 F
Fconfig same only spda changed to xformers

 L
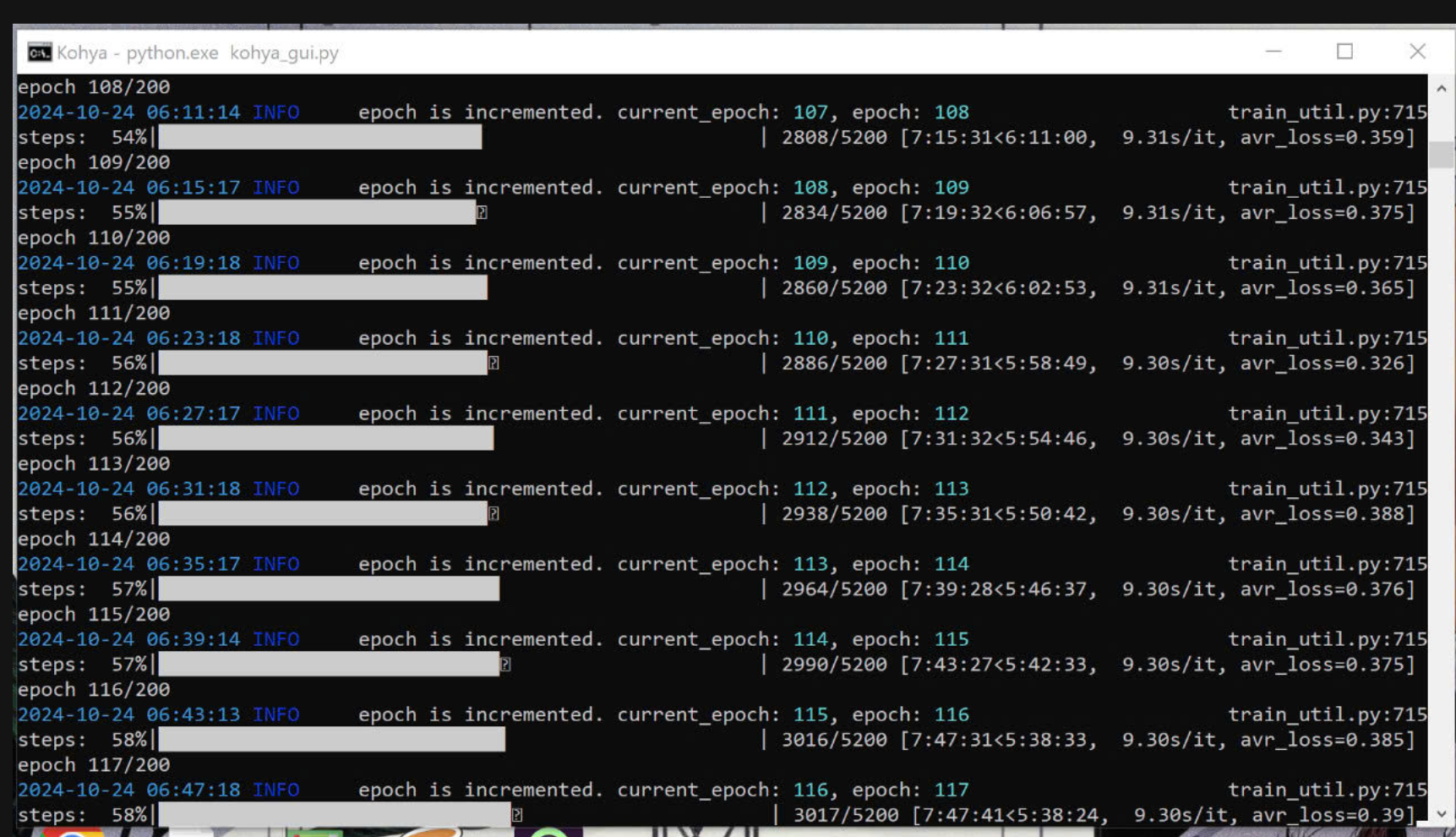
LI noticed that the speed gain is in the best GPU utilization. GPU utilization is at 100% constantly. It's great, but be careful to keep your equipment well cooled. In my case the VRAM temp went up to 94 celsius after 7 hours of training.
 D
DI get like 6s/it on a 4090 and my GPU stays around 60-70C
Lmemory temp and hot spot temp?
L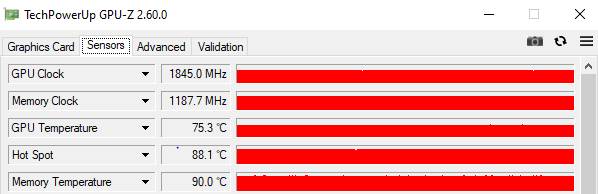 D
D D
Dthe hotspot temp does max out pretty high but i think thats still safe
LGREATTTT!!!! In my case it is very hot, here we are in spring. If I were in winter it would be nice because my pc gives me a little warmth.
DI just got my air conditioner fixed XD Before that, if I used my 4090 for anything my room would heat up like a sauna
 T
TI think i figured out the 8GB out of memory cuda problem. on torch 2.5, its 1024,1024 resolution runs out of memory, if i drop to 768,768 it works. Any ideas how to get it to run at 1024,1024?
 V
VEither increase page file size or you might need more physical ram. Smaller the vram the more ram needed.
Fgreat speed
Fit should work weird
Fincrease block swap count
TI think its torch 2.5 it works on 2.4 - but slow. increase block swap to 36 didn't help. But that was the culprit 1024 vs 768. Must just be slightly short vram. Or have something to do with source images being PNG? is your set jpg?
Fno image doesnt matter
Ftorch 2.4 works but way slower
Fso maybe that is why
TI am trying with a smaller source image set to see if makes a difference. 15 vs 30 images.
Tso even with 5 images 1024/1024 fails, but 768/768 works with any number of images on 8GB torch 2.5 . I even changed OS to windows 11 to try to figure out.. maybe its a memory leak in torch 2.5 and older nvidia.
Fvery possible
Fi got to sleep now
TFYI precompiled pytorch - does not require cuda installed on windows. it comes built in.. I have completely removed VS2022 and cuda from my system during troubleshooting
Fcuda is used only when you compile something
Flike insightface
Fxpose
Fetc
 X
X4060 ti (16gb) vs 4070 (12gb)
which is faster when we consider about lora traning and stuff, I mean like just having a big vram means faster train?
which is faster when we consider about lora traning and stuff, I mean like just having a big vram means faster train?
 F
Fif VRAM is not enough you have to sacrifice a lot of speed
XI see
Xoh and was wondering if we got 2gpus, can we like combine or do smthing in training?
Fnope sadly you cant
Fyou can maybe multi GPU SDXL train
For SD 1.5
Fwith 2x 16gb GPUs
Fbut it may not bring any speed
Fon windows
Xah sad...
 D
Di keep trying to install kohya with flux per instructins but after i copy paste the first step, it ends with this error "Copying accelerate config file to: /root/.cache/huggingface/accelerate/default_config.yaml
Traceback (most recent call last):
File "/workspace/kohya_ss/kohya_gui.py", line 6, in <module>
import gradio as gr
ModuleNotFoundError: No module named 'gradio'
root@c9368cea187b:/workspace# "
Traceback (most recent call last):
File "/workspace/kohya_ss/kohya_gui.py", line 6, in <module>
import gradio as gr
ModuleNotFoundError: No module named 'gradio'
root@c9368cea187b:/workspace# "
 F
Fget a fresh pod
Freinstall
Fhe just fixed errors
 S
SI'm trying to train a lora/dreambooth to make simple icon type images of a particular style, and having watched the tutorials and looked at the sample outputs, I'm not sure if this project is better suited to dreambooth or lora training. The attached image is an example of one of the training images.
 D
D@Furkan Gözükara SECourses what template do i choose
 F
Ffine tuning better for everything
Fyou can do 100%
Ffor which one?
SI keep seeing people saying that it's best to do no captioning when training a style, but it seems odd to me -- would I not want to give it at least a minimal caption, for example "[triggerword], cow, bat wings"