Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
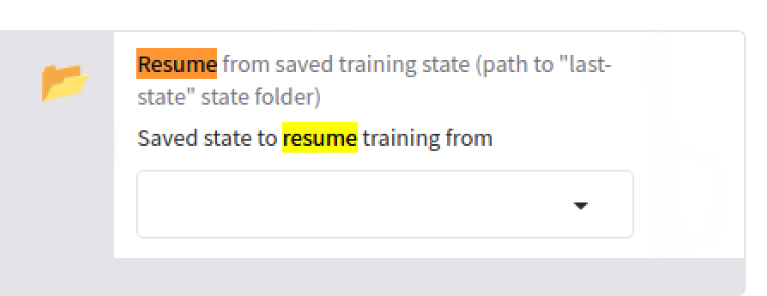
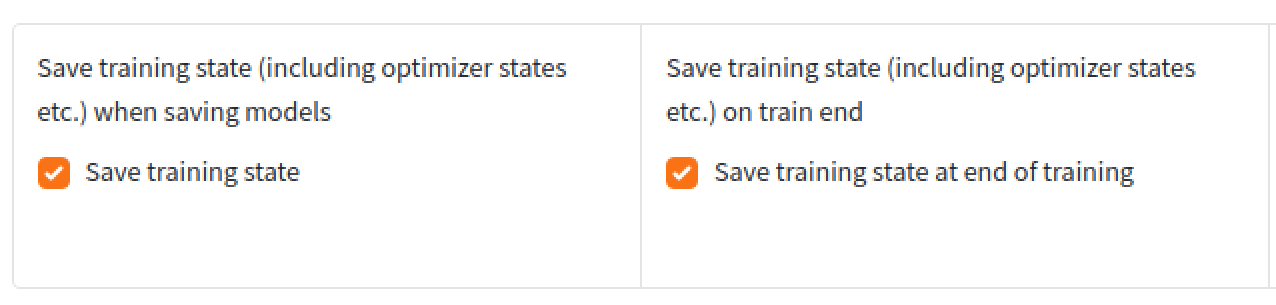
I made it work in windows, but I don't know to get the proper folder path in ubuntu. In windows, if you select the two options in the picture, you can shutdown and resume based on the last save, with the same learning rate etc. Nothing is lost or needs to be done, which is preffered instead of just loading the last saved model file. You would then link to the folder of the laste save-state folder of the model you are training to resume. In onetrainer its much easier.
Quick question, does fine tuning require less steps than LORA? My 3,000 steps fine tuning from last night (15 pics x 200 epochs) is giving much less good results than my 5,800 steps Dim 16 Lora I did with Fluxgym. Is that normal?
@Furkan Gözükara SECourses The use of save-states is much better as its actually continuing the training of the model. Starting off from the last saved checkpoint is essentially a whole different training of the model and the results will be different.
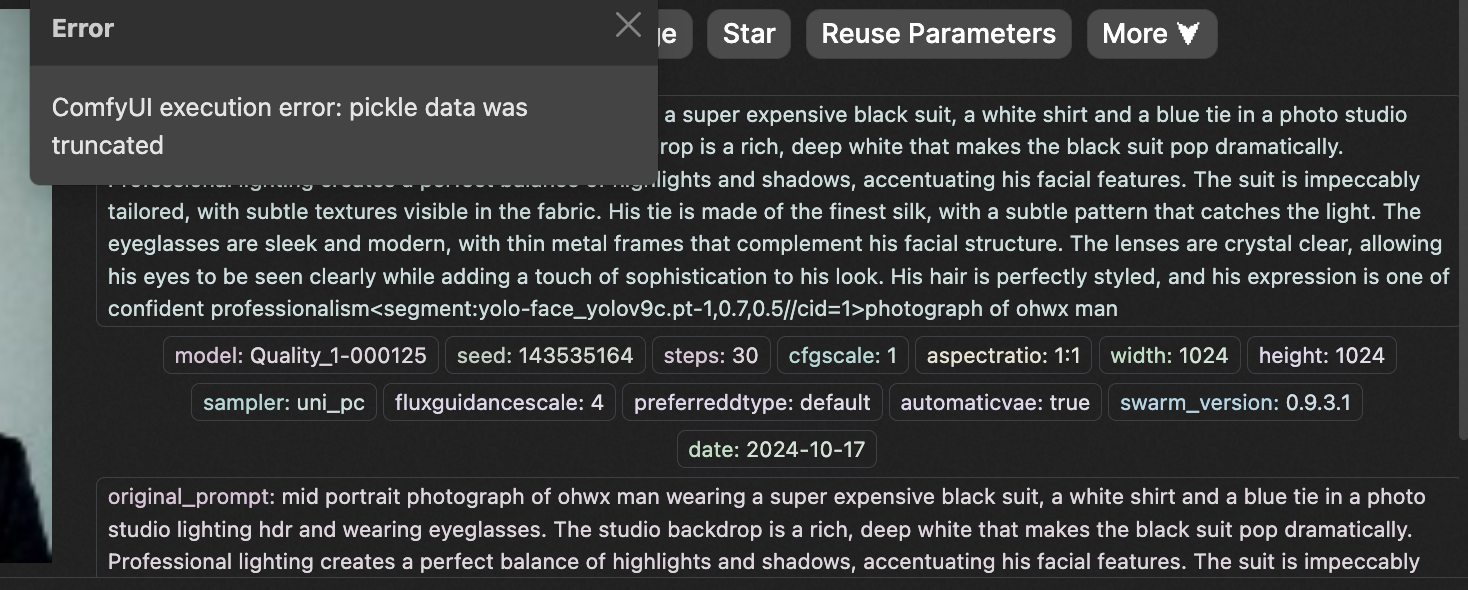
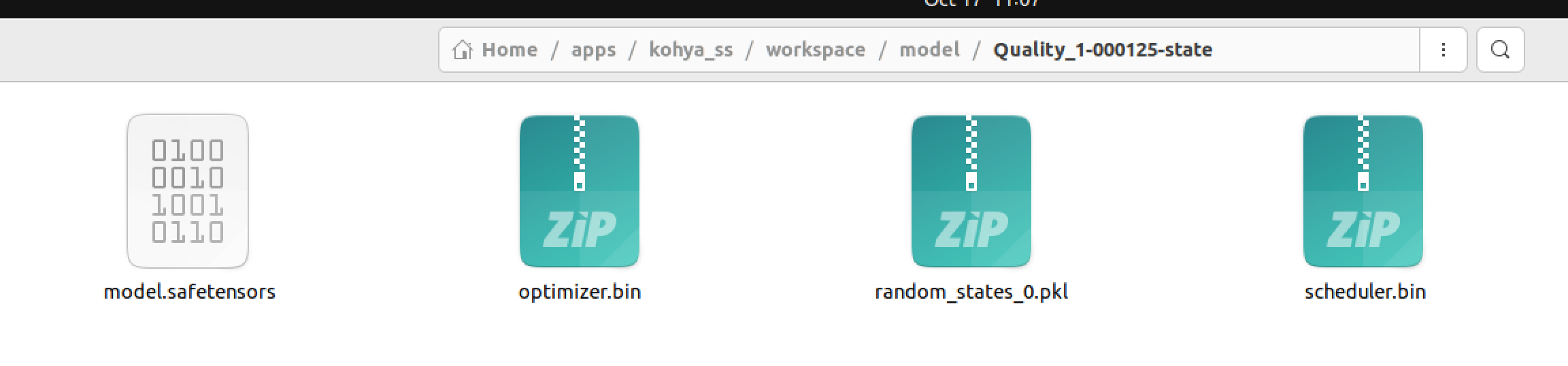
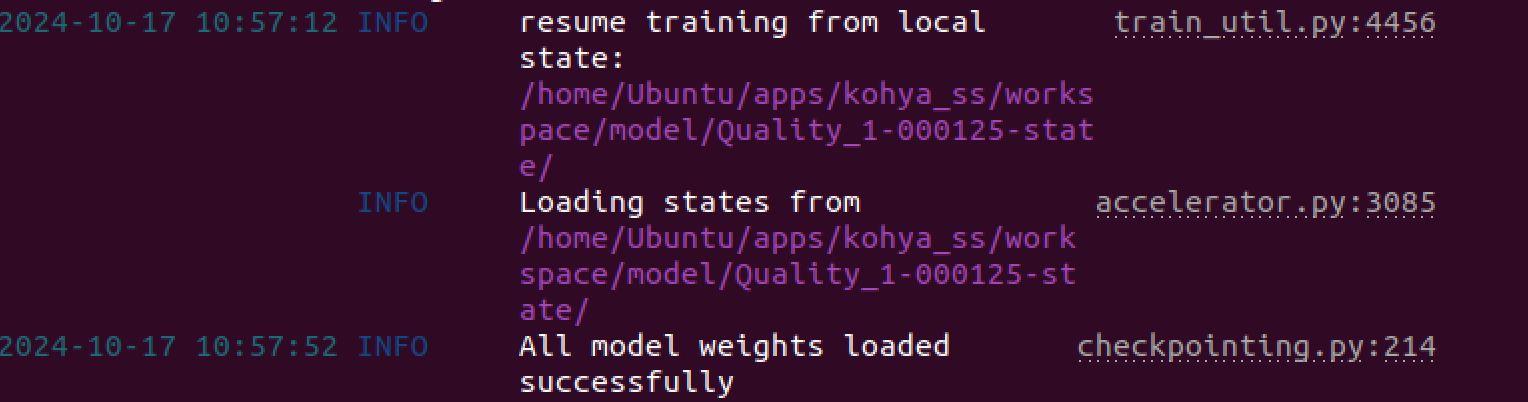
Anyway, I figured out how to use saved state and it worked, you just have to enable it at the start and it saves a special folder called saved-state. If for some reason you have to continue training due to crash or no HD space you can continue by inputting the folder patch into this field before you start. If you get an error then the path is not correct. If the folder exists with what is seen in the photo then it will definitely continue training with the same state it left off at as well as same result of training, just a continuation.
I forgot to mention, you would also have to edit the number of epochs, to be what you did not initially finish. So if you have a training for 200 epochs, and the saved state is from the 150 epoch, you have to change the epoch to 50 in the settings, or else it will continue training from the 150th epoch save-state for another 200 epochs. You can increase the epochs what ever you like, but it will be start from epoch 1 to what you set, since you are continuing the training using the saved-state folder. Its confusing if you don't understand this part.
Is there any point in modifying LR with adafactor? 22 hours of training and 4400 steps later, I have the impression that my final samples are still undertrained.
 F
F
 W
W C
C W
W

 V
V M
M D
D
 W
W