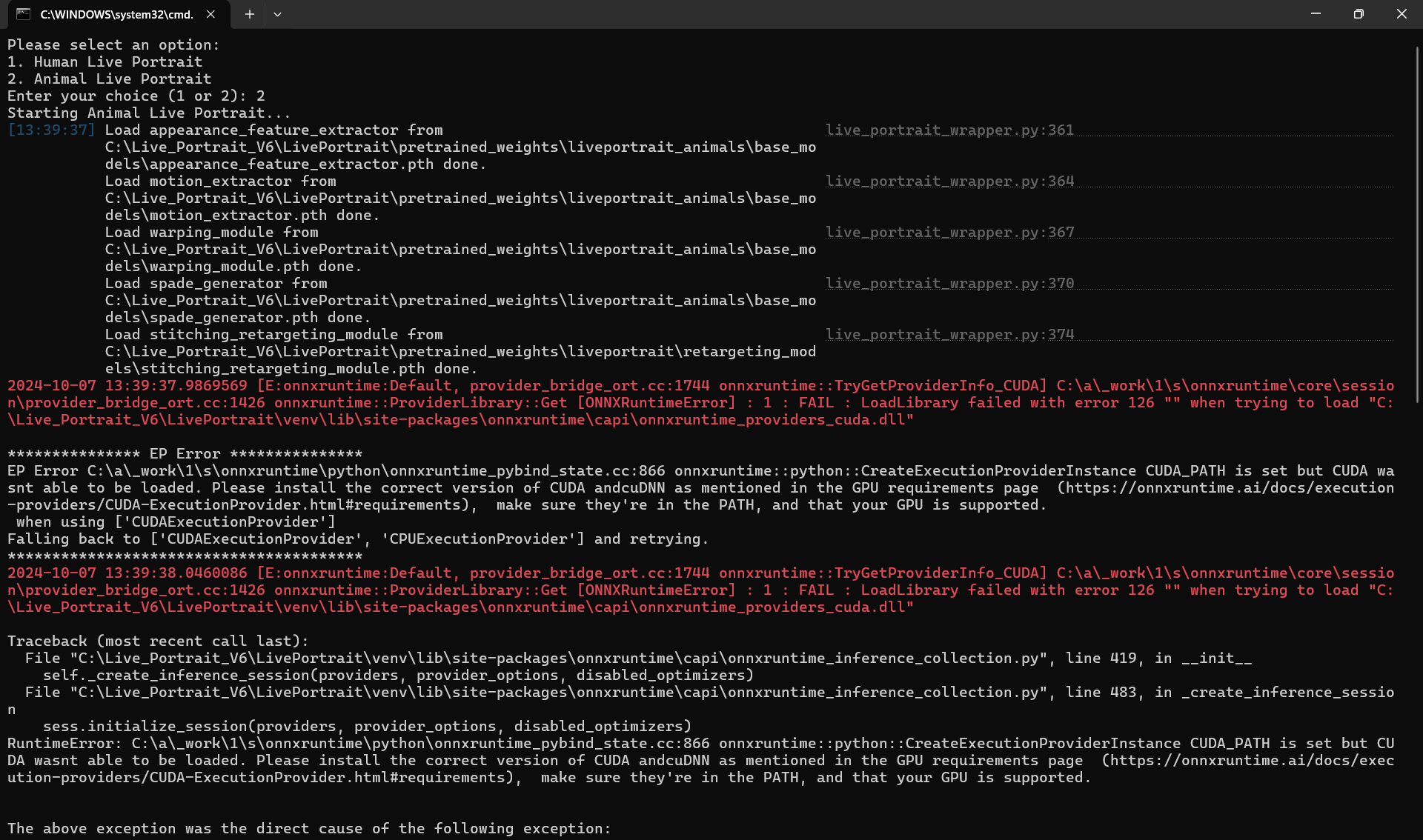
@Dr. Furkan Gözükara im trying to install live portrait following along your tutorial but im getting
@Dr. Furkan Gözükara im trying to install live portrait following along your tutorial but im getting this error once i click "Windows_start_app"
 FF
FF
 I
I DDD
DDD S
S
 P
P XX
XX VXXFFFFFFFFFFF
VXXFFFFFFFFFFF K
K And I have watched your video several times. It's a looooong video
And I have watched your video several times. It's a looooong video  KFFFFFFFF
KFFFFFFFF KKFFFFKKFFFKK
KKFFFFKKFFFKK







