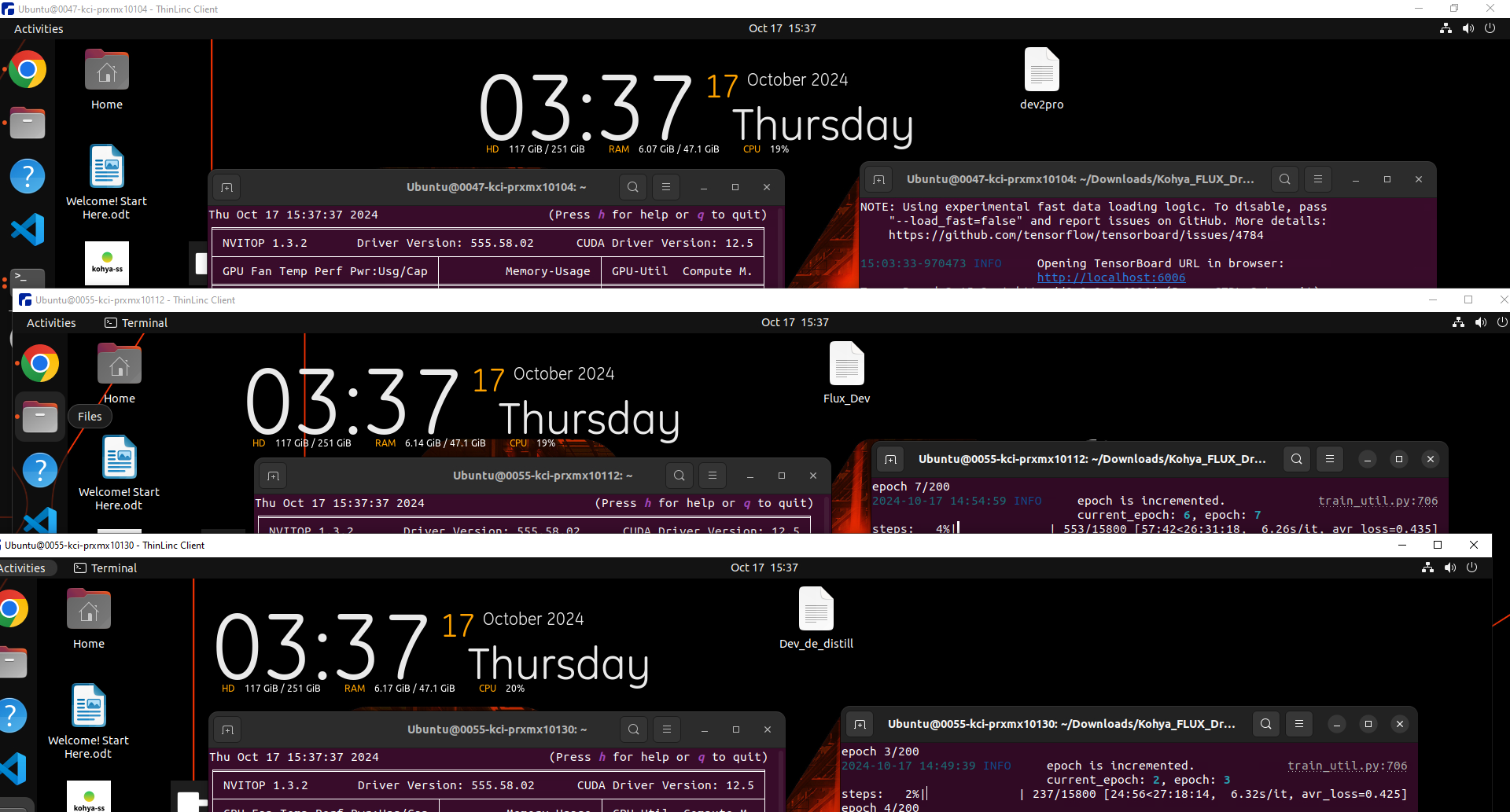
@Dr. Furkan Gözükara how long did it take to train that 10k images model you did ? and what hardware
@Dr. Furkan Gözükara how long did it take to train that 10k images model you did ? and what hardware ?
 FFFFFFF
FFFFFFF MMFFFFF
MMFFFFF DDFDD
DDFDD
 FFFDFFFDDDDFF
FFFDFFFDDDDFF F
F D
D KKK
KKK K
K K
K K
K D
D DDKFF
DDKFF
 A
A RFF
RFF





