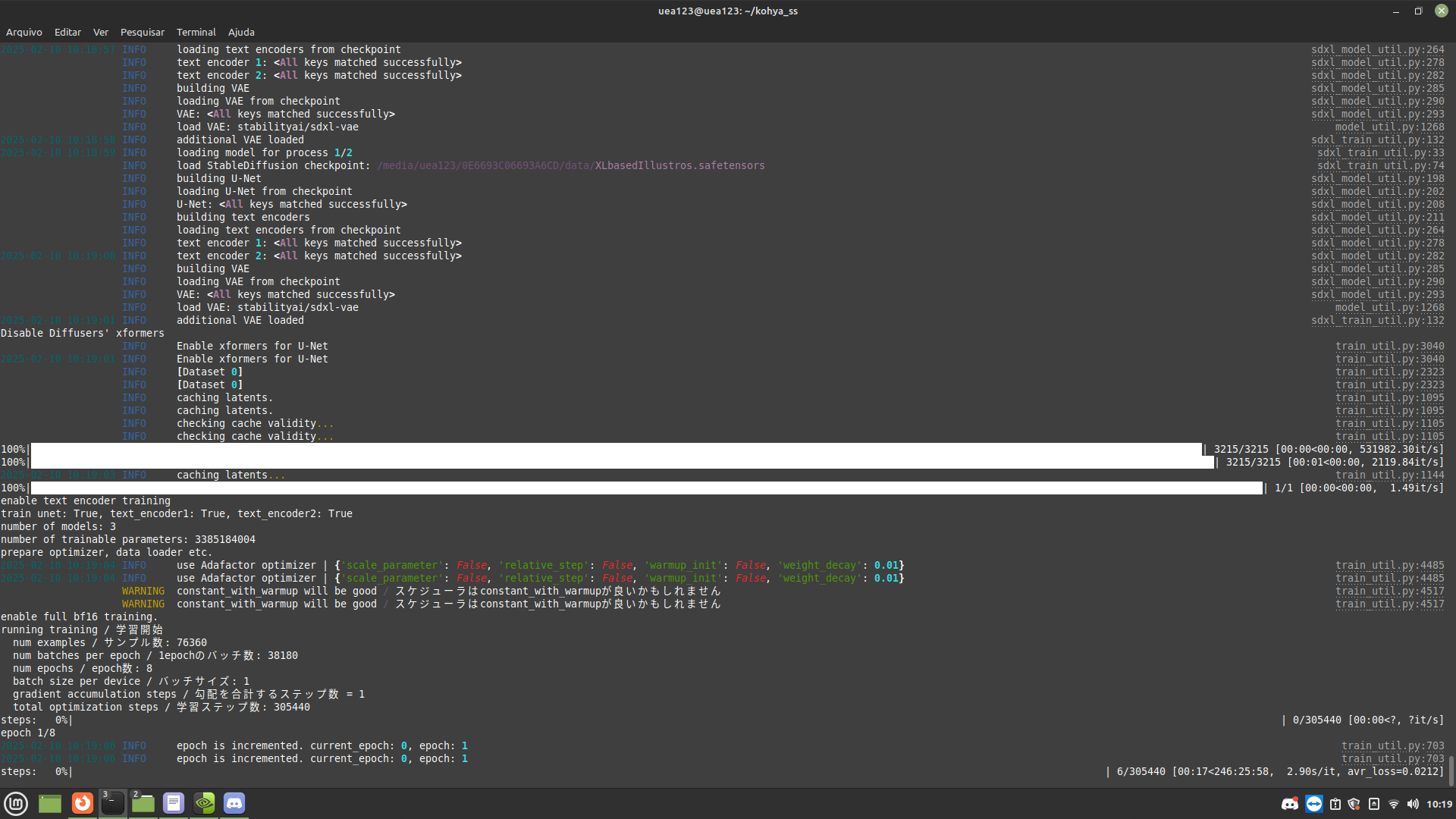
Does the global amount of steps change?
Does the global amount of steps change?
 P
P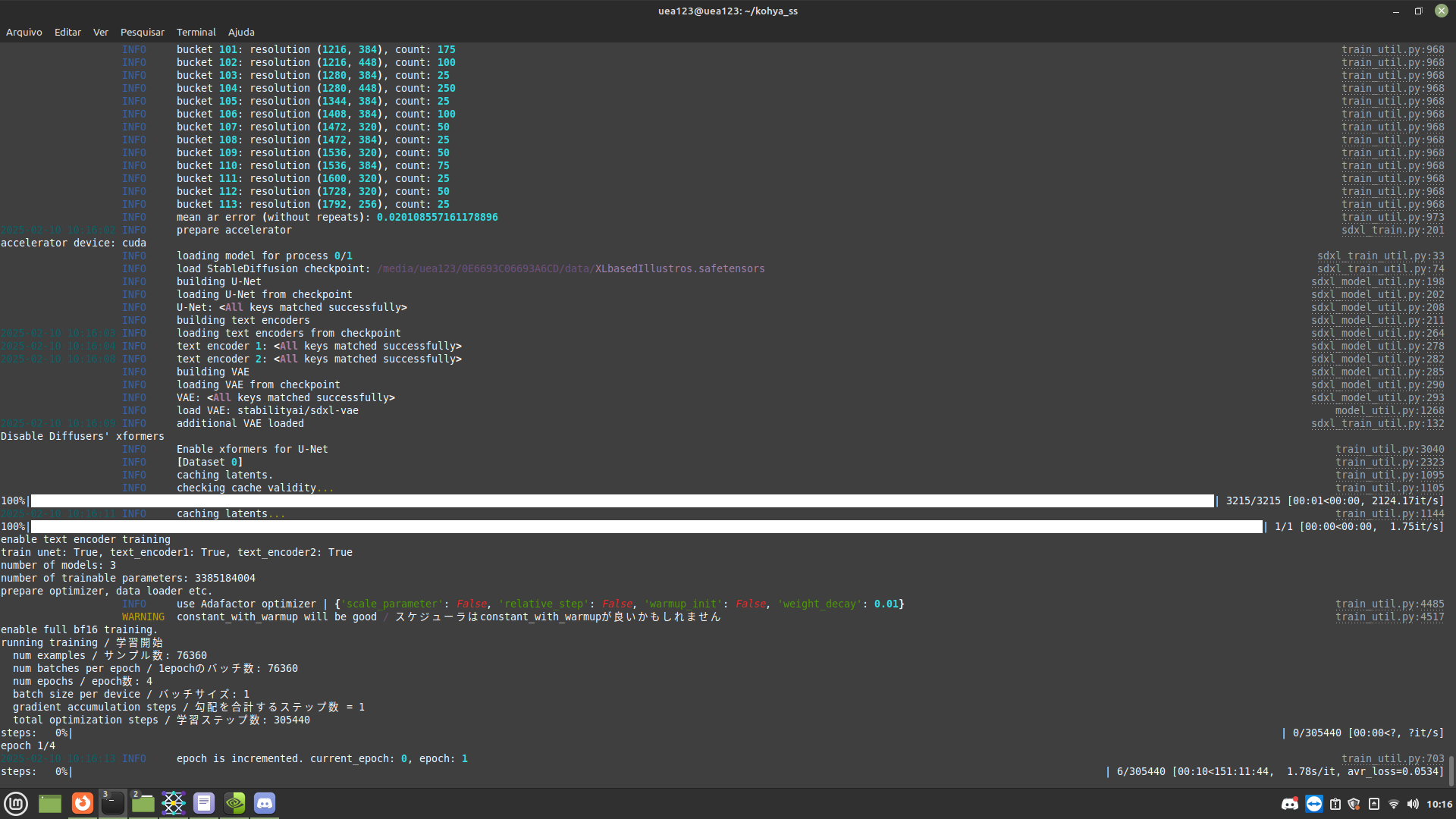
 D
D B
B
 FFFFFP
FFFFFP WD
WD RDFFFFFFDPFFFFFPFFDF
RDFFFFFFDPFFFFFPFFDF
 A
A H
H--zero_terminal_snr--zero_terminal_snr TTTDTTDFF
TTTDTTDFF DW
DW




