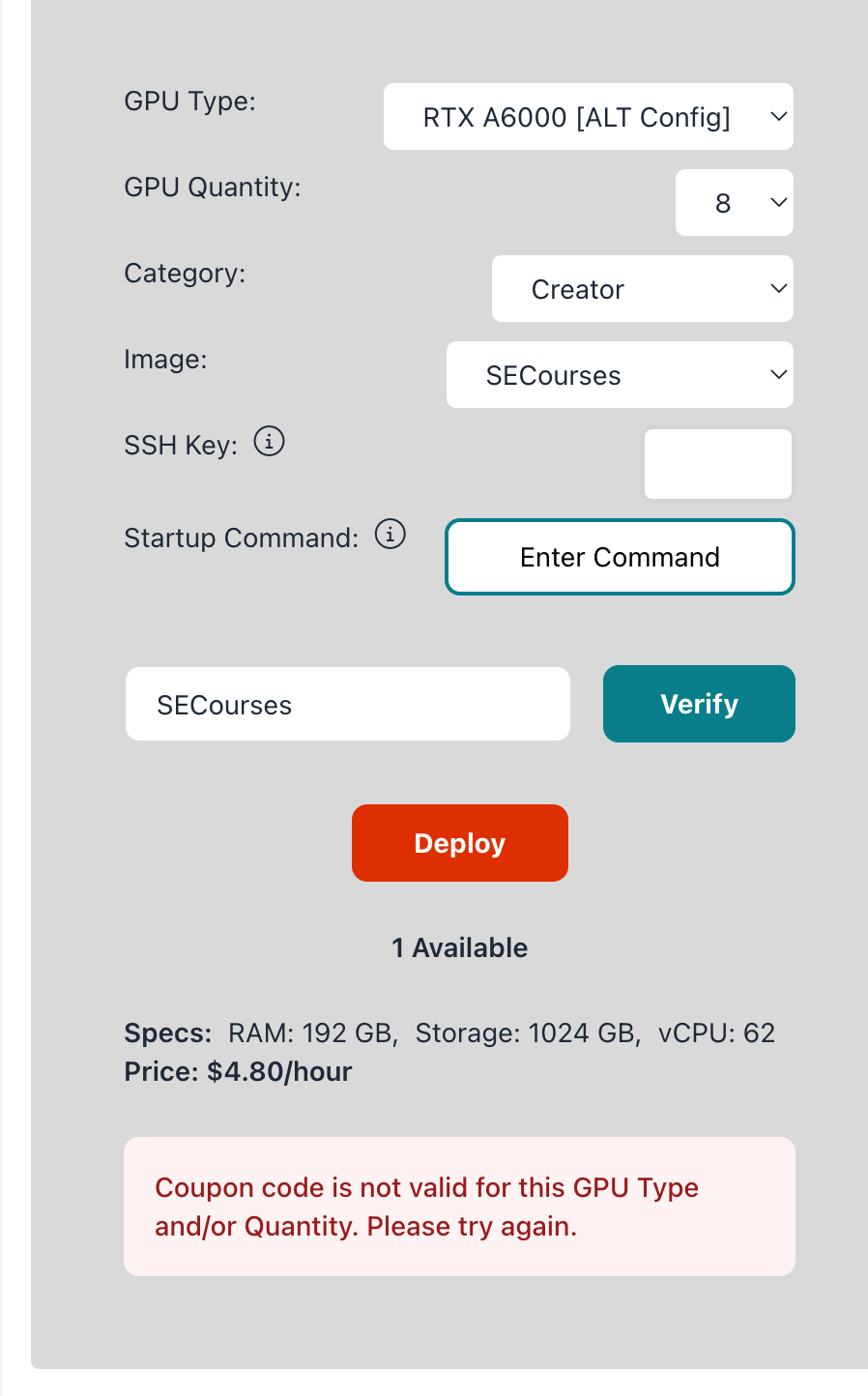
Coupon code is not valid for this GPU Type and/or Quantity. Please try again.
Coupon code is not valid for this GPU Type and/or Quantity. Please try again.
 FFFF
FFFF
 F
F D
D DFFFFFF
DFFFFFF you can use if you wish DFD
you can use if you wish DFD FFDD
FFDD
 LLFFFF
LLFFFF
 DDD
DDD D
D FFFDFFDD
FFFDFFDD D
D D
D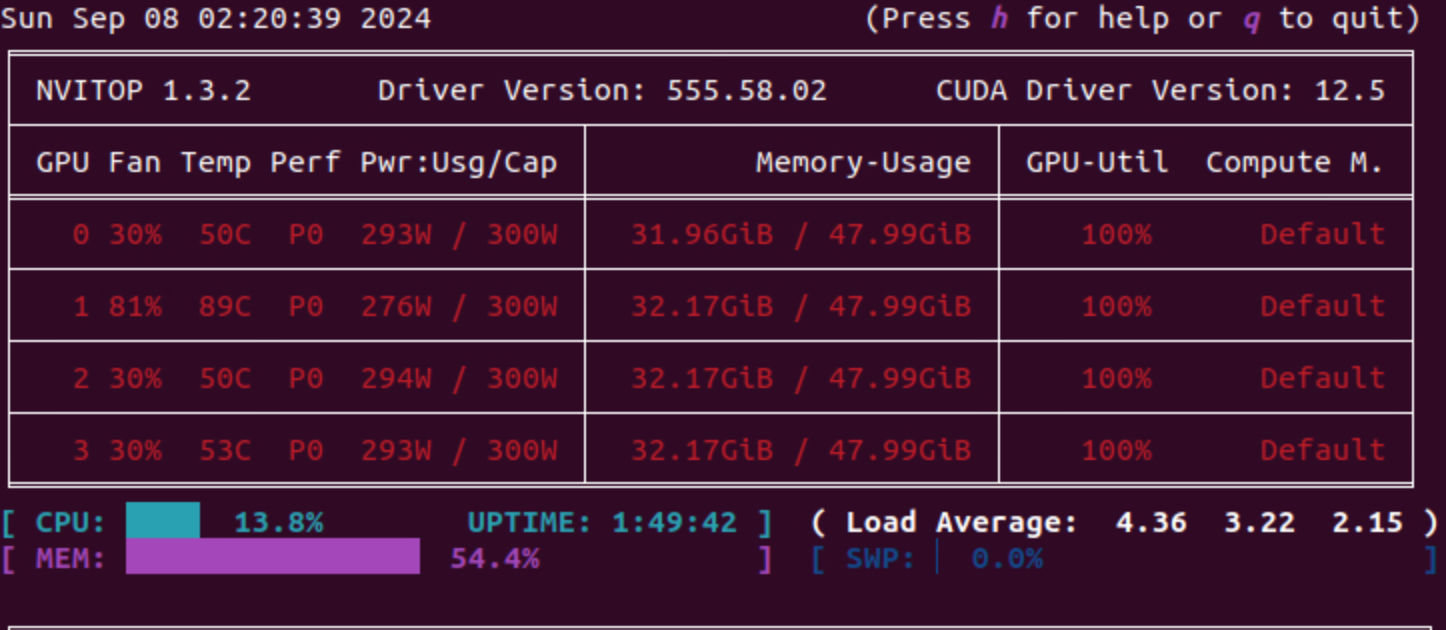 FF
FF D
D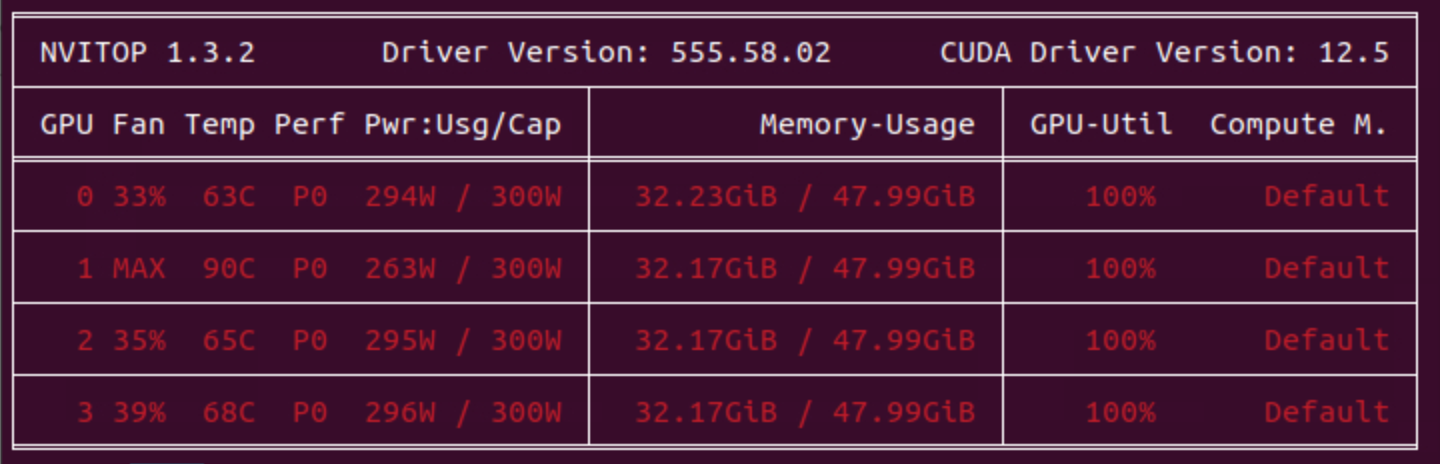 DFF
DFF DD
DD

