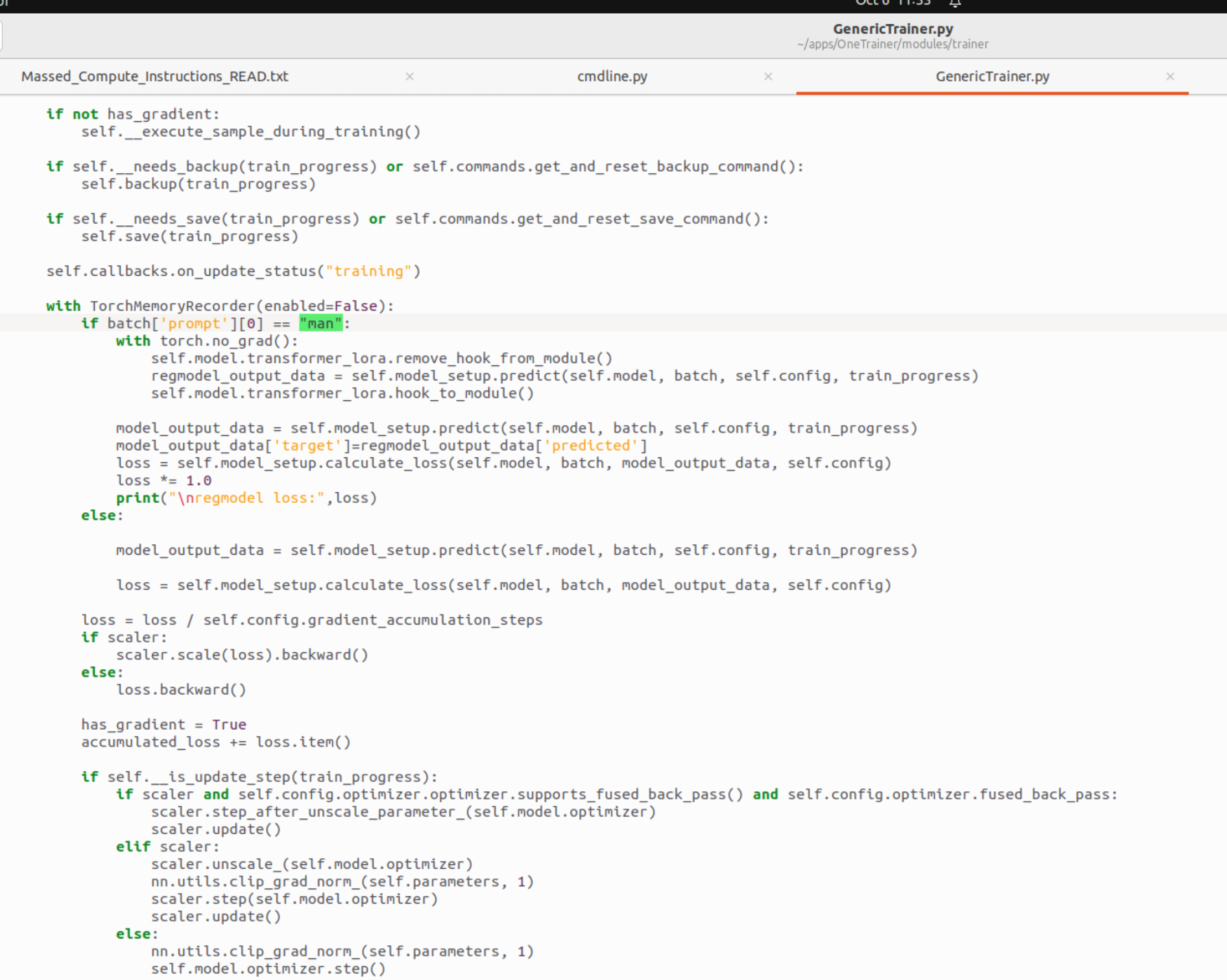
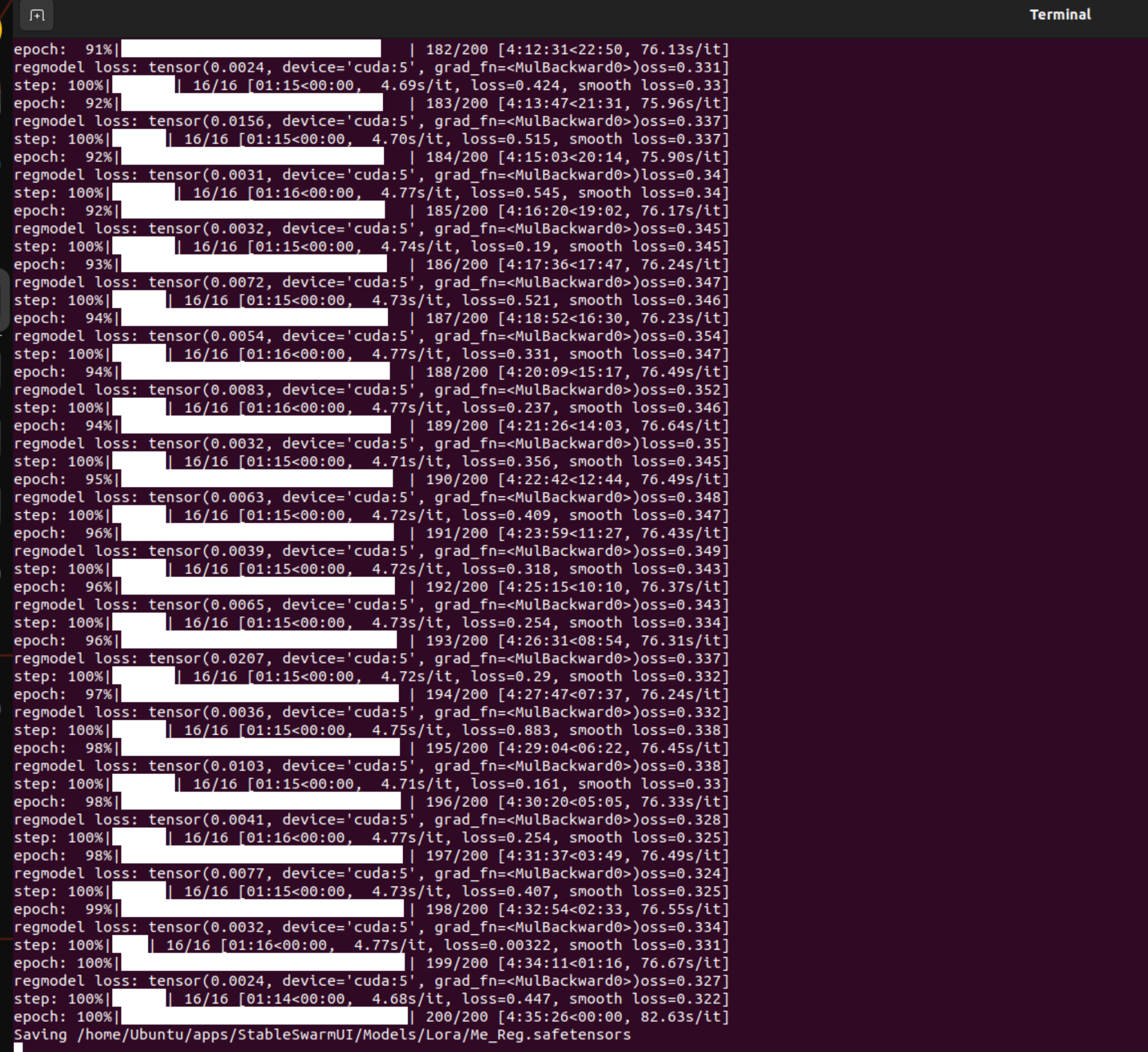
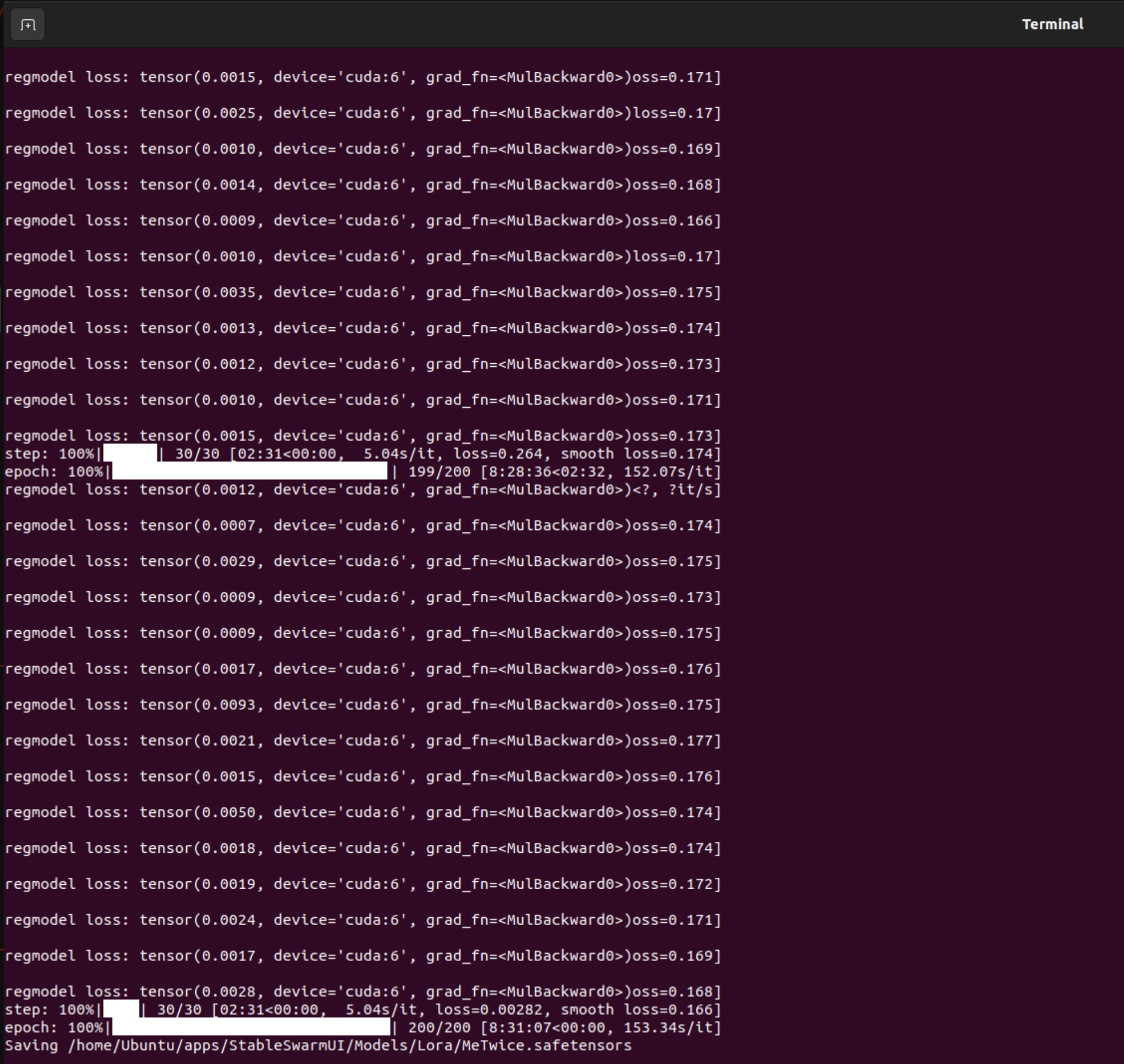
He is right, it is very similar. You could have exactly the same effect by pregenerating and therefore make this possible for full finetune with no additional vram, too. You'd have to synchronize timesteps and seed(!) between the pregenerated data and the training though, which is the difference to the current "Prior Preservation" feature. I did implement this for full finetune also, but without pregeneration so it needs a lot of VRAM for two full models, the student and the trainer model. Feel free to forward my contact.
 D
D C
C
 M
M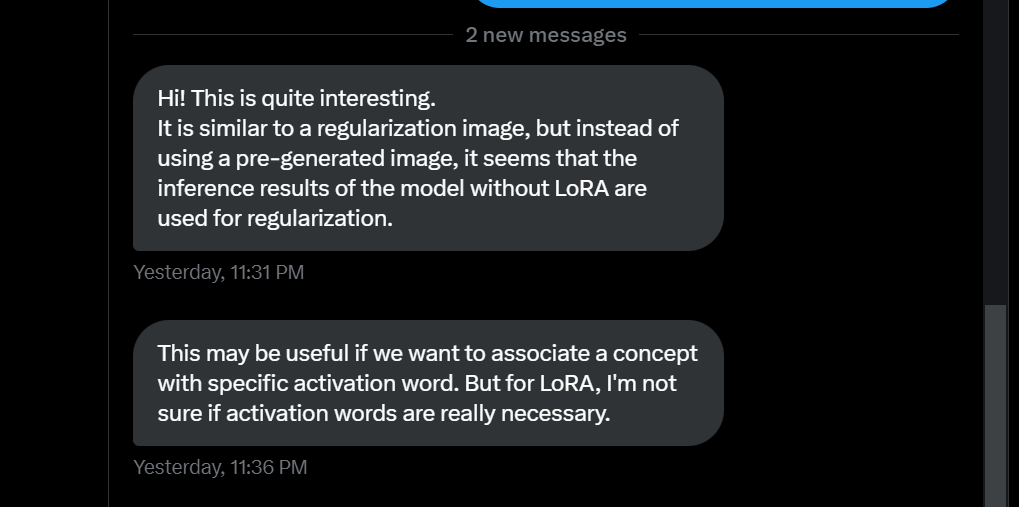
 F
F