 D
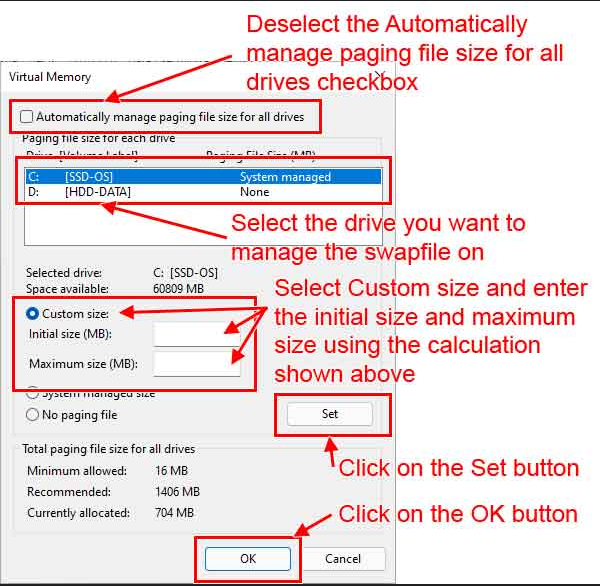
Dthere you set you virtual memory size
D64 GB in you case
 E
EThanks, I already set maximum to 64GB, for the initial I used the old on at around 5GB but this did not resolve the issue
DI did my first test, very promising results, a little undertrained at the moment, at the end I resumed the training with regularization images still no bleeding, now I going to start a new training from scratch 11 people at the same time, family and friends, I going to use regularization images from the class person because I'm training people form different ages and genders the regularization images are captioned I downloaded the dataset including captions a time ago it contains very diverse people from different races and ages from baby to elderly people, male and female. the captions of my subjects are simple "name class" lets see how it behaves
 D
Ddo you have enough free space on the selected disk? you are using the correct preset for your system?
EYes I have half a TB free space on the M.2 ssd, I downloaded Best_Configs_v5.zip and used the 12GB one (12GB_GPU_10800MB_17.2_second_it_Tier_1.json)
Didk, it should work, lets wait for Dr. Furkan may be he can help
EIn task manager my gpu settings say 16Gb total shared gpu-storage, is that correct?
EYes alright thank you

Dyou welcome
 W
WI try to train myself but before that I need more info. Normally when I train a lora of one person if the background have some people behind, somehow the image of the person I train bleed to the background into the people. So in your theory, by training with open dev flux checkpoint we can eliminate this problem right ?
 V
V@Dr. Furkan Gözükara Is it possible to train a flux lora or flux finetune from a flux q8 gguf format?
DThe most important thing and the main difference with this model is that I can train multiple people of the same class without bleeding, with regular flux dev I I trained 3 man for example and the model mixed all the faces together, and on inference prompting for one person returns a mix of all, now the problem is gone with flux-dev-de-distill, it behaves like sdxl but with much better quality. I still experimenting but is very promising so far.
WSo that mean 1 lora 3 lora active keyword is possible but can they appear all together in 1 image ? You need to check it
DI will check that, give me a minute, I trained 1 lora 11 people
Wthank you so much
DOne at a time works perfect, two or more people on the same frame loose likeness, can be fixed with inpainting, man and woman works much better, the same problem that sdxl have, but remember my lora is still undertrained, lets see with my new lora... I will start training later, it will take 2 days or more to finish
VComparison of all quants. Q8 is clearly the winner, when compared to fp16.

 D
D"clearly". sample size of 1
VI have seen other posts with comparison. Do you have a different experience?
DI've made no comparisons. I just use fp8 to generate
VFrom the comparison posts on reddit, q8 seems to keep a similar consistency to fp16. So if we could use it for training that would be super. But that doesn't seem possible atm.
V@daroth Have you finetuned using fp8?
Dno, kohya didn't load that model. only the full sized one worked
Wfp8 is faster when you have rtx 4000s
 O
OIf anyone has a second... Could i get more information on what "de-distilled" means?
Wq8 faster in other cases

 W
WIf your work is success, I will train a checkpoint with maybe 12 people inside it, maybe quality much better than use 12 loras
VI'm looking to do a finetune with a fp8 but the Dr. setting for it uses shared memory, and is slow at around 10s/it. But speaking to koyha, it seems its an intended behavior to use shared memory.
Wjust learn to use masscompute service or runpod. Local VGA is not mean to change model anymore. Quality is worst.
VI might have to, but I can do super fast loras, so I was suprised how slow it was.
WI use 3090 with 24gb Vram but I can only train fp8 lora. I use mass compute to train fully fp16 lora with the cost of about 4 usd
Wvery cheap
VThat is per hour?
Wno, total cost
OMassed Compute - from my experience has been great, far better than runpod. The SECourses pricing on the A6000's is great.
Wper hour is only 1.25 usd
Wwhen training with my local pc, I need 11 hours of 3090 run full throttle, my poor pc fan roar the hell of of my room and the temperature turn up a lot
Wso 4 usd saving my trouble and time
W11 hours of 3090 for fp8 lora
Wno thank you
DI'm training this model now, Works much better for training, you can train multiple people on one lora without concept mixing, it behaves very much like sdxl, much more flexible
VYeah the pc lights stayed on and it looks like a disco ballroom.
WI never see any loras in SDXL have multiple concept, Flux maybe the first model can do it
DI trained loras on sdxl with more than 20 people no problem
WSince SDXL have instance ID, so I use it for more convenience if I need people lora anyway
VBest gpu prices are from here - https://www.autodl.com/home but I don't know how to run them. Learned about them via an article discussing 48gb 4090s.
AutoDL为您提供专业的GPU租用服务,秒级计费、稳定好用,高规格机房,7x24小时服务。更有算法复现社区,一键复现算法。
Wthis really new to me
OIs it possible to create a finetune, then extract the LORA? I've had good luck with that for single subjects, and sometimes it's also nice to have a checkpoint as well.