Do you happen to know why there's little to no improvement when using Torch 2.5? Said it a couple of
Do you happen to know why there's little to no improvement when using Torch 2.5? Said it a couple of messages ago.
 U
U D
D N
N







 DUUNDNDN
DUUNDNDN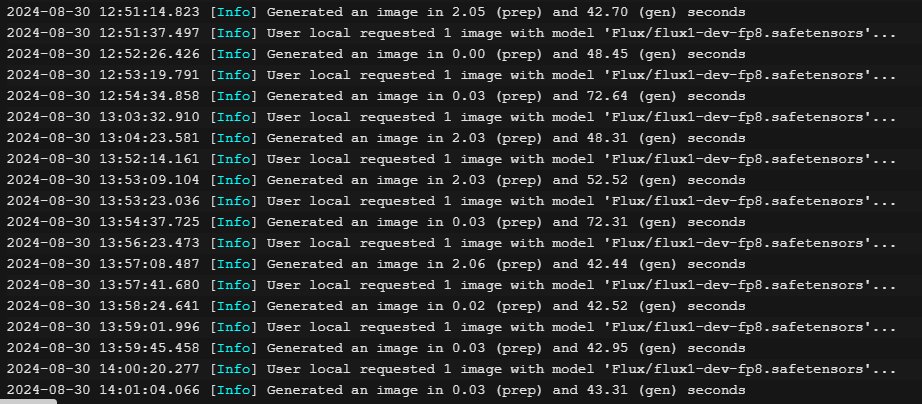 ND
ND





 N
N !! thanks for sharing - how many pics in your training dataset and how many training steps?DDDU
!! thanks for sharing - how many pics in your training dataset and how many training steps?DDDU
 D
D JJD
JJD D
D �
� ��
��This LoRA was trained on two layers single_transformer_blocks.7.proj_out and single_transformer_blocks.20.proj_out
It is possible to train on blocks.7.proj_outlayer only if you don't want the dataset style transfer, the size depending on the dim can be below 4.5mb (bf16), the model is powerful enough to offer advantages such as single layer training, so let's do that.
A Flux LoRA with 99% face likeness with great flexibility can be as small as 580kb (single layer, dim 16)
NN� МN
МN M
M FFFFFFFFFF
FFFFFFFFFF VV
VVallow_pickle=False to raise an error instead."V DDDD
DDDDallow_pickle=False





