When you trained the de-distilled model did you use guidance > 1?
When you trained the de-distilled model did you use guidance > 1?

@everyone Qwen Image 2511 is truly a massive upgrade compared to 2509. Full step by step how to use tutorial published and i have compared as well https://youtu.be/YfuQuOk2sB0 If you can upvote, leave a comment I appreciate that: https://www.reddit.com/r/comfyui/comments/1pv9snm/qwen_image_edit_2511_is_a_massive_upgrade/
Furkan Gözükara SECourses · 2d ago
@everyone After doing massive research our Wan 2.2 LoRA training tutorial is ready and published thankfully https://youtu.be/ocEkhAsPOs4 If you can upvote, leave a comment I appreciate that: https://www.reddit.com/r/comfyui/comments/1pscwvr/wan_22_complete_training_tutorial_text_to_image/
Furkan Gözükara SECourses · 6d ago
@everyone After doing massive research our Z Image Turbo LoRA training tutorial is ready and published thankfully https://youtu.be/ezD6QO14kRc If you can upvote, leave a comment I appreciate that: https://www.reddit.com/r/comfyui/comments/1pedr0v/zimage_turbo_lora_training_with_ostris_ai_toolkit/
Furkan Gözükara SECourses · 4w ago
 F
F J
J DFF
DFF CC
CC CCF
CCF F
F TFFF
TFFF YY
YY TFFFF
TFFFF TTFFFFDFDT
TTFFFFDFDT DFFF
DFFF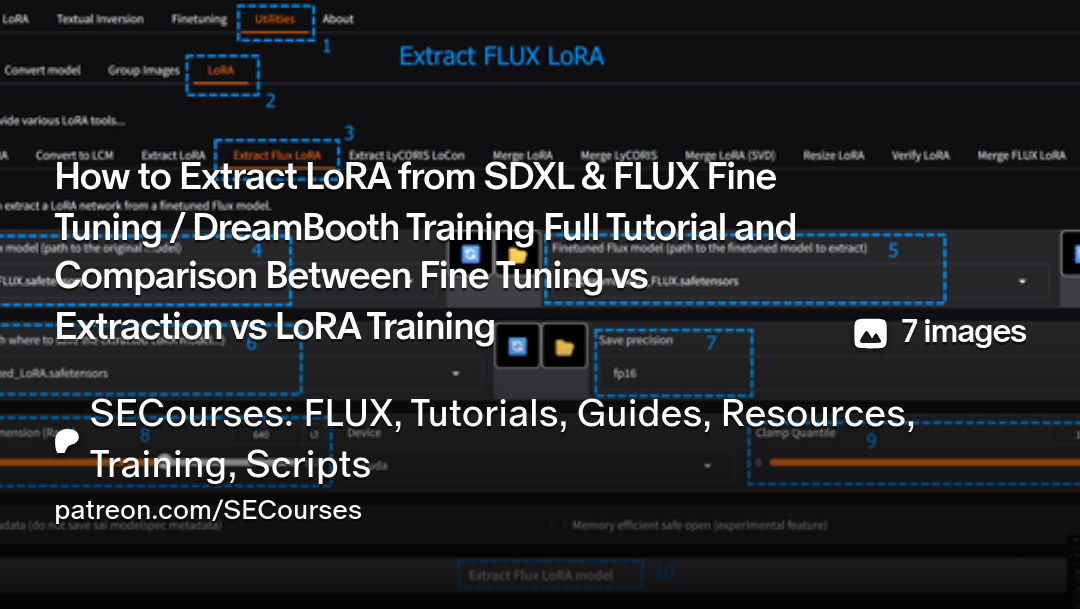 YFC
YFC D
D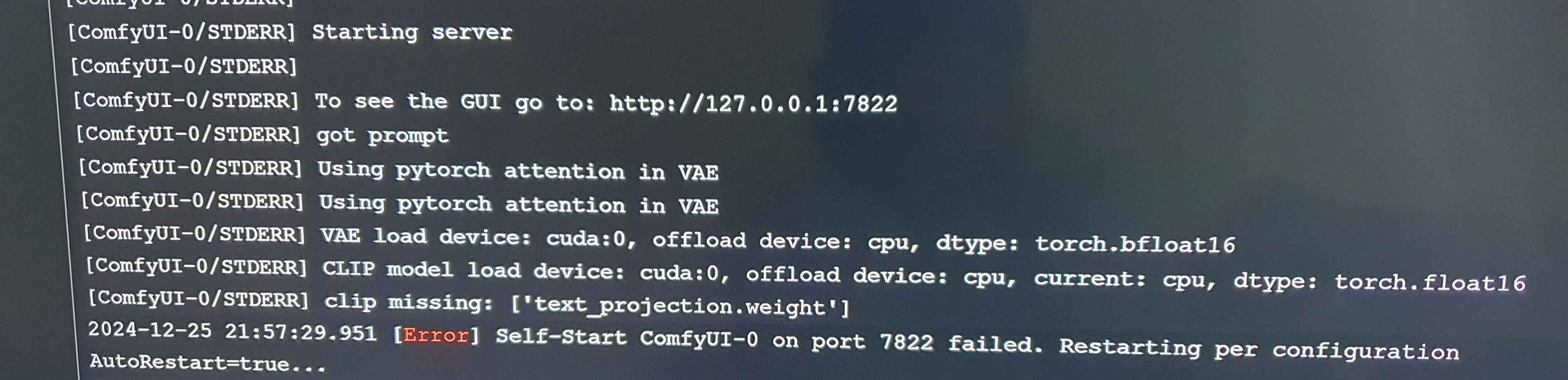 DFFVFV
DFFVFV--save_model_as="safetensors" \
--full_bf16 \
--output_name="momo_sdxl_dreambooth" \
--lr_scheduler_num_cycles=8 \
--max_data_loader_n_workers=0 \
--learning_rate=1e-04 \
--lr_scheduler="constant" \
--train_batch_size=1 \
--max_train_steps=10000 \
--save_every_n_steps=500 \
--mixed_precision="bf16" \
--save_precision="bf16" \
--cache_latents \
--cache_latents_to_disk \
--optimizer_type="Adafactor" \
--optimizer_args \
--bucket_reso_steps=64 \
--noise_offset=0.0 \
--gradient_checkpointing \
--bucket_no_upscale \
--train_text_encoder \
--sample_every_n_epochs=1 \
--sample_every_n_steps=500 \
--sample_sampler="euler" \




