Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
Replace SD3Tokenizer with the original CLIP-L/G/T5 tokenizers. Extend the max token length to 256 for T5XXL. Refactor caching for latents. Refactor caching for Text Encoder outputs Extract arch...
what you're geting is about the same as what you'd get if you took a photo and jsut drew over it. you're not updating the photo. you're just drawing over it
you couldn't be more wrong. SD15/XL is more like that. Flux is even able to learn from low res and integrate it into existing model knowledge and generate good high res
i'm not wrong. i know what the code is, i know what the neural network is. i know what they did to it to mask the issues it has, and i know it's not trainable
and you running around creating loras are not creating loras that do anything. you're getting something that gives you image results - but you are NOT getting loras that actually work like loras are supposed to
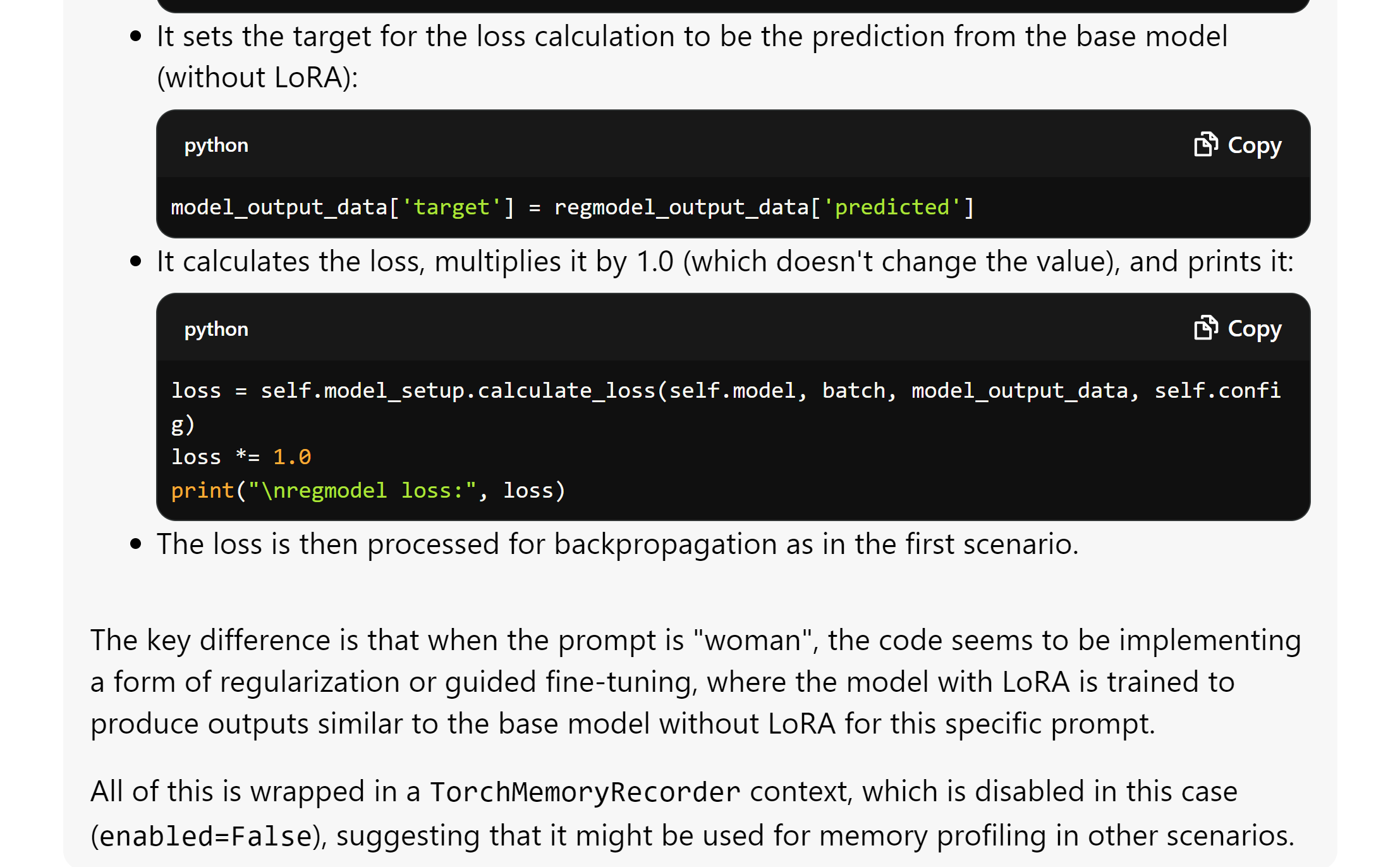
@Furkan Gözükara SECourses just in case you are thinking about training TE - because that would make sense with regularization, to separate the concepts further - the code isn't ready for that. it only unhooks the lora from the transformer.
Replace SD3Tokenizer with the original CLIP-L/G/T5 tokenizers. Extend the max token length to 256 for T5XXL. Refactor caching for latents. Refactor caching for Text Encoder outputs Extract arch...
 C
C F
F D
D M
M