Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
hahah well i just mean in a basic sense, like if i do 50% + 50% of one model and then merge that with another at 50% does it equal out to be 25% +25% +50% or what lol
or am i actually losing any data or does other data just cover it up to where i can bring other data forward by adjusting weights of tokens and what not
Thanks to your guides and configs I fine tuned an SDXL model with pics of my dog and of me using OneTrainer (will post some results later). The thing I'm struggling with is extracting a Lora from the model. I was able to do this with kohya_ss but the Lora comes out at almost 2Gb. I was wondering am I using wrong settings in kohya_ss or should I extract the Lora and then run the reduce Lora option in kohya_ss?
Yeah, using the Kohya gui. Main reason I'd like to reduce the size is I wanted to share it + my hard drive was getting full (I really should buy a bigger drive). I played a bit with the resize option in the gui. Dropped it to a rank of 64 and the final size was about 380MB without noticeable quality loss. I was mainly curious if there was a recommend way to get smaller Loras.
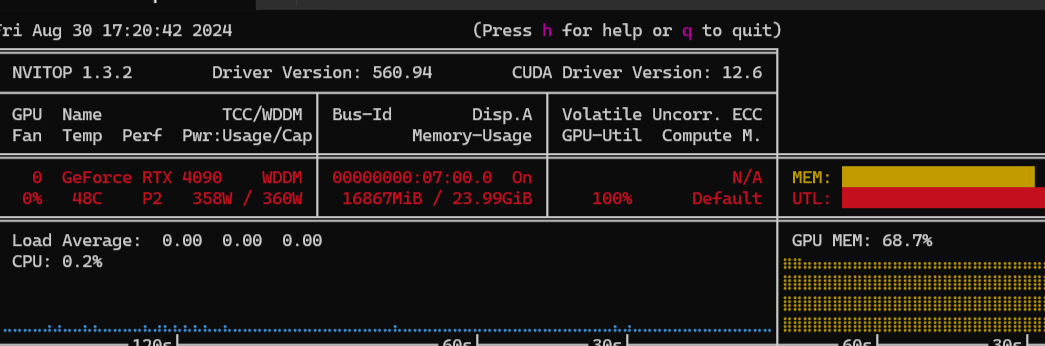
Dr Furkan, i hope evertyting is ok, im traying to make my firt lora model in flux, i have a 4070 super ti 16 gigas vram this speed is good? if i install the torcho 2.5 could increase speed? im use the rank 5 setting
not sure what you two mean. I have used a character lora with flux recently. trigger word (which was the name of the person) was necessary. using the lora without it already did something, but not everything
 F
F S
S
 S
S it averages neural network weights and you expect to work
it averages neural network weights and you expect to work D
D
 A
A N
N S
S
 P
P D
D





