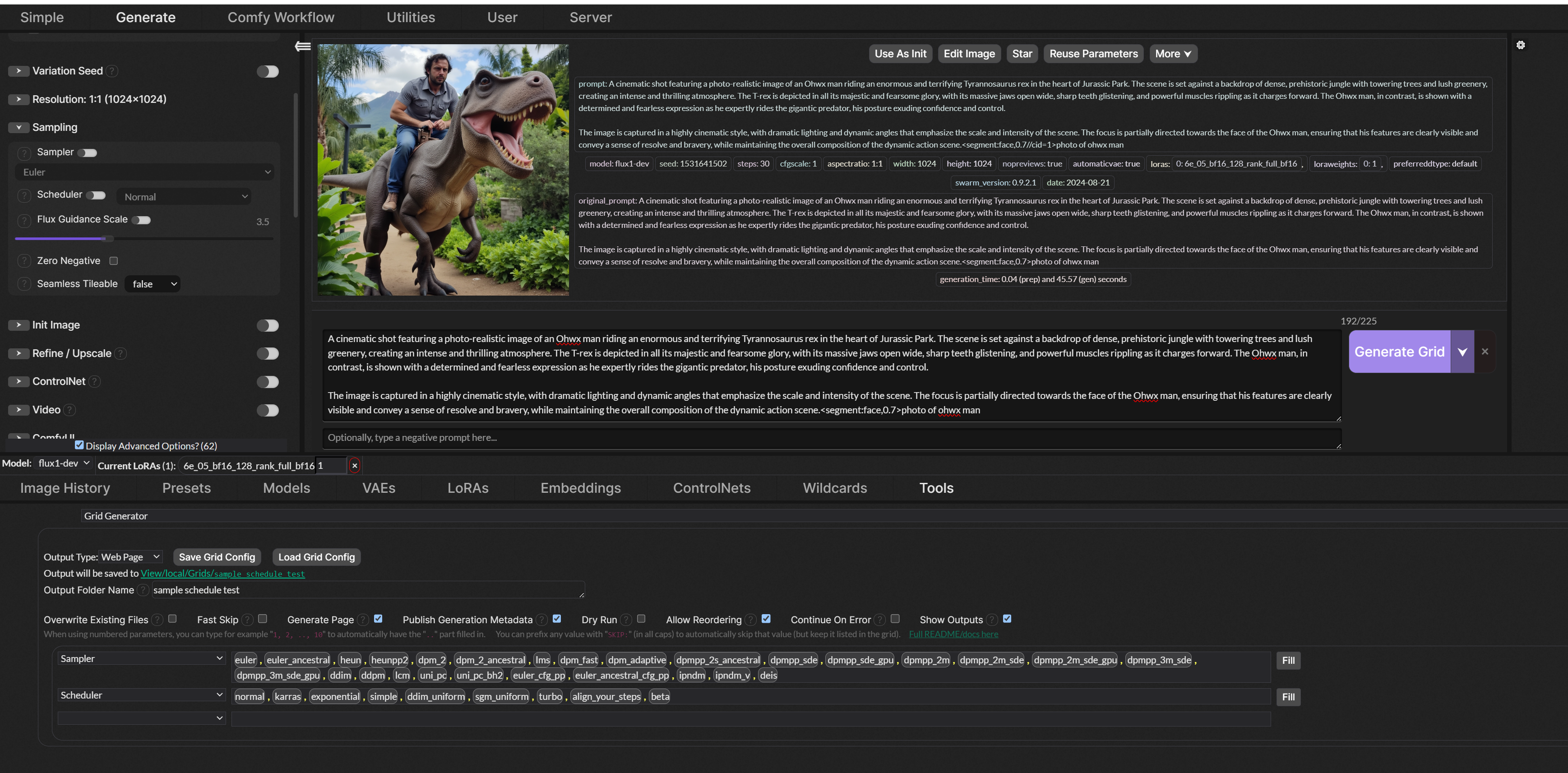
oh ok yeah that makes sense now. I just figured probably one of your training images didn't have the glasses described in the caption, but then again the frames of the glasses aren't super bold and noticeable from a distance so that could be another reason
does anyone know if normal alternating via prompt such as [x|y] where it alternates between x and y each step is still usable in a natural language style model like flux?
 D
D C
C F
F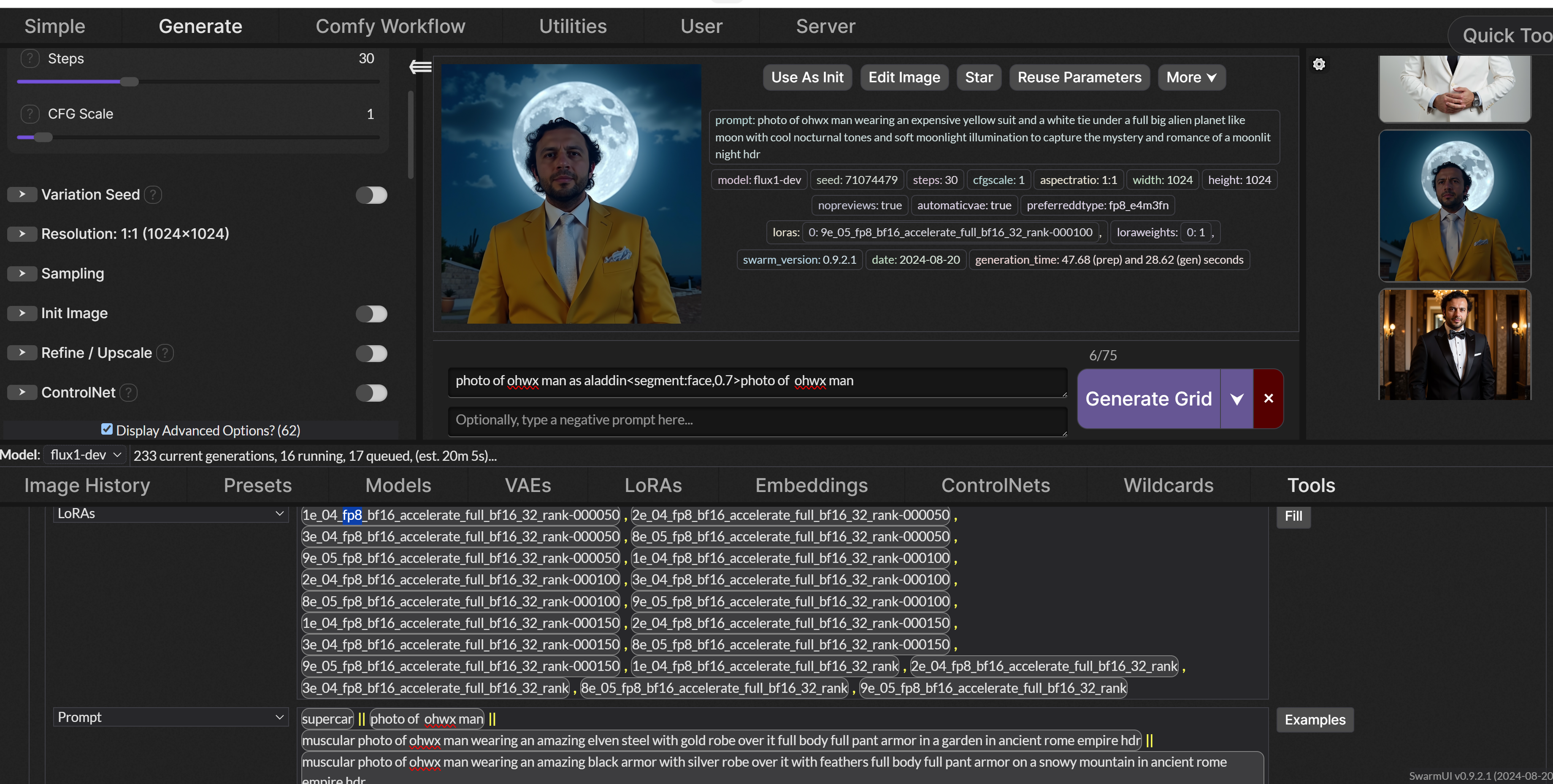

 C
C

![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=40) D
D
 S
S
 �
�

 D
D![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=16)




