Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
Hi, I want to train a rock band, it's a trio: vocals and guitar (leader), bass, drums. I plan to distribute the photos in folders: folder with photos of the singer, folder with photos of the bassist, folder with photos of the drummer, and folder with photos of the band complete. Has anyone trained Lora for more than one person? What photo distribution do you recommend?
great, so I only differentiate them with the captions? eg. leader(1).txt : nameofrockbandxyz, j0hnxyz leader vocalist, holding a microphone on a stage....
Hi @Furkan Gözükara SECourses have you tried training a style with dreambooth. I wonder what is different when a checkpoint learning a style compare with lora. Does it learn faster so we can train with lower epoch
for example for the footwear, when I input "man wearing ((opinci-like moccasins)) " the old model creates pretty accurate opinci, the new one, not as much, also it creates 2 people where as I only asked for one. And in general it doesn't stick to the prompt as well.
So my question is: is there something I did wrong with the training? can I do anything to make the new model be more like the old model with respect to accurately represanting the clothing
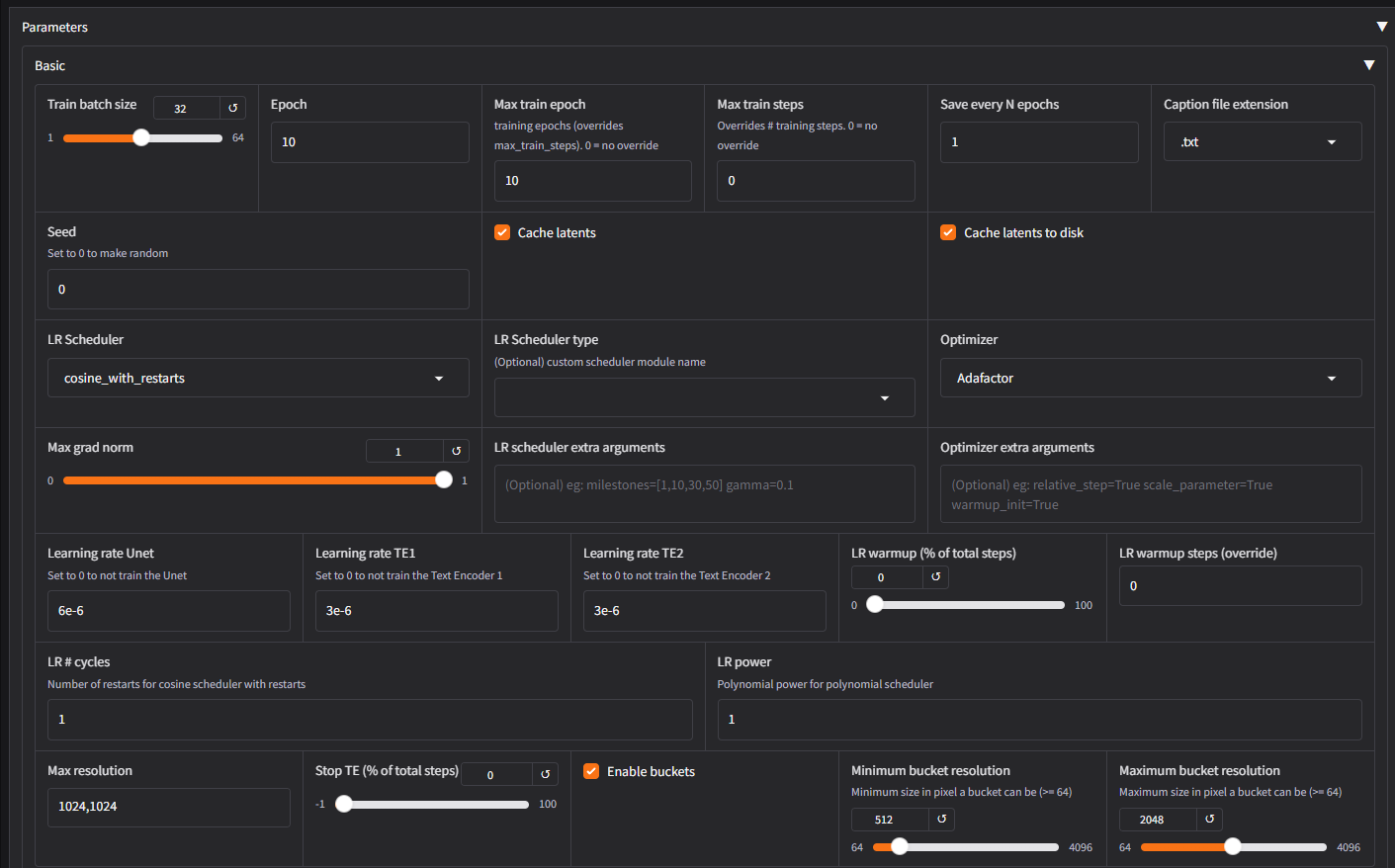
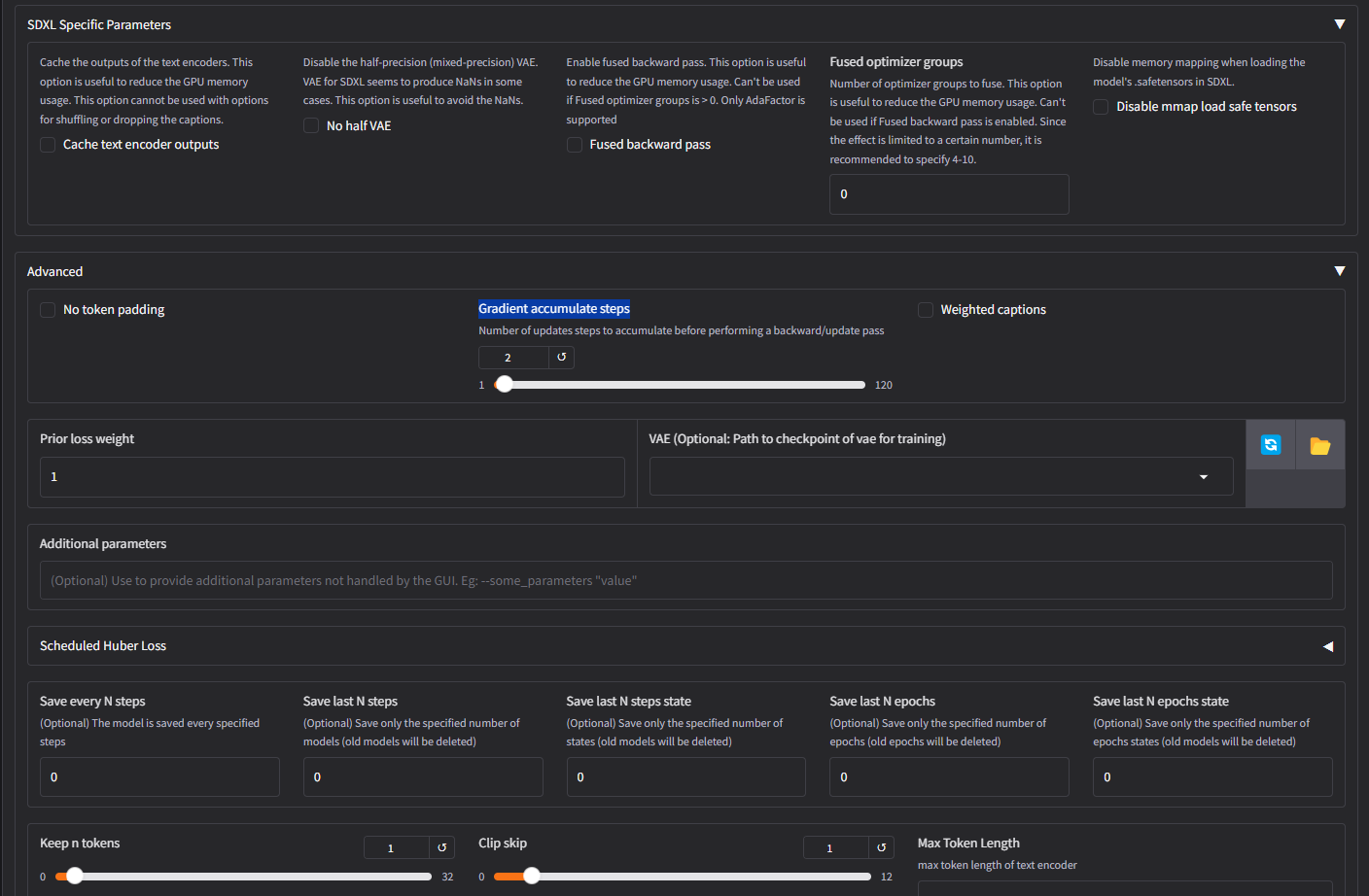
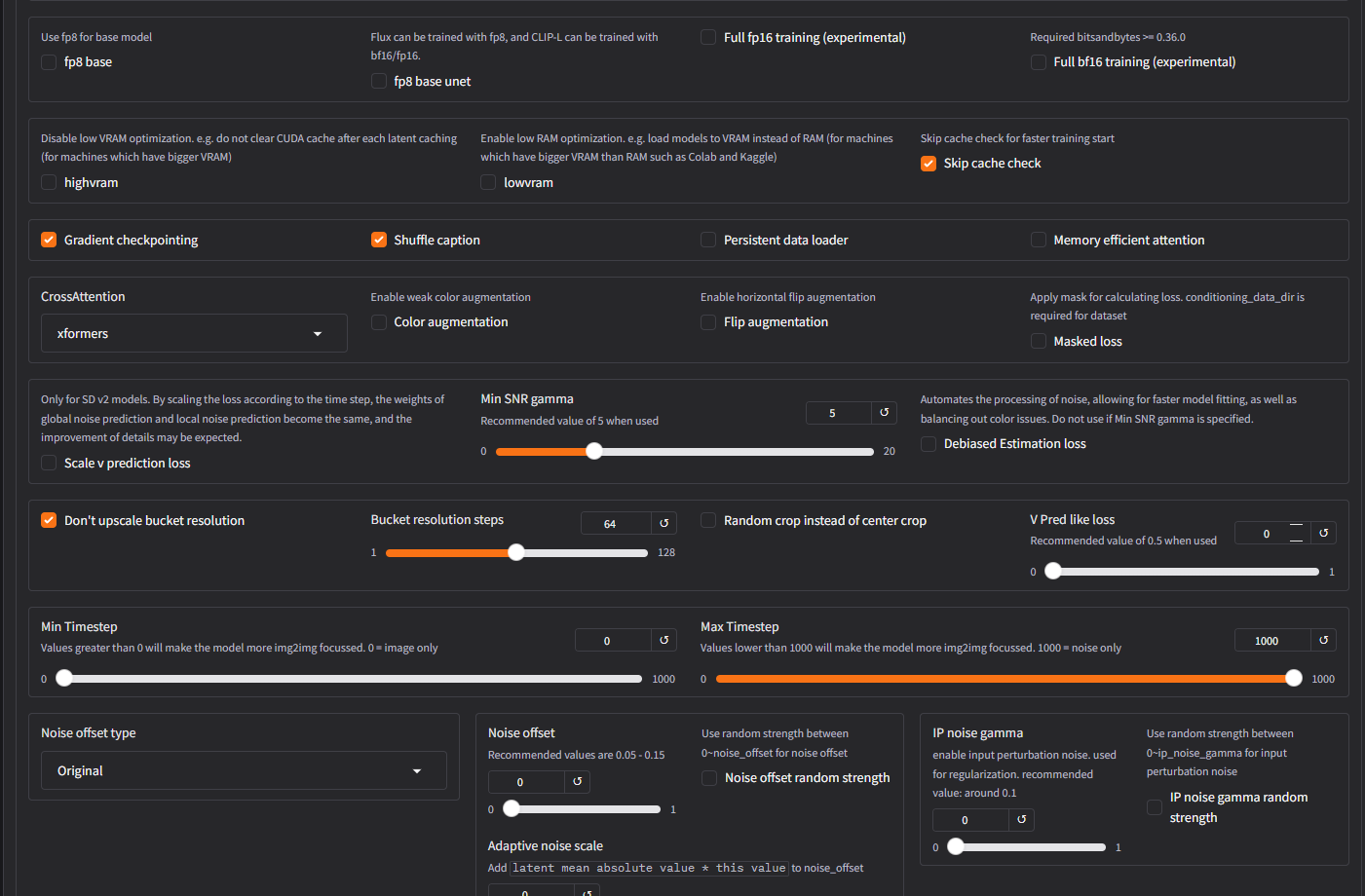
if I increase the text encoding rate and train again could that improve the results? I used the low vram settings for your tutorial, I just increased the repetitions from 40 to 100 on the first screen
 F
F A
A



 J
J L
L H
H