Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
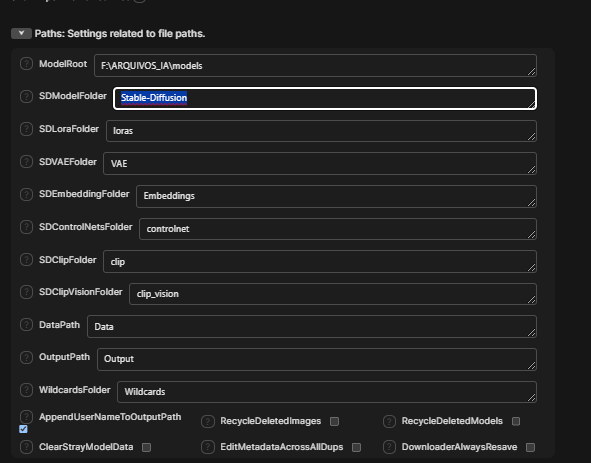
In the Models tab , find the burger icon and select edit meta data , from there set the architecture of the model to Flux Fill . For some reason Swarm doesn't do it automatically for different quantized versions
If I want to further finetune a lora or a model, what is the best approach ? Do i need the original dataset ? or can i give the model or lora new images without the old ones and continue further tuning ?
@Dr. Furkan Gözükara Is it possible to train a style and an object in the same Lora? You mention something about having two folders in the dataset preparation part and having a specific number of repeats for each of them.
What are the fundamental differences between kohya, onetrainer and simpletuner? I've only used ai-toolkit (kohya) because there are many online resources, but I've seen information about SimpleTuner being better.. however, I am not sure why/what the differences could be
@Dr. Furkan Gözükara can you suggest ? If I want to further finetune a lora or a model, what is the best approach ? Do i need the original dataset ? or can i give the model or lora new images without the old ones and continue further tuning ?
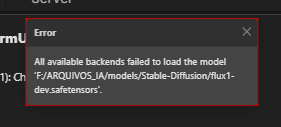
Are you, by any chance, using swarmUI through StabilityMatrix? I had a similar issue ( couldn't load any flux model whatsoever), and I highly suspect it's StabilityMatrix being wonky
Hi everyone, I need advice on setting trigger tokens and classes for two training datasets:
Hands Interaction
Dataset: ~150 diverse photos of peoples showing interactions like handshakes or couples holding hands etc. What trigger token would best represent these interactions, and what class should I assign?
Physical Product
Dataset: ~25 photos of a physical product (e.g., a cooker - utensil). What trigger token and class would you recommend for this category?
@Dr. Furkan Gözükara Hey.. Thank you for all the info you have on training models.. Its truly amazing.. I read in one of your posts about rank and flux loras but I didnt get the point really.. I am trying to prevent overfitting to use characters as comicbook characters.. The loras are amazing for realistic but I find that they are difficult to convert to comicbook characters.. You wrot a post about less paramters not sure what you meant.. Do you suggest a low rank/alpha to prevent overfitting or what did you mean ? Thanks
@Dr. Furkan Gözükara What's your recommendation for training with a minimum number of small number pictures? Any experinece with using 1 or 2? Effectively training a lora based on an AI generated character created with Flux.
Have you had experience with ControlNet for posing working successfully on Flux yet? I see Black Forest labs has released some files to assist with this, but was curious if you had worked with them.
@Dr. Furkan Gözükara Here a gen from a custom fine tune on large images I’ve tiled and cut into 1024x1024 pixel chunk separate pngs to capture every tiny possible detail from the up to 6K large images. It was an experiment and it went well with your config. Original image count was 15 for those large images and then after filing there were over 400 images. So this seems to be the trick to be able to train on any resolution images without losing any details.
made a new flux fine tuning model of my friend with 58 images, also gave great and trustworthy results. im wondering how low it can go. my first attempt with 15 images was too glass-skin like. but yea at least now i know that 58 images works well!
I've written a python script with chatGPT that will tile them with overlap and is also including the original full size image. Plus I'm using flux dev de-distilled.
@julius so yeah the fine details the model can't train on when only the full image is trained on it's own since the image gets automatically downscaled to 1024x1024 so the training will never see the full details in your dataset. I've taken a step further and have 3 different resolutions for the original image in 2x increments so that it will have 1024x1024 which is the full image downscaled to give the training the full context of the subject then a 2048x2048 version which will serve for 2x Ultimate SD Upscale training on 1024x tiles and then a 4096x4096 size tiled in 1024x1024 tiles to serve as data for training for 4x Ultimate SD Upscale and lastly the original resolution whatever it is to be tiled into 1024x1024 tiles with overlap to not miss any detail from the original dataset.
Has anyone used the nee deep face similarity app? It works great but I'm not sure what sort of numbers are considered very similar in terms of comparison. I know lower is better but is .3 good or still very off for instance?
 M
M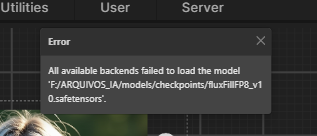
 A
A F
F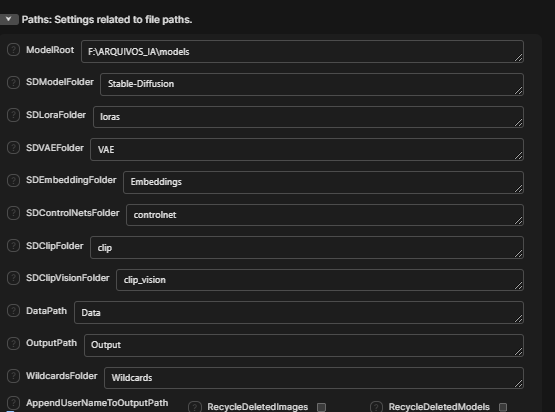
 S
S R
R �
� R
R



 M
M V
V K
K A
A W
W R
R
 .
.
 R
R J
J





 N
N D
D R
R V
V










