Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
Update https://huggingface.co/nyanko7/flux-dev-de-distill Lora training, removing the class did not help with class bleeding, the result was almost the same, and maybe worse because difficulted the prompting on inference. I'm doing another test with just one class and some regularization images, idk if kohya new code was implemented yet, hope this will help too.
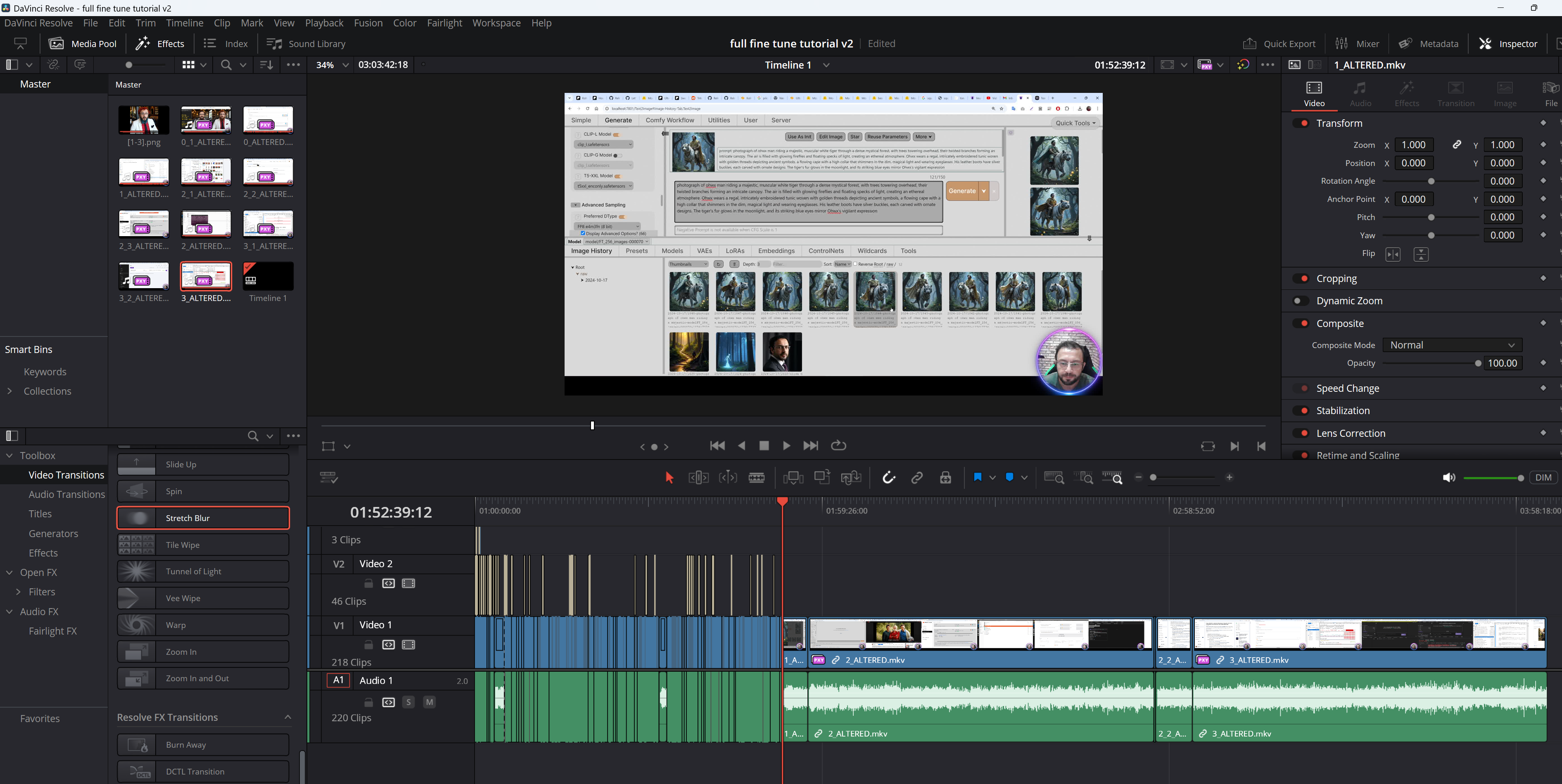
this feature is part of new webui in development, qwen-flux-wan-such This feature is part of a new webui under development, when finished, Dr. will make a tutorial on how to use it. For now I'm in the final stages and presenting some previews here. This feature only uses the image-to-image diffusion pipeline and a controlnet to refine.
1) It adds a sharpness to the image. The images are more noisier, better realism, and harsh reality kind. TBH, that is not always a good thing. If you like or do not like an image, it is subjective> 2) The ability to modify CFG can give you vastly varying results for the same seed. Its CFG scale is much, much tamer than dev2pro and produces linear effects (as you would expect) if you increase or decrease it. 3) The additional time it adds to inference is very frustrating. Original dev said 60+ steps, and he is right. I got good results at Step 70. You can get the generation much faster on flux_dev with 25 to 42 steps. Adding steps adds time to an already slower generation speed. 4) You need to use extra settings during generations like thresholding, which adds additional complexity to the traditional step-cfg system.
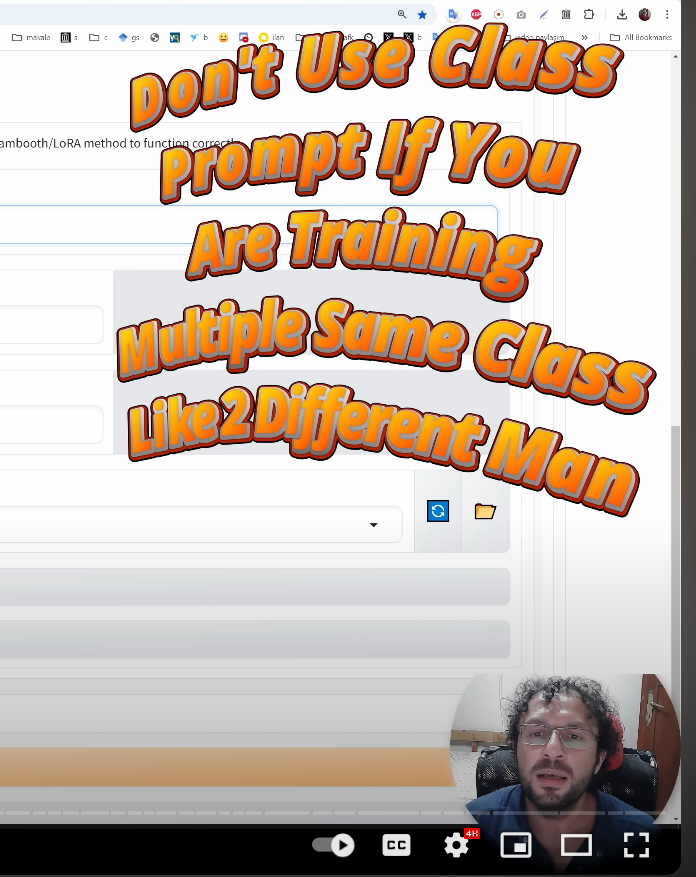
also lets say im training to make a consistent yet diverse race (ie different robots as opposed to a consistent singular character robot like Optimus Prime) for a flux lora / DB . its best to only use the instance prompt: "ohwx" + no captions + instance : "robot"
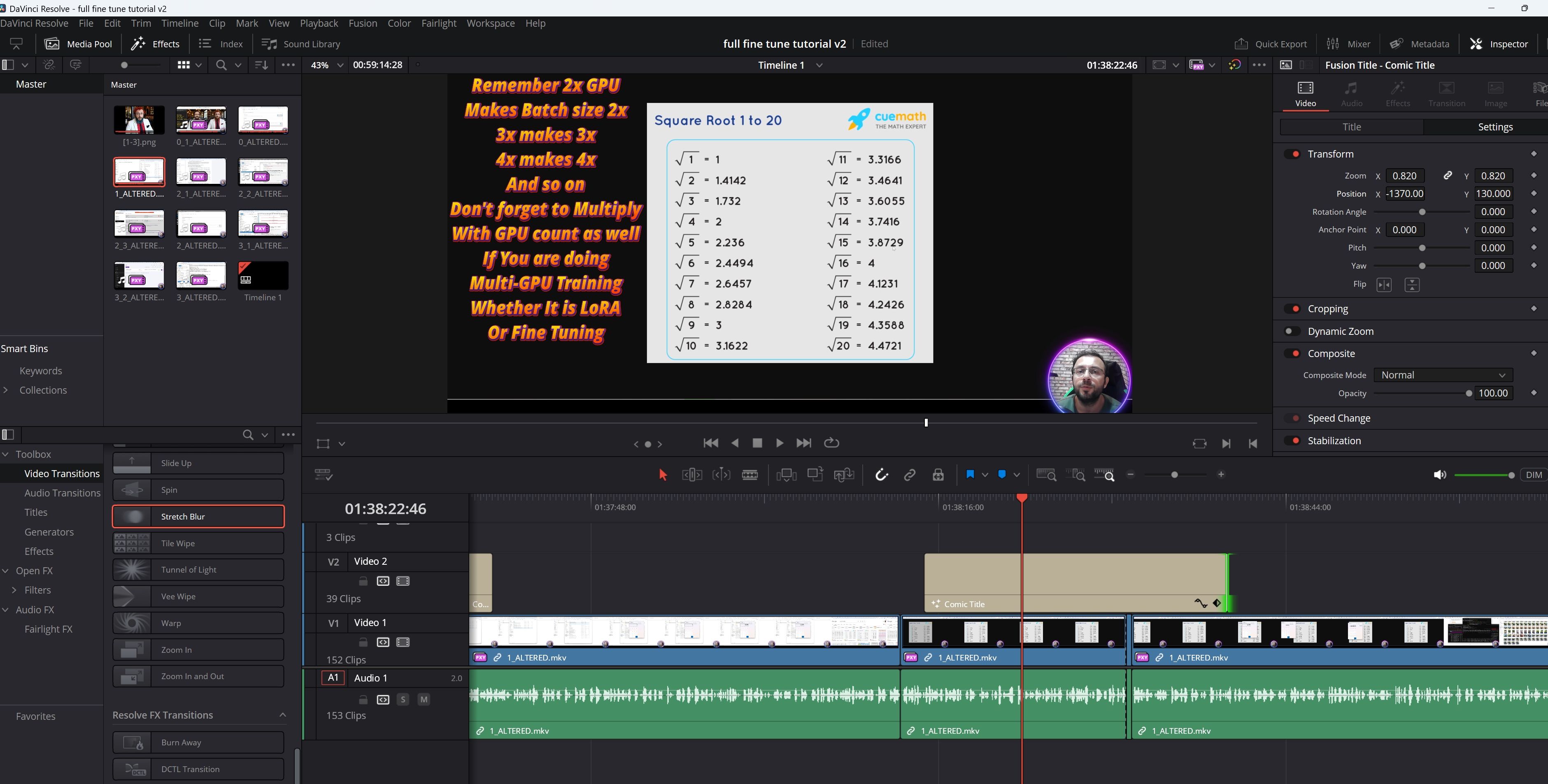
We all know from Dr. Furkan Gözükara's work that it typically takes 15 images, 3000 steps, and a learning rate of 4e-6 to train a model to capture a face. However, training something as complex as an alternate futuristic reality is an entirely different challenge. The dataset size, steps, and learning rate required for this are much more demanding.
In my case, with a dataset of 500 images for stage 1 and 1000 images for stage 2, I initially started with a low learning rate (4e-6), fearing overfitting. However, after running into issues like underfitting and wasting valuable resources, I learned an important lesson: starting with a high learning rate(like 4e-5) allows you to capture the core of the concept much faster, even if it overfits. After that, you can restart with a lower learning rate to fine-tune the details.
In fact, starting with a low learning rate to avoid overfitting ended up costing me both time and money. It takes longer to realize you're underfitting, and by the time you do, you've already invested significant resources. Allowing the model to overfit initially and then restarting with a lower LR is much more cost-effective and efficient.
That said, I’m still open to learning if this insight can be further optimized. I tend to favor restarting rather than fine-tuning because of my perfectionist tendencies, but there may be a balance that I’m missing. For now, the strategy of beginning with a high LR and adjusting downwards has proven to be the most effective approach for me.
it is true every dataset is different, but i tested my LR on both 15 and 256 images worked very good. are you doing fine tuning or lora? your LR difference is huge 10 times
 D
D S
S
 D
D P
P
 F
F A
A T
T

 N
N

 A
A
 V
V








