Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
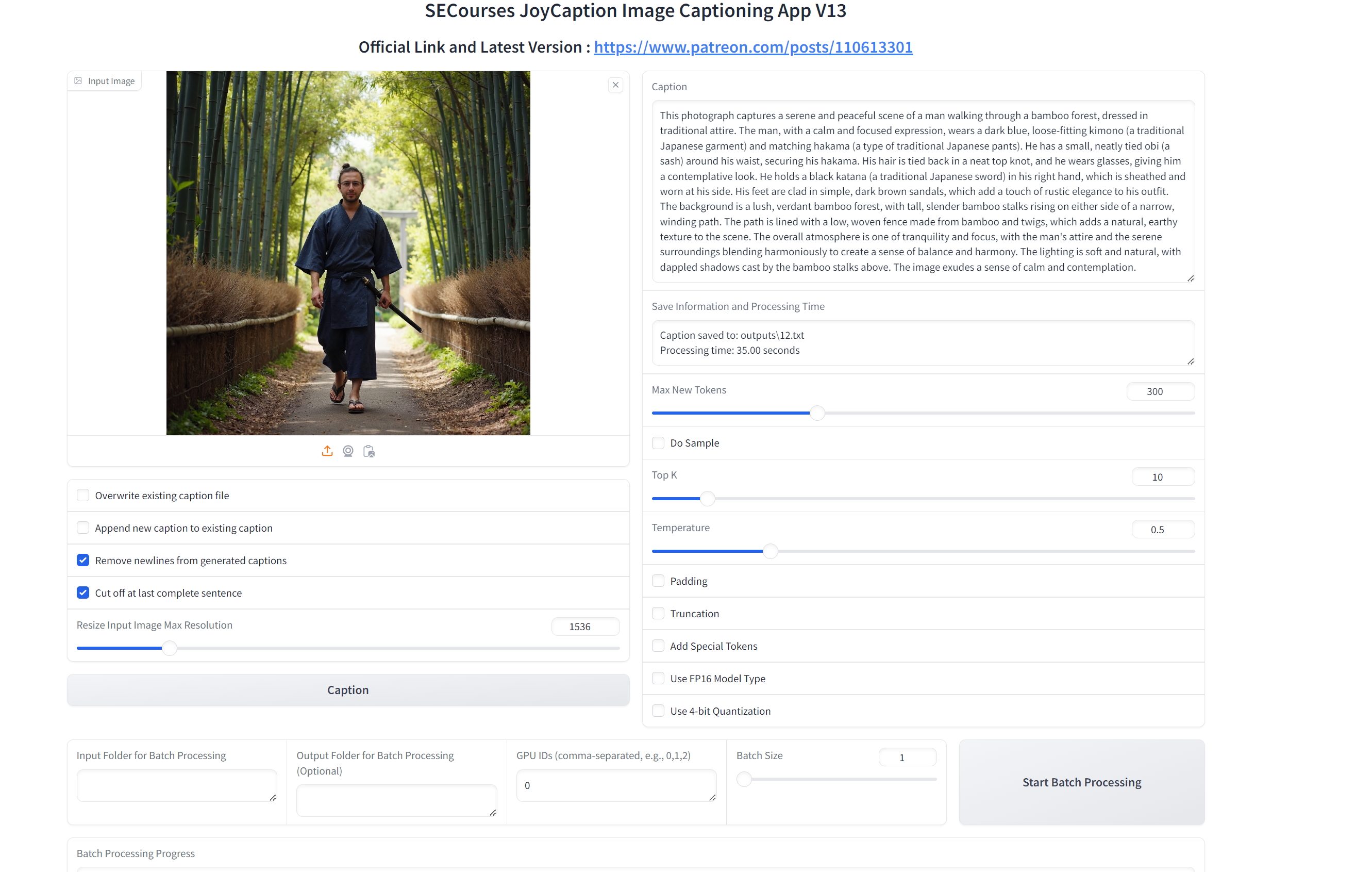
just caption the image with details, colors, makeup, items, objects, emotions, art style, drawing style and objects but do not add any description or comment. do not miss any item in the given image, very simple sentance.
i think in terms of training, when you train this many tokens for a person its not good, but the simplified but accurate ones from internvl gave me quite good results
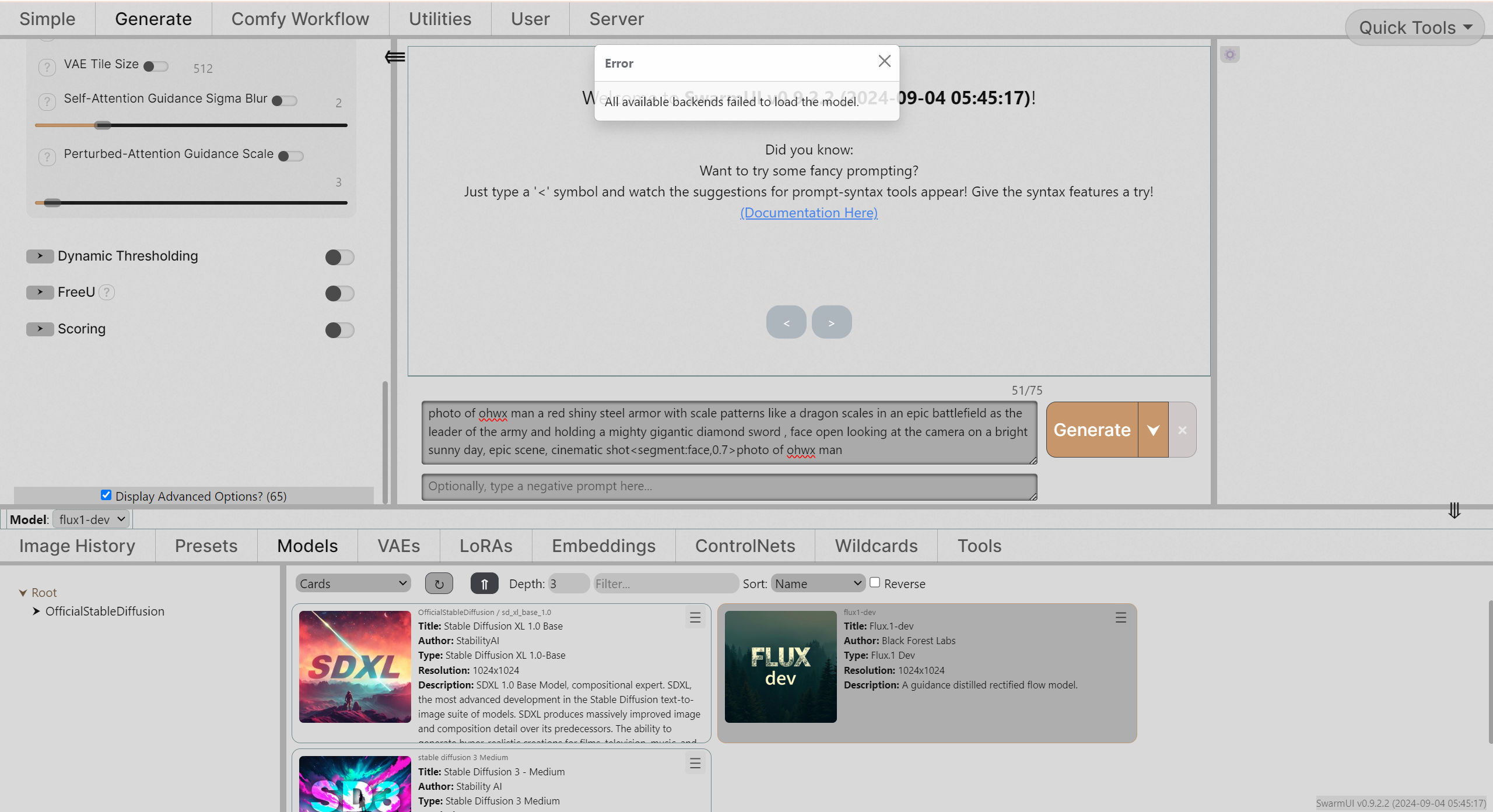
okay i made the unet file inside of models then restarted/updated but still getting same error saying "All available backends failed to load the model"
 F
F
 M
M X
X D
D