Hello Dr. Furkan, I tired literally everything, reinstalled everything, made a whole new pod, tried
Hello Dr. Furkan, I tired literally everything, reinstalled everything, made a whole new pod, tried mimicpc instead of runpod, same thing
 C
C AC
AC T
T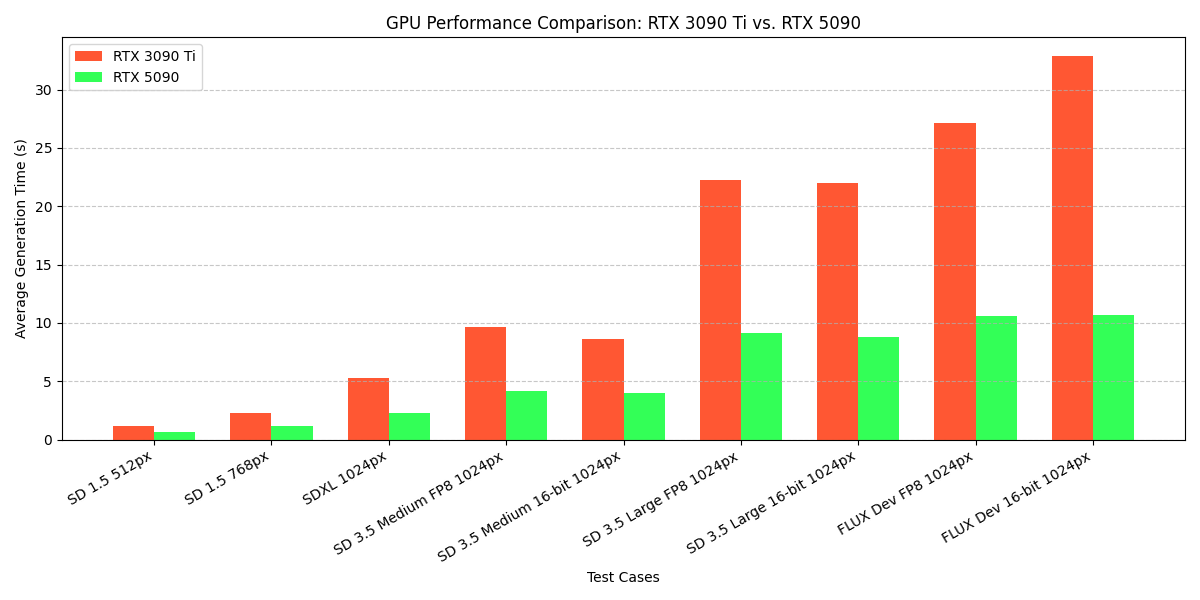
 K
K K
K KA
KA TAATA
TAATA MMKKK
MMKKK KK
KK KK
KK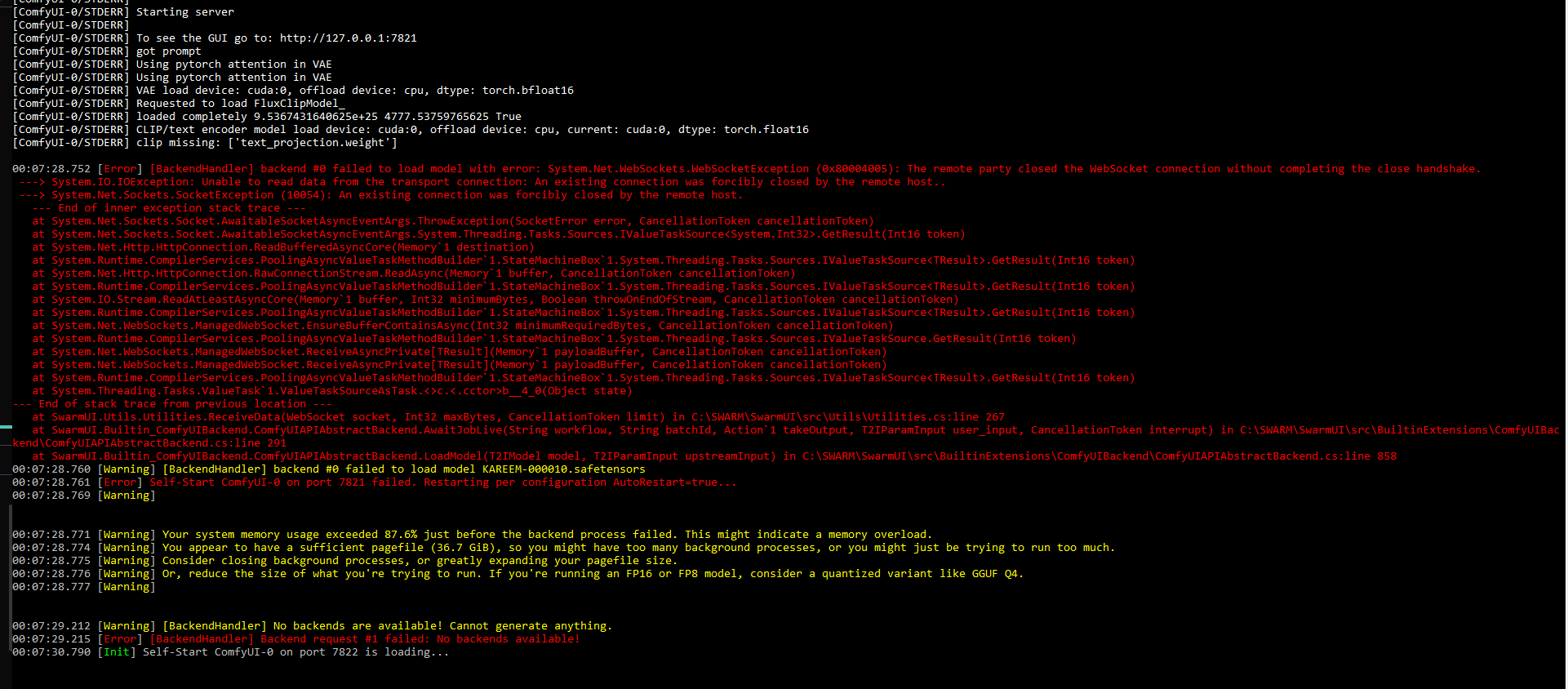
 N
N FFFFFF
FFFFFF FK
FK KFFFKKFKF
KFFFKKFKF
 JMMFFF
JMMFFF
 DFF
DFF









