hey! I am using the crawl endpoint with
hey! I am using the crawl endpoint with a 1000 page limit. I can see I'm being charged 10k pages.. Massive hit on my quotas. How can I get some help ?
31 Replies
hey Alp! sorry, we're a bit behind on tickets and today is a company holiday. what formats are you using?
also can you send me a crawl ID with this issue?
153c46bd-d229-4f0f-8449-9460ffa3251f
b04e64f0-56f1-4f03-a7d6-035ea70060df
2d7a6689-f0ab-4ac7-90e8-d4d9ee1fa4b1
f551920c-b116-47b7-93bd-fc256a51e6b3
Here are some. I am using html. If you look at my usage, You'll see a massive spike and then it goes away
thanks @mogery !
you're setting a limit of 10k, not 1k
at least that's what's arriving on our end
can you send/review the code you're using to make the requests?
I didn't move to v1 (didn't know about it). Could it be a v0/v1 discrepancy that is auto setting 10k? Cause I do not have that
should probably not be the issue, but moving to v1 should be done ASAP as the v0 API will be disabled relatively soon and we are no longer shipping fixes for it, nor are we running tests for it
got it. Is there a way to double check the problem? I do not have a single instance where 10k could've been set. What is the default value?
++ should I have expected some email from deprecation on this? I totally missed it and was wondering how I would notice this change from v0=>v1
it actually looks like you're using v1 already
since you're using version 2.0.2 of the python SDK
I think it auto-bumped the version, but the input is still v0 style
(surprised it doesn't fail btw)
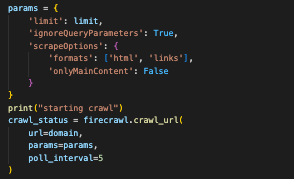
looks like you are not setting a limit at all in the request you're sending us
that is v1 style input :)
oh it is
then I'm extra confused 😄
thanks for the clarification
but yeah, none of the params are making it to us, only the URL and the origin which is enforced by the SDK
let me check the SDK code to make sure we didn't mess anything up
ah, so -- the major version bump changed the API in a way that doesn't trigger the error but negates the crawl parameters in the way you pass them
this is the new function signature
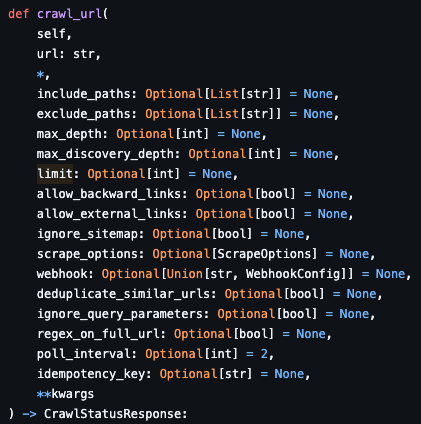
so you would need to do
firecrawl.crawl_url(url='whatever', limit=1000)
forwarding this internally, this should be fixed, but might be better to right now move over to using the new footprintmoving over asap 😢
thanks so much for such a quick investigation
ofc! how many credits would you estimate were wasted? would be happy to add those back to your account
I wanna follow-up about all the credits I lost (I ended up spending +55$ cause I'm out of them 😦 ). Can we sync about that?
of course! can you send me your firecrawl e-mail in DMs?
I saw 5 instances of 10k -- probably 50k. Either way -- that'll be plenty for me until my next cycle 😄
just did
gotchu -- sent 50k. was that +55$ from auto recharges?
yeah I'd say 55k-ish 😄 given my usage the rest of the time on average.
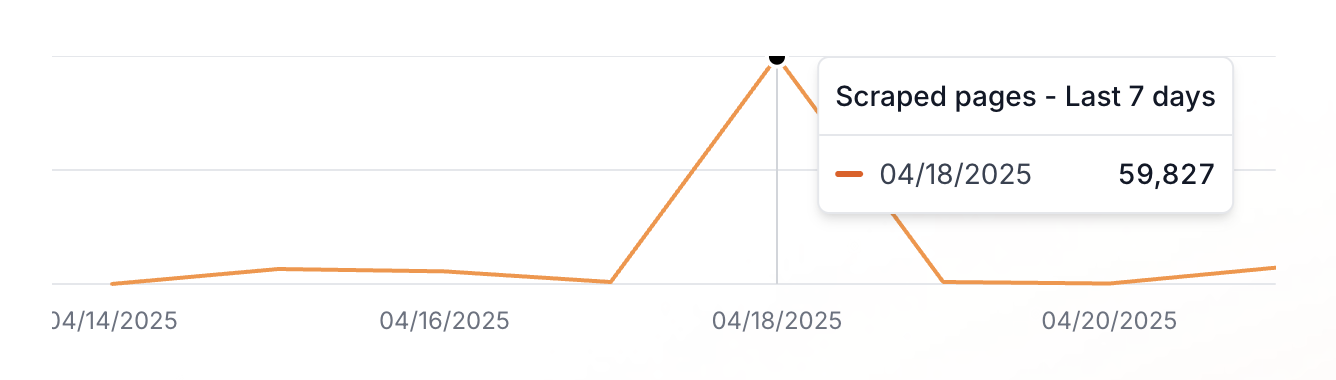
thanks so much!!!
I double checked. It's actually slightly more than 55. Here they are

alright -- do you want me to refund those packs and cancel them?
yes please 🙂
done -- refund should arrive in 5-10 business days according to Stripe
im hotfixing this in production so should be live in 15 minutes
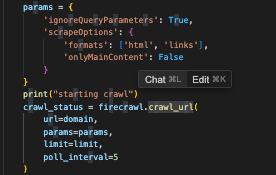
I'll fix everything else in the normal train. Making sure this would ensure limit isn't impacted?
looks good, but also needs
ignore_query_parameters=True and scrape_options={...} to be in the method args
by the way the 50k credits i issued will not reset at your billing cycle so you can continue to use them even if they do not run out this cycleoh woah. Thanks so much! appreciate it