 F
F

 A
AOops, my bad  . Thanks
. Thanks 
. Thanks  A
A@Furkan Gözükara SECourses do you think to have 2 Lora people in one picture it's best to do face inpainting or regional prompting on Swarm? what will achieve best results
 F
Fprobably face inpainting
Awith yolo segmentation or individual swarm masking using flux inpaint model?
 M
M
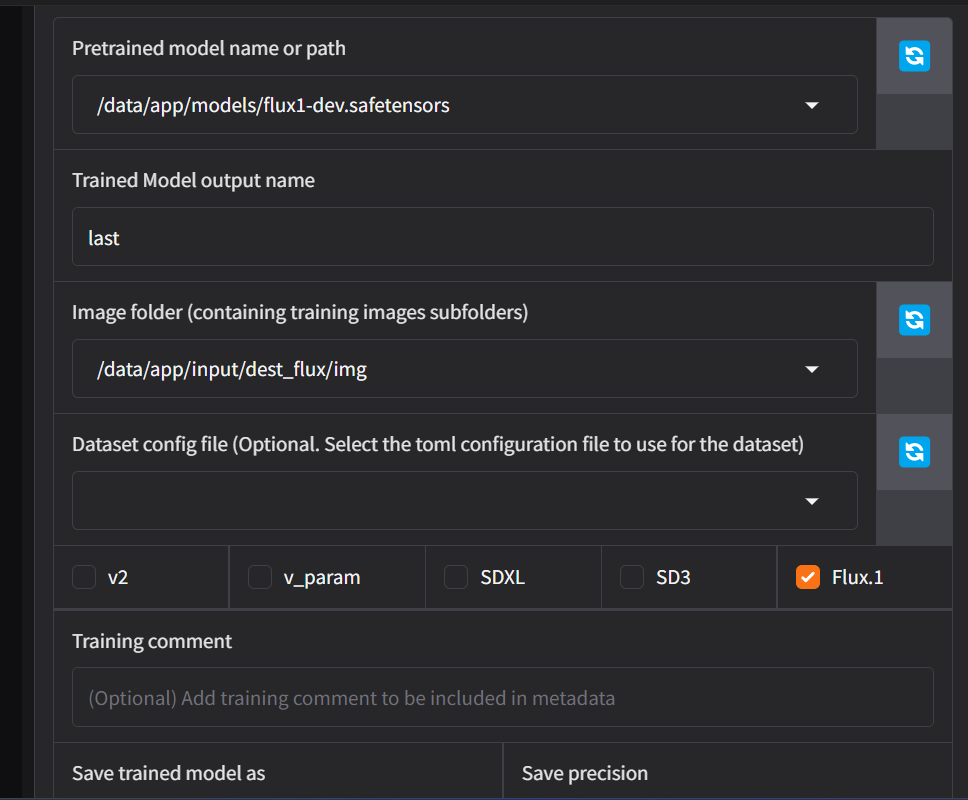
 M
M V
V@Furkan Gözükara SECourses finetuning can or cannot use 2 gpu? Not used in my case. Are there any settings?

 A
Ait can't
 J
Jyou guys ever get this error while training? in this session im running now, seems to happen almost every time, just have to click "generate" a few times and then it works anyway?
(4x RTX 6000 on MassedCompute, using Init Image)
(4x RTX 6000 on MassedCompute, using Init Image)


 P
PHi guys, I made this little toy for you: https://huggingface.co/spaces/elismasilva/mixture-of-diffusers-sdxl-tiling

 M
M@Furkan Gözükara SECourses have you tried the recently released flux pro model's api for fine tuning, wondering what your take is on that vs the dreambooth method in terms of quality
 F
Famazing
 F
Fpeople tested and it is inferior
Mi see, powering through your nearly 3 hour dreambooth tutorial on flux since yesterday haha
Fsana controlnet published
Fi should implement
![Dazzastrous [4090]](https://cdn.discordapp.com/avatars/871389071686135838/c4a5f4d81d9eeb18d856295d692e2c07.webp?size=40) D
Dnice
Freplied all emails and messages time to sleep
V@Furkan Gözükara SECoursesEDIT SOLVED: In the folder on massed compute there was hidden folder "cache" that I had to delete. then I could upload again. ORIGINAL MESSEAGE: I am trying to transfer checkpoints from massed compute to huggingface. I use the jupyter notebook. Works very good and fast. But I have one problem.... Some checkpoints I had to delete from hugging face. Then I tried again to retransfer them from massed compute to hugging face. but the jupyter always says: "Recovering from metadata files: 100%". and then its just skipping.... What do I need to do? is there an overwrite command? or do i need to delete metadata files and where are they?
Mdo you think a dreambooth or lora training of just text can create a reliable text generating model?
 .
.@Furkan Gözükara SECourses if I set the guidance scale to 6 in the kohya fine tune parameters, will that influence training and if yes how?
 K
K K
Kanyone else get python crashing when they load swarmui on the first time? running it locally
K4060ti... I think it tries to load the ckpt when i click generate image and then python crashes @Furkan Gözükara SECourses
Kmy disk that has swarmui and my .ckpts gets like 96% usage when i click "generate image"
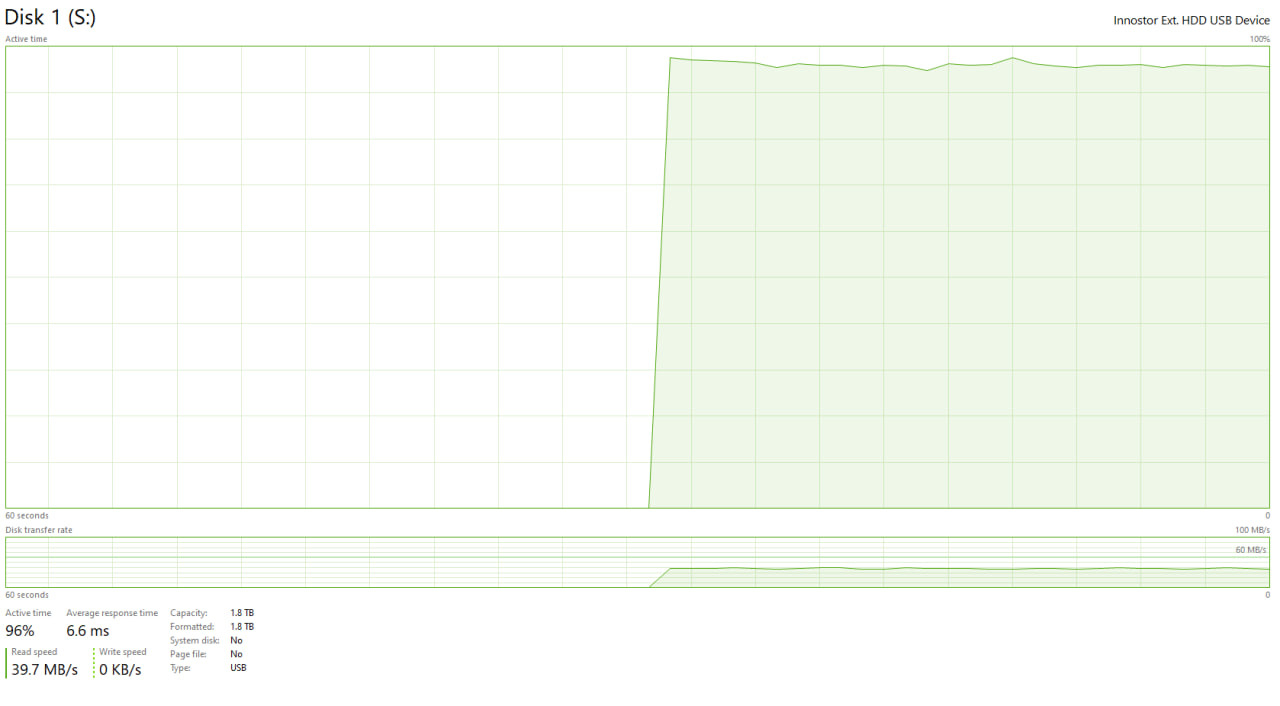 K
Kim gonna try with my SSD, i think that might fix it
A@Furkan Gözükara SECourses
Manyone here having issue when training a lora for flux using kohyass?
Mcuz i have been having lots of errors and issues
 C
C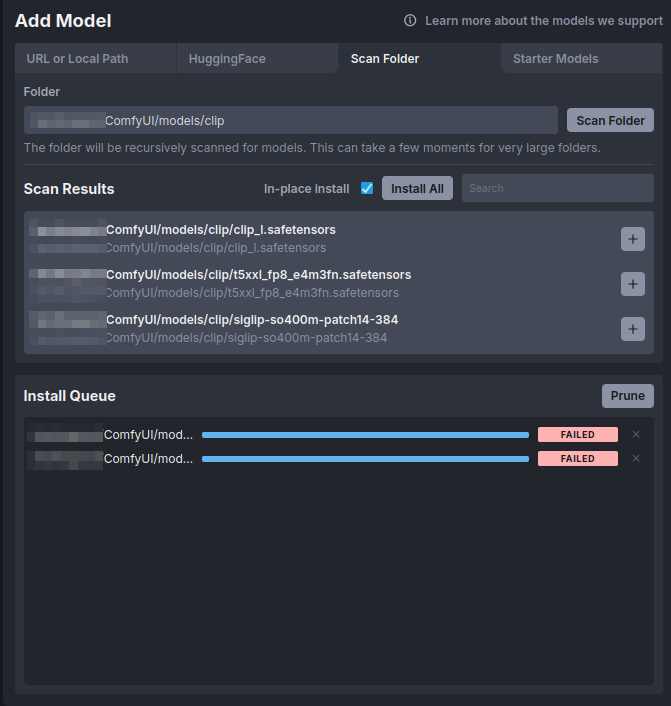 C
C@Furkan Gözükara SECourses hey, i installed invoke ai on my linux machine locally with your config. how do i import these clips and vae? i dont wanna download from the starter model cause i use finetuned flux model which does not have vae and text encoders baked in.
Csince i use linux desktop i used runpod script, and changed the directory from /workspace
V@Furkan Gözükara SECourses I did training of flux model. And get very nice looking pictures when generating the grid to compare the different checkpoints. I noticed though that most of the pictures are kind of serious looking (face) or only minimal smile. In my training set of 256 images the majority are more serious looking... so this then directly determines also that the generated images will mostly be serious looking? is the model then capable of more smiling or joyful expression generating? and does it need to be explicitly prompted? e.g. man wide smiling ....
 N
Nhi dr @Furkan Gözükara SECourses
may I ask if VisoMaster deepfake app is better than the usual Rope live that we had so far which was good enough ?
Checking it out quickly, i think VisoMaster is pretty much the same with Rope Live. They are using the same models, just VisoMaster made a better UI. Is that the case?
may I ask if VisoMaster deepfake app is better than the usual Rope live that we had so far which was good enough ?
Checking it out quickly, i think VisoMaster is pretty much the same with Rope Live. They are using the same models, just VisoMaster made a better UI. Is that the case?
Nalso is AuraSR GigaGAN 4x Upscaler Gradio APP better than SUPIR?
Fi am not sure you can ask hugging face 
Fnot sure you need to test
 F
Fyes it does
Fi am not sure how best way is comparing
 F
Fdid it fix?
.Does it make sense in certain cases to use a different guidance scale for flux dev dedistilled training?
Fyolo face
F3.5 is best
Fi compared all :d
Fpatreon has grids you can check
 F
Fwhat kind of error? i am training no issues
 F
Fyou need to put into accurate folders
Mgimme a sec