Screenshot 2025-04-14 at 03.56.10
So my Hyperdrive connection with MySQL just started throwing errors, or well it started not responding. https://screen.bouma.link/fGflgtK5X2vH5wrX98nZ
From the Cloudflare Dashboard everything is "Active" (Hyperdrive) and "Healthy" (the Tunnel) and cloudflared also is runnign without any log output. But workers connecting throw:
Any clue where to start debugging this? The MySQL server is doing fine and nothing has changed on my end (I was asleep when the incident started). But I expected there to be some visible fault somewhere 😅 Cloudflare side issue?
64 Replies
Need your Hyperdrive ID, and I'll take a look in the morning.
I assume direct connections with a different mysql client work correctly?
Yes, in fact I removed the worker route to let it fallback to my origin and everything is working again (where my origin is talking to the same database). Luckily the worker is just a "optimization" basically so removing it is fine. Thanks for looking into this, I'll be trying to catch some winks too so be back in a couple of hours 🙂
The ID:
e091675e42a94e789ab05718442dce6aI also see all your metrics fall to 0 at that time. I see you're going across a tunnel. My first thing to check would be to restart the tunnel with loglevel=debug, to see if you're still successfully authing through there.
So restarting
cloudflared did seem to help. Which is pretty unfortunate. The problem did came back pretty quick though within a few minutes. Now running under debug log level but so far no output other then the startup.
is running at the moment.
Also opened teh connector diagnostics page in Zero Trust dashboard. No errors I can find there.
Access analytics show no failed logins for the Hyperdrive application. It shows many successful authentication attempts.
Database is still running perfectly and has ~45 connections left. No hyperdrive connections are made to it and workers is still throwing errors.
Restarting cloudflared and re-deploying the worker seems to have no effect.
Hopefully y'all will be able to tell me where the pain lies and what broke because I am at a loss 😅
The worker has been running without issues since saturday morning and stopped working sunday evening. I have not deployed the worker or made any changes to the server config for the whole of sunday.Ok, for now this is going into the category of "beta bug that we're still working to RCA". If it ends up being tunnel weirdness we'll figure that out, but I'm working from the assumption that this is a gap somewhere in how we're handling the wire protocol.
With that said (feel free to answer in DMs if you're more comfortable with that):
* Can you share as much as possible about your hosting, including specific MySQL version, on-prem vs PaaS, etc.
* Can you share as much as possible about your queries/access patterns. Query examples, are you using transactions, etc etc.
Thank you!
Interesting, okay cool. let me try and answer as much as possible, luckily it's IMHO a very simple setup which might help 🙂
- I am using
mysqld Ver 8.0.41-0ubuntu0.20.04.1 for Linux on x86_64 on a self-managed VPS not with a public cloud provider. It has both v4 and v6 internet connectivity. The tunnel is configured to talk to 127.0.0.1 :3306. I have configured it with a user with only select and show view privileges on a single database.
- I run 2 queries in my worker. As far as I can tell the first query already fails (which means it doesn't execute the second. I am using Drizzle with the MySQL2 connector. According to Drizzles logs it executes:
I am happy to answer any specific questions and/or run some non-destructive commands or even give you access to the Hyperdrive if needed (since it's read-only it's no problem). But of course if we are arranging that we should move to DM's 😄"Magically" started working again
Man. I'm gonna have your ID memorized by May. I can tell.
Not sure that's a good thing... 🫣
We haven't released any changes since yesterday, to be clear.
Oh...
I did do an deployment this morning
Worker or Hyperdrive?
Worker
Okay. That shouldn't interact with your Hyperdrive config at all, really. Just for context.
I'm going to start with another run through of logs for you when I get to my desk this morning. I want to see how that all looks.
I ran yarn upgrade (not seeing mysql2 in there or other related libs from a quick glance) and I also lowered the compat date to
2025-04-02. No actual code changes. In case it matters. Let's see how long it keeps working this time then! Also not touched the MySQL server at all.
So not even 3 hours from the looks of it.
I did notice when looking at my MySQL server process list that when the first errors started rolling in there were 2 connections, and then 1 and now 0. It took a minute for requests to start consistently failing too. Guessing some of it was also the query cache. But now 100% failure rate again.
In cloudflared logs I see:
Check MySQL values and wait_timeout is 8 hours. Not sure if other timeouts could be in play here which is what my first thought went to seeing this behaviour.
I would still expect Hyperdrive to handle this and create a new connection but maybe it detects a max_connections situation wrongly here. But I am now assuming based on nothing... I'll let you do the actual root causing here!Agreed at least that Hyperdrive is designed to drop bad connections and spin up a new one. That's a good angle to pursue also. Independent of why things fell out of sync somehow, why is it not detecting that and doing the obvious thing.
I'll keep you posted
Quick followup here. We're adding some additional robustness to the health checks and autorefresh behavior for MySQL connections. That'll go out in our next release, starting either today or tomorrow and done by Friday/Monday.
Hope to see stable service after that 🤘 Thanks for the update!
@Alex The release is out, we should be in a better spot for dropping/replacing bad connections for MySQL configs. Please let me know how it goes for you.
Very much going in the right direction! https://screen.bouma.link/TmpHFwkgHQv2KM6CDTsK
Let's see how it holds up over the weekend!
Currently seeing ~22 connection to MySQL, which is way more then before (don't think I've seen more then 2 before). So something is definitly better!
So no we are moving the other way 🤣 I have a 51 connection limit on my database, which should be way plenty but Hyperdrive is keeping 30+ connections idle for long times: https://screen.bouma.link/V2zQ00XFj5yCB9j0jYnH
Some connection have been idle 4+ hours
In addition it also had ~14 actively (within last 60s) connections
That broke my app 🙈 And this time not just the worker
Well that's not supposed to happen. We drop idle connections after 15 minutes.
Generally the way this should work is that it will aggressively open connections whenever all available ones are in use, up to 60. Anything that hasn't had traffic in 15 minutes should be disconnected, though
I'm assuming you don't have any middleware in your stack that'll hold things open until it gets an explicit close message?
Since I am using Drizzle, I am not a 100% sure what it exactly is doing ofcourse. And I am not explicitely closing the connection to Hyperdrive either. But I also wouldn't expect a single instance of an isolate to live 4+ hours without any requests. I am at least not doing anything with the connection explicitly. I am even connecting in the
fetch handler opposed to in the global scope.Hyperdrive exists separate from the isolate. Couldn't have warm connections otherwise.
But no, it should only live for 15 minutes without traffic
I'm planning to bring this to the team, and we'll dig in starting today.
Happy to provide any details if that helps. I can also share the worker code if that helps.
I think we've found the root cause of this issue, will let you know here once we've confirmed that and released a fix for it. Thanks for your patience
No worries. Happy to “help” nail this down by breaking it.
No quotes needed, every problem you find is one less that everyone has to deal with. We very much appreciate it.
Hey @Alex , sorry to bother you!
I'm using Drizzle with Hono, MySQL, and Hyperdrive.
Could you help me confirm if my setup looks right?
I'm running into similar issues too.
Thanks in advance.
This is the code
The only difference from my code is that I did:
Not sure that makes a difference really but it's a difference.
The problems are mostly gone by the way, it has been running pretty good for the past few days
Dont we have to close the connection on every request like the doc suggests?
As far as I understand. No. Also: https://discord.com/channels/595317990191398933/1363026034240262266/1363311277333549280
Once your worker finished the connection is killed anyway. And remember it's the connection with Hyperdrive not your SQL server. So it shouldn't matter too much.
Thank you very much for the help
The release with the fix for idle connections has gone out. That should be looking better now. Kudos to @knickish for finding and fixing that.
Please let us know if anything else pops up for you!
Excellent! I am so far super happy with the stability. Will report if I still find problems. Thank y'all!
So this is going great. https://screen.bouma.link/LjQP9fhwVm51fx60LNbf
This is over the past 7 days
9k errors sounds like a lot but a lot is invalid request methods and things like that. Hyperdrive has been rock solid!
That is awesome to hear. Thanks for sharing, I'll pass that to the team. :MeowHeartCloudflare:
If you're willing to speak to it a bit, would you mind sharing what you're using Hyperdrive for, and what you used prior?
For sure. I run a url shortener (also don’t know why, side project gone wild) @ tny.app. It allows custom domains. I am using fly.io for that infrastructure to have some global-ish coverage (unfortunately not using Cloudflare for SaaS because pretty costly and need enterprise for apex routing) but all requests went back to AMS to talk with my application servers. I’ve now replicated the redirect code serving redirects directly from the worker hence why I needed Hyperdrive to make this change super easy without duplicating my data to KV. And with the added caching it’s now pretty fast all around the world compared to just the fly.io->AMS it now goes fly.io->CF->AMS(Hyperdrive)
Damn. We went so well... just took down my application fully again by exhausting the connection limit. https://paste.chief.tools/a1ce4bd1-7d96-43d3-9fca-19d97f9c4b74/markdown
It is supposed to not do that right?
This time no very old connections. Just many of them.
I've now been smart and added a limit on the hyperdrive MySQL user to prevent this from happening. But it seems like for some reason Hyperdrive is maintaining a far larger connection pool then before. And this time all actively used, last time many were idle for hours. Not the case now. No change in traffic to the worker.
How many in total?
It should top out at 60. Maybe 120 if the overall system is stressed and you spill to a second pool
Ah, it went to 48 total. But my server is limited to 51 connections I believe
I somehow read the ~20 connections and also read that it woult take any max connection limits into account. But I now see that this page says it can go up-to ~100 connections https://developers.cloudflare.com/hyperdrive/platform/limits/
Ahhhh, makes sense. Right now there's not a good way to put or change the limits on how many connections Hyperdrive will take. I'd be happy to lower yours with our next release, if you need. Though it sounds like you've already solved the problem in what would amount to the same way.
Yeah I should've done that immediately, this is on me 🙂
Ah yeah this part I read: https://screen.bouma.link/mRPRzdKlgdgMcbf5852p
We used to do one pool per region, long story that we've written a blog about if you want the details. With regional pools, of which there could be up to ~8, we limited to 20 per region. Since then (a couple months ago) it's been 60 with some wiggle room to 120
And I assumed this read the max_connections setting from my database, but maube this is more special casey for the serverless databases or something.
This makes sense! So am I making Hyperdrive's job harder/impossible now with my self-imposed connection limit?
Maybe a little, not a lot.
When a query comes in, Hyperdrive will (in order of preference):
1. take an unused connection out of the pool if one is available
2. open a new connection, if you have some left before you hit your limit
3. wait for an existing connection to free up, if you're already at your limit, up to a 15-second timeout.
With your self-imposed limit, it'll now try for 2 and fail, instead of waiting around for 3. For your scenario where your DB's limit is lower than 60 anyway, the query's going to fail at option 2 either way, and now you won't cause problems for anything else sharing your DB. What would be ideal here would be for you to get to 3 since you'd likely get a successful result that way, eventually.
Note: this isn't MySQL-specific, this is how it works for Postgres users too.
CC @thomasgauvin -- another one for user-configurable connection limits.
Awesome, I appreciate the details. Really cool tech 🙂 And makes total sense too. Very reasonable. I never had a use for soo many connections since I've never run my database so globally. If you take into account how many CF DC there are, 120 max is downright low 😛
tx-mode poolers get a lot of mileage out of each one, it's pretty cool to see how high some people crank their traffic before we need to give them limit overrides
I am a MySQL guy, but I've heard people getting some crazy mileage out of their pgBouncer setups.
I eventually for my use case need to switch to KV or D1 maybe but Hyperdrive is performing excellent as an inbetween.
running into similar issue on our staging environment. we have a similar setup, using tunnel + hyperdrive cc @thomasgauvin

Is this happening consistently or sporadically?
sporadically.
cc @AJR
We're investigating intermittent networking hiccups, we recommend implementing application retries in general and are actively working to improve this area
more info: i noticed this always happens after the worker has not received any request for a while... so it looks like hyperdrive returns a stale connection @AJR @thomasgauvin
the request takes a while before it fails, sometimes it takes a while and ends up successful. in summary the latency sucks sometimes....also if you have any pointers on the application level retry it'll help because we are going live in a week.
we are using drizzle + mysql2 by the way
i think my assumption is correct, i added a health check query immediately after initializing a connection. This is one of the request traced.
Note: the health check is not a ping(), i realized the ping might stop at the hyperdrive endpoint and not reach the origin database, so i used this
SELECT 1 as health_check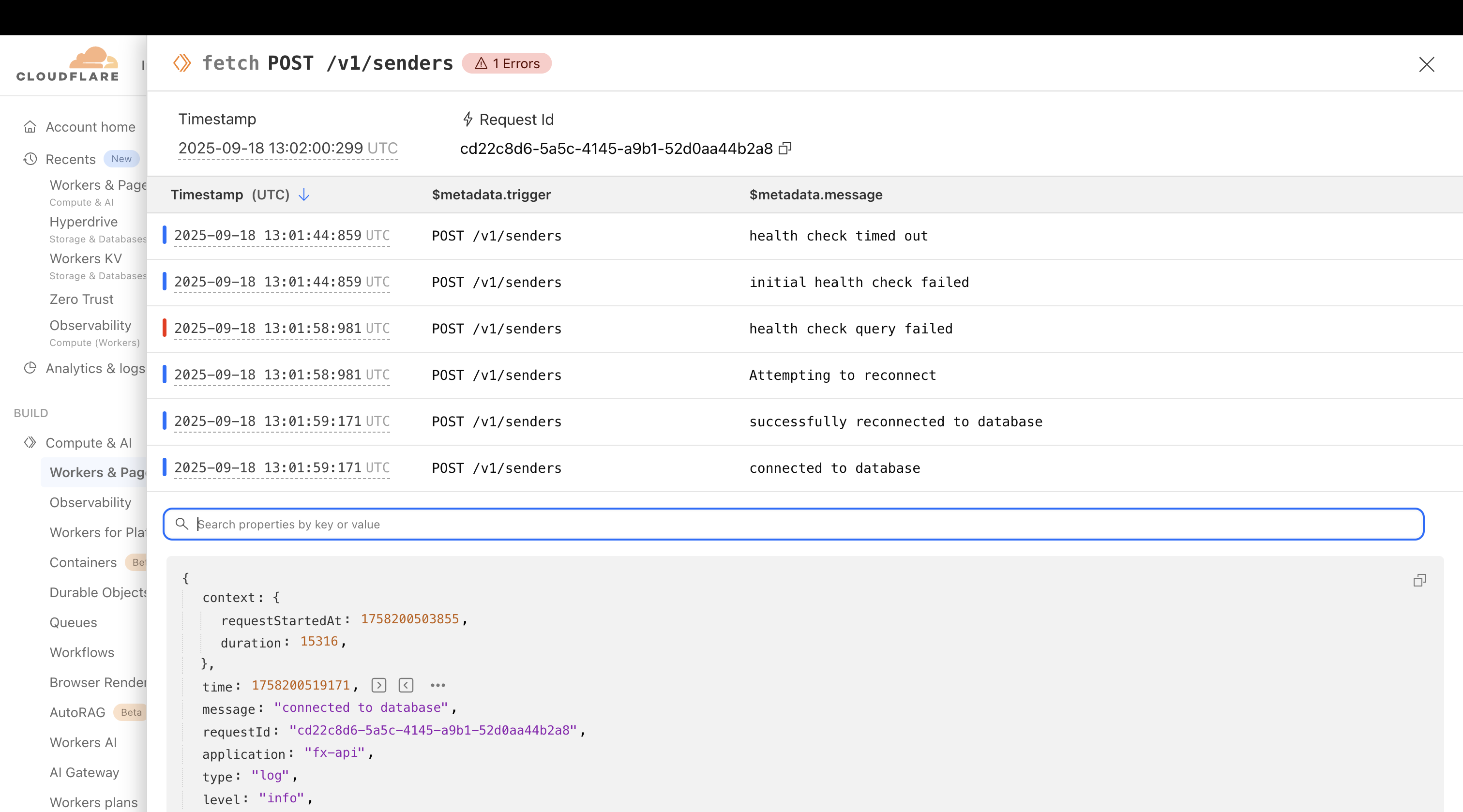
Interesting. So the connection is getting timed out while sitting idle in the pool
Our recent additions should catch that.
Can I ask for some details about your hosting? Vendor, version, settings around connection timeouts, etc.
you can send a comprehensive list in the DM i'll send it to my DevOps team. the vendor is AWS RDS
@knickish can you pull together what all you'd want to know, here?
also if you notice between "initial health check failed" and "health check query failed", there is a 15 secs delay, then a reconnection attempt. i'm trying to end the connection but it seems that also hangs till this error is returned:
error: {
message :"Connection lost: The server closed the connection.",
code:"PROTOCOL_CONNECTION_LOST"
}
do you have any idea how i can reconnect without waiting for response from the connection.end()here is a gist of my db connection file https://gist.github.com/umar-abdullahi/6a0fb0dc9e140a065d029ed5a2d64e14
Honestly I'd just put that on a timeout and make a new connection. Connections to Hyperdrive are incredibly cheap and fast to stand up a new one.
The only thing that might run you into is the 6 egress limit if you're doing a bunch of them.