
 F
F200 epoch probably not needed for that many images

 M
MIn the end, it turned out to be 180 images. I'm using 100 epochs, and right now it's at 50% of the training process at a speed of 6.6s per step. We'll see how the final result turns out
MWhat would be the best way to train a model for interior design? Let me explain.
I need to apply a specific product to a given room. For example, I want a Renaissance-style room with this product on the wall and this product on the floor.
I understand that in this case, it makes sense to train a highly structured model with all the individual products and, at the same time, the same products applied to different rooms. I assume that captions are important in this scenario.
What would be your approach to training a model for this application?
I need to apply a specific product to a given room. For example, I want a Renaissance-style room with this product on the wall and this product on the floor.
I understand that in this case, it makes sense to train a highly structured model with all the individual products and, at the same time, the same products applied to different rooms. I assume that captions are important in this scenario.
What would be your approach to training a model for this application?
Ffull research so best to keep experimenting
 A
AHey @Furkan Gözükara SECourses, I'm enjoying the 5090 videos you've done and had a question. Wondering if you're planning on doing a video comparing 3090 vs 5090 for fine tuning or lora training? Sorry if asked elsewhere discord didn't show if it had or hadn't.
 F
Fyep i will show
Fi made a quick test also
Fi am waiting official pytorh
FReddit
Explore this post and more from the SECourses community
 E
EHi! Don't know which channel to write this on. I'm training a lora and I'm wondering if I can stop the training and start a training on the latest save like you can when training checkpoint?
 E
ESave training state (including optimizer states etc.) when saving models
Save training state (not enabled)
Save training state (including optimizer states etc.) on train end
Save training state at end of training (not enabled)
Resume from saved training state (path to "last-state" state folder)
Saved state to resume training from
Save training state (not enabled)
Save training state (including optimizer states etc.) on train end
Save training state at end of training (not enabled)
Resume from saved training state (path to "last-state" state folder)
Saved state to resume training from
MI have finetuned flux-dev with 180 images of a character and 180 photos from various angles. Maybe it's not the best dataset because it didn’t have varied backgrounds. Almost all the images were just of the face without the body.
I'm having quite a few issues with prompts where I request a stylization. I trained a batch with 100 epochs and have 4 safetensors—I’ve tested them all, and I’m experiencing the same issues across the board.
When I ask for a stylized result, like a cartoon or anime style, it struggles to adhere to the prompt and often generates random things instead.
What could be happening? Thanks a lot!
I'm having quite a few issues with prompts where I request a stylization. I trained a batch with 100 epochs and have 4 safetensors—I’ve tested them all, and I’m experiencing the same issues across the board.
When I ask for a stylized result, like a cartoon or anime style, it struggles to adhere to the prompt and often generates random things instead.
What could be happening? Thanks a lot!
 T
Tthis is normal, nothing is wrong. You trained the model on realism data and it is inclined to generate it.
T18000 steps is a lot, you may want to try earlier checkpoints
Tyou may also try different prompt engineering, generate a lot of images and cherrypick from them secondary dataset to include in traning of second gen model with more stilyzed images in training data
 M
Myes I did it
MI did imagine that. But I watched @Furkan Gözükara SECourses tutorial and saw that he had some incredibly stylized images... I think he also only trained with realistic images. That's where my doubt comes from
Fyes buyt i never tried
Fits option is here
F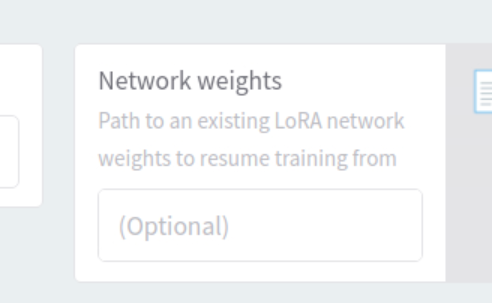 F
Fyes flux is very realistic
Ftherefore i recommend 2 step training for stylized images
Ffirst train, generate some good stylized images, and retrain on them
Fi had 256 images and dataset was variety . also still i had hard time and needed to find prompts 
Mthank you sir!
FThe grid test I am analyzing to find newer FLUX DEV training. This is not even including the first 10 different trainings i made  1176 images. I think we gonna have a better workflow than what we have with using more VRAM and more training time.
1176 images. I think we gonna have a better workflow than what we have with using more VRAM and more training time.
1176 images. I think we gonna have a better workflow than what we have with using more VRAM and more training time.
 R
RIn case someone is interested in creating LoRAs from Lumina2: https://huggingface.co/sayakpaul/trained-lumina2-lora-yarn, https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_lumina2.md (the code).
GitHub Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch and FLAX. - huggingface/diffusers
Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch and FLAX. - huggingface/diffusers
Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch and FLAX. - huggingface/diffusers M
MIts Lora train or checkpoint ?
 F
Ffine tuning atm
Fafter that i plan lora
 G
GFor multi-GPU training, does the set-up need 80gb vram TOTAL, or does EACH gpu need 80gb vram?
 F
Ffor fine tuning
Feach gpu 80 gb
Ffor lora not necessary 48 gb gpus works great
GGottcha, thank you!
GOut of interest, what causes the VRAM per GPU requirements to jump up so much? Just curious on what's going on in the background processes that requires VRAM requirement to go from 24gb VRAM per GPU from single training to 80gb VRAM per GPU for muli-traning
Fextremely good question
Fi asked this to kohya
Fhe was also not sure
THow does multy GPU trainign work anyways?
Each GPU has a copy of a trained model and perform traning steps independantly, so how in the end we are not gettign two separate models?
Each GPU has a copy of a trained model and perform traning steps independantly, so how in the end we are not gettign two separate models?
Tthey cannot possibly synchronize model state after each step, that woudl take ages (minutes)
TAnd if the models are just merged as last step - would that mean the final model can have questionable quality (missed local minimas and such)?
Fwith diffuser models
Feach models loaded fully into vram
Flike flux sd etc
Fso we have exact replicate
Tyeah, but how the state of each model loaded into GPU sync up?
TSo the training result in single model, not multiple models
Fthey are snyched at steps
Fso it is being increased batch size