you'd need to photobash yourself next to random men, and then caption it in details
you'd need to photobash yourself next to random men, and then caption it in details
 FF
FF
 FF
FF F
F
 SFF
SFF
 VV
VV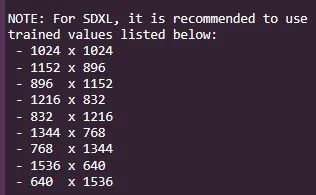 FFFFF
FFFFF D
D F
F DDD
DDD D
D D
D D
D
 �
� A
A FFFFF
FFFFF
 AAFFF
AAFFF EFFE
EFFE![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=40) DEEFF
DEEFF FF
FF EFD
EFD






