Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
Alright, then what are the settings for training through DreamBooth? As I understand it, your configs are more optimized and suitable for memorizing characters? Since for style, a more flexible mode of memorization is required, as well as detailed captions for greater flexibility?
And is it possible, for example, to use widescreen images for training so that it works better at this resolution? Moreover, this will simplify the process of preparing the dataset.
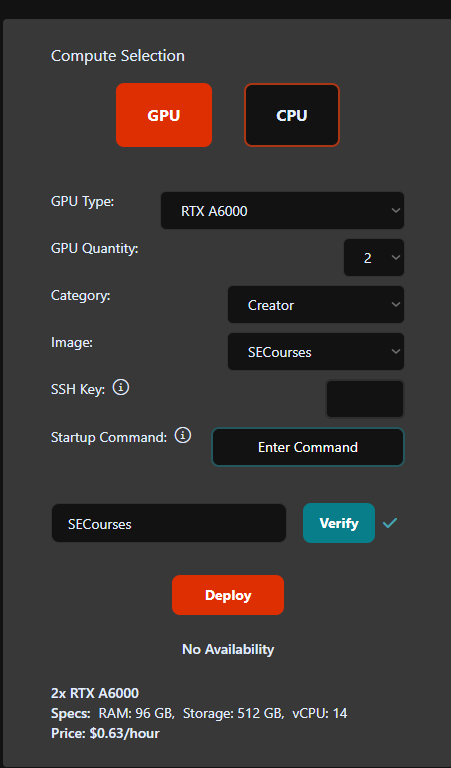
@NicB@SpecialHelper @Furkan Gözükara SECourses Hey guys I am currently following Dr. Furkans tutorial on how to do a Full File Tuning on Massed Compute and in the picture you can see what I want to deploy for the process.
1. But I dont know it the training will be faster if I use 2x A6000 with 96gb vram and more space. 2. I dont know hom much money I should put on the account for these trainings:
- 1x for me, 200 png dataset, various poses, expressions and clothing - 1x for my Brother, 100 png dataset, various poses, expressions and clothing (I want max quality possible)
And what parameters would you guys suggest me to use?
And I also don't know how to put money on the massed compute account and I have also connected my credit card
And also another thing that I would like to know is:
Can I close my Browser or even shut down my PC while the training is running on massed Compute? Because I saw that the the best training for about 250 images dataset will take about 30-31 hours per training
Just don't shutdown the VM instance in massed compute itself. It is like a separate computer for yours so everything will run as long as you don't shut it down
Our billing by default is set for automatic charges. You only get charged for instance that are on the running instance page. So you can set thresholds as low as $5 for recharge amount and minimum balance amount.
I was finetuning Flux, and at some point made prompt larger, and suddenly it failed when trying to generate test image after saving checkpoint. I wonder now, new prompt was only 88 words (356 characters), seems like all within limit. Maybe it was something else?
I try to train new character checkpoint using pixelwave and failed miserably, the new trained checkpoint is so much noise and blur seem like beside of Flux Dev original model, mix or trained model is very difficult to use as a training base
hi @Furkan Gözükara SECourses what is the best way to train multiple person or is it best to create a model for each person ? If second option is better what is the best aproach in confy ui to generate a single image with multiple model?
If I have 15 great 2048x2048 face pics, should I just these for training, or must I downsize to 1024 first? Any chance the 2048 pics will give better result or not?
Another thing, if I want the best possible lora, I won't loose details by first making fine tuned checkpoints, then converting? For this character I really want both, so was thinking of just doing fine tune, then convert the best epochs to loras.
I mean, if I use "sample prompts" in kohya ss, it will think this is Flux model, but as I have de-distilled, this needs different CGF strategy? Its like, in Comfy UI, I need different workflow, if I use de-distilled model?
I just like to sneak-peak early on how it goes but I guess I can just stop training at cehckpoints, render previews manually, and resume from state if needed
Hello everyone! Owners of the RTX 3090 and CPUs (WITHOUT integrated graphics), has anyone managed to achieve the training speed 7.3 s/it stated in the config by @Furkan Gözükara SECourses? Even when I don't turn anything off, I still end up using 1000GB of VRAM on Windows 11, even if absolutely no third-party programs are running. How it possible ? i got onaly 11.16 s/it with 24GB config file...
about VRAM, I notice one thing. I have RTX 4090, on 24GB config, I have 6s/it; Then I swap blocks to 12GB config, and have 6.7s/it, almost no difference, but now I have lots of free VRAM and can use my PC normally alongside training. Have no idea why is that so
 Z
Z
 N
N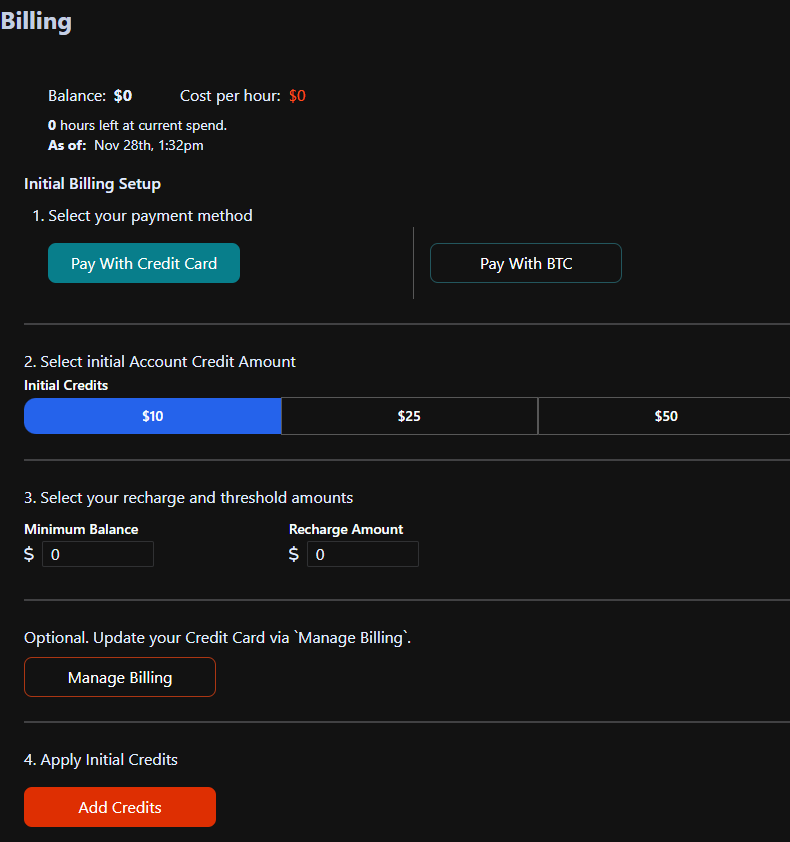
 N
N K
K
 F
F G
G �
�

 but I guess I can just stop training at cehckpoints, render previews manually, and resume from state if needed
but I guess I can just stop training at cehckpoints, render previews manually, and resume from state if needed



