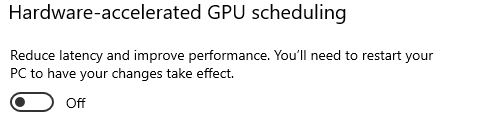
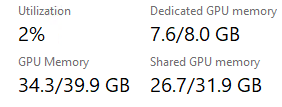
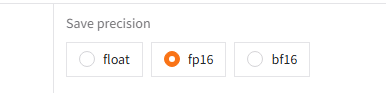
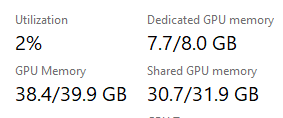
Rank_3_T5_XXL_23500MB_11_35_Second_IT.json with V9 version on rtx3090, 8.94s/it 2024-10-25 20:14:
Rank_3_T5_XXL_23500MB_11_35_Second_IT.json with V9 version on rtx3090, 8.94s/it
2024-10-25 20:14:29 INFO prepare CLIP-L for fp8: set to torch.float8_e4m3fn, set flux_train_network.py:509
embeddings to torch.bfloat16
INFO prepare T5XXL for fp8: set to torch.float8_e4m3fn, set embeddings flux_train_network.py:538
to torch.bfloat16, add hooks
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 50
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 50
num epochs / epoch数: 200
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 10000
steps: 0%| | 0/10000 [00:00<?, ?it/s]2024-10-25 20:14:47 INFO unet dtype: torch.float8_e4m3fn, device: cuda:0 train_network.py:1084
INFO text_encoder [0] dtype: torch.float8_e4m3fn, device: cuda:0 train_network.py:1090
INFO text_encoder [1] dtype: torch.float8_e4m3fn, device: cuda:0 train_network.py:1090
epoch 1/200
INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:715
D:\IA\kohya\kohya_ss\venv\lib\site-packages\torch\autograd\graph.py:825: UserWarning: cuDNN SDPA backward got grad_output.strides() != output.strides(), attempting to materialize a grad_output with matching strides... (Triggered internally at C:\actions-runner_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\cudnn\MHA.cpp:676.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
steps: 0%|▏ | 34/10000 [05:04<24:45:40, 8.94s/it, avr_loss=0.417]T
2024-10-25 20:14:29 INFO prepare CLIP-L for fp8: set to torch.float8_e4m3fn, set flux_train_network.py:509
embeddings to torch.bfloat16
INFO prepare T5XXL for fp8: set to torch.float8_e4m3fn, set embeddings flux_train_network.py:538
to torch.bfloat16, add hooks
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 50
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 50
num epochs / epoch数: 200
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 10000
steps: 0%| | 0/10000 [00:00<?, ?it/s]2024-10-25 20:14:47 INFO unet dtype: torch.float8_e4m3fn, device: cuda:0 train_network.py:1084
INFO text_encoder [0] dtype: torch.float8_e4m3fn, device: cuda:0 train_network.py:1090
INFO text_encoder [1] dtype: torch.float8_e4m3fn, device: cuda:0 train_network.py:1090
epoch 1/200
INFO epoch is incremented. current_epoch: 0, epoch: 1 train_util.py:715
D:\IA\kohya\kohya_ss\venv\lib\site-packages\torch\autograd\graph.py:825: UserWarning: cuDNN SDPA backward got grad_output.strides() != output.strides(), attempting to materialize a grad_output with matching strides... (Triggered internally at C:\actions-runner_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\cudnn\MHA.cpp:676.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
steps: 0%|▏ | 34/10000 [05:04<24:45:40, 8.94s/it, avr_loss=0.417]T