Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
It might work better for style, cuz it really describes the style better than Florence2 SD3 Caption, but, I think, if you are dealing with character or a concept, Florence2 is WAAY faster, like, I captioned 70 images with it in like 3 minutes
Get more from SECourses: Tutorials, Guides, Resources, Training, FLUX, MidJourney, Voice Clone, TTS, ChatGPT, GPT, LLM, Scripts by Furkan Gözü on Patreon
Get more from SECourses: Tutorials, Guides, Resources, Training, FLUX, MidJourney, Voice Clone, TTS, ChatGPT, GPT, LLM, Scripts by Furkan Gözü on Patreon
@Furkan Gözükara SECourses when you say you did some training on 1536x1536. this means you resized your training images to this resolution, yes? did you also modify "max_resolution": "1024,1024", in the config, or just let kohya do bucketing?
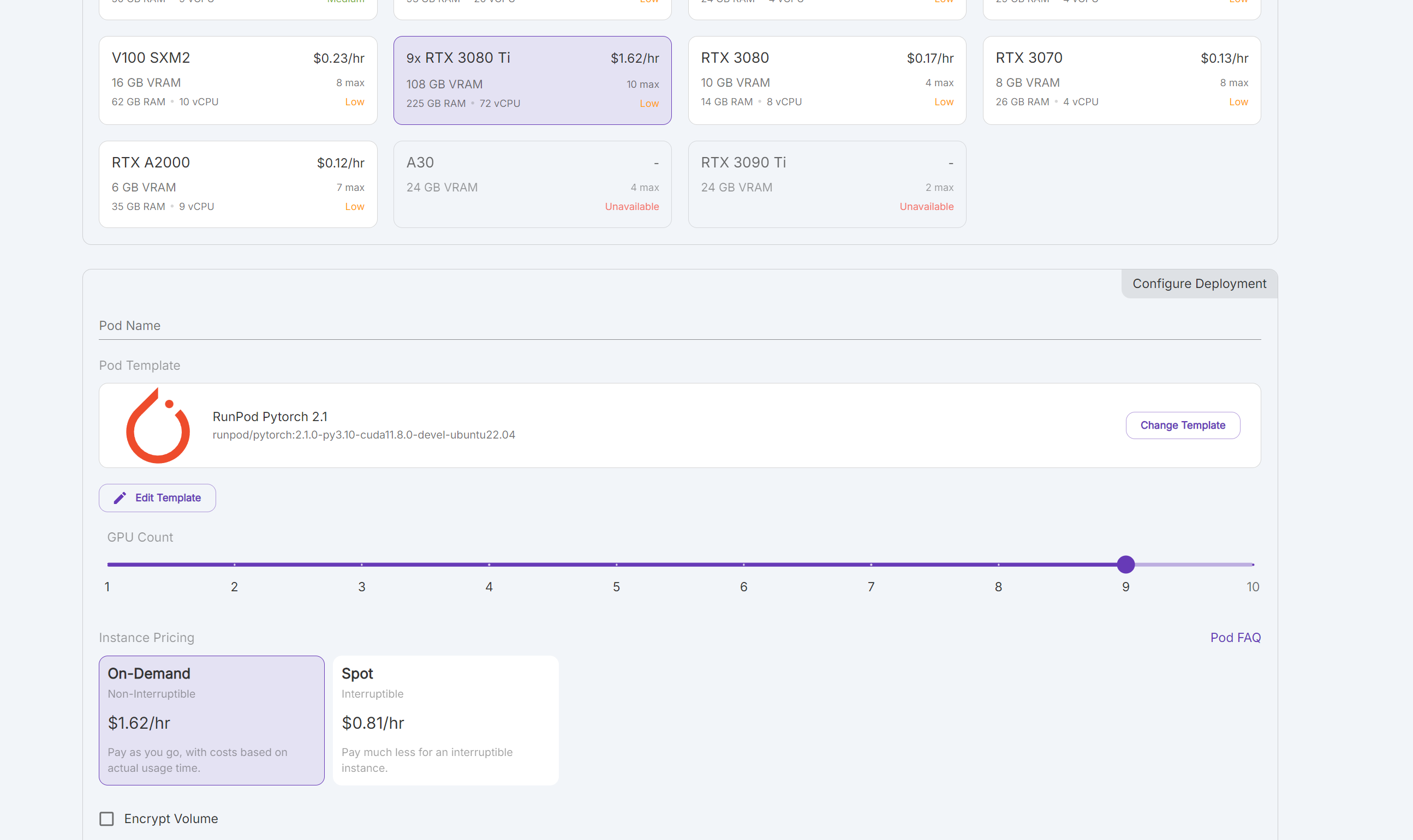
nice - 90% of mine can be downscaled from raw to 1536 so i was going to try... increasing max resolution to 1536 and applying t5 attention max will still fit in 24GB?
 F
F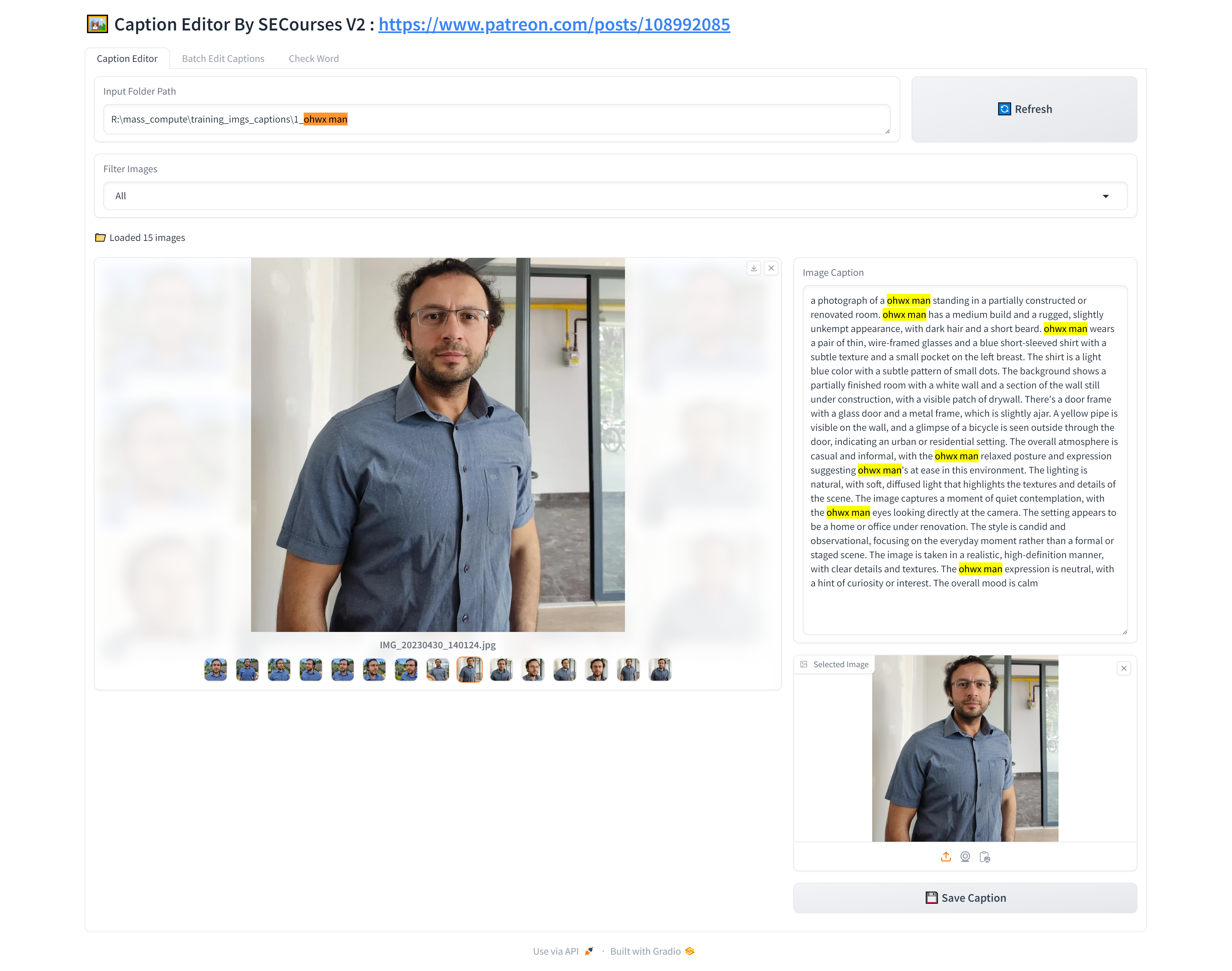
 J
J D
D
 S
S
 H
H S
S M
M N
N






