Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
@Furkan Gözükara SECourses I asked bmatis and he added a feature to the gui that was in the code, the ability to set the max amount of save-state folders to what ever we want. If set to 1 it will be overwritten with the newest save-state made.
trying to train on a Flux model but getting this error with it... File "D:\kohya_ss\sd-scripts\library\flux_utils.py", line 81, in analyze_checkpoint_state max_double_block_index = max( ValueError: max() arg is an empty sequence
Does this mean we can now resume training where we left or if I want to train again with more epochs can I just add it and start from where it last trained?
@bmaltais can we add this to gui so many people want to test
Specify a large value for --prior_loss_weight option (not dataset config). We recommend 10-1000.
Set the loss in the training without using the regularization image to be close to the loss in the training using DOP.
doubt that this is a good config recommendation.
all my proof-of-concept samples were at weight 1.
Yes, loss of reg steps is then very low compared to train steps, but this is a function of the reg step prediction already being very close to the target.
you can try at weight 10 or even 1000, but I'd expect that the regularization then overwhelms the training steps, and the model doesn't learn anything anymore.
You could always do this if you used the save-state options. You would then paste the path of the folder in the resume from state box. However, the issue is that if you trained for 100 epochs, and the setting was set for 200 epochs, resuming from the trained state of 100 epochs will then train for another 200 epochs, so 300 in total. The epochs in the setting would have to be adjusted if you want max 200.
The new setting is to change the maximum amount of save-state folders you can have. Normally it would save either at the end, which is not great if something bad happens, or at every time you save a copy of the model. This can be a lot of big files, so with this option you can have it set to say a max saved-state amount of 1, so that each new saved-state folder overwrites the older one. Great for saving HD space.
Hi @Furkan Gözükara SECourses I try to use your Quality_1_23100MB_14_12_Second_IT.json to train checkpoint but it's very difficult to get 23.1 GB Vram. Windows mostly eat 1.2 - 1.3 GB VRam. How do you limit VRAM use by windows. Since I have 24gb VRAM choosing Quality_1_15500MB_32_Second_IT.json is double the training times and not ultilize my VRAM.
Hello, I want to try to finetune flux dev on a style rather than a character? Any advice on what is different? For example the captioning, I only captioned with my trigger word + class for the character, is that the same for style? If you have any documentation or training (even if not from you) that's be very much appreciated!! love
For styles you can either go with a trigger word for the entire image, fully caption everything, or no captions. Characters require captions for everything except the things about the character, like their hair, clothing etc. Things that are captioned can be changed later, things not captioned are static and will be reproduced when prompted.
 F
F V
V

 A
A �
� S
S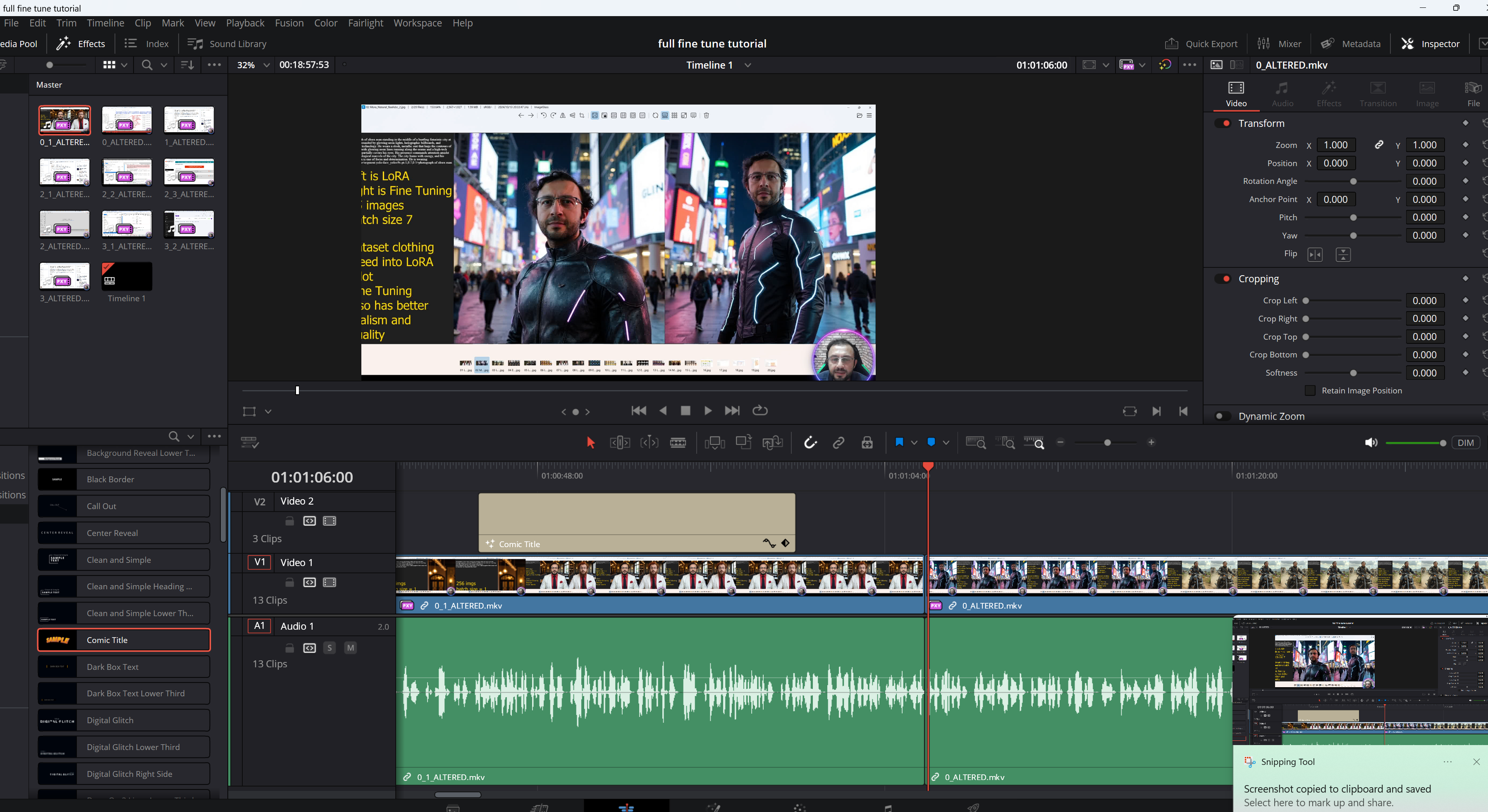
 D
D V
V W
W C
C S
S
 C
C





