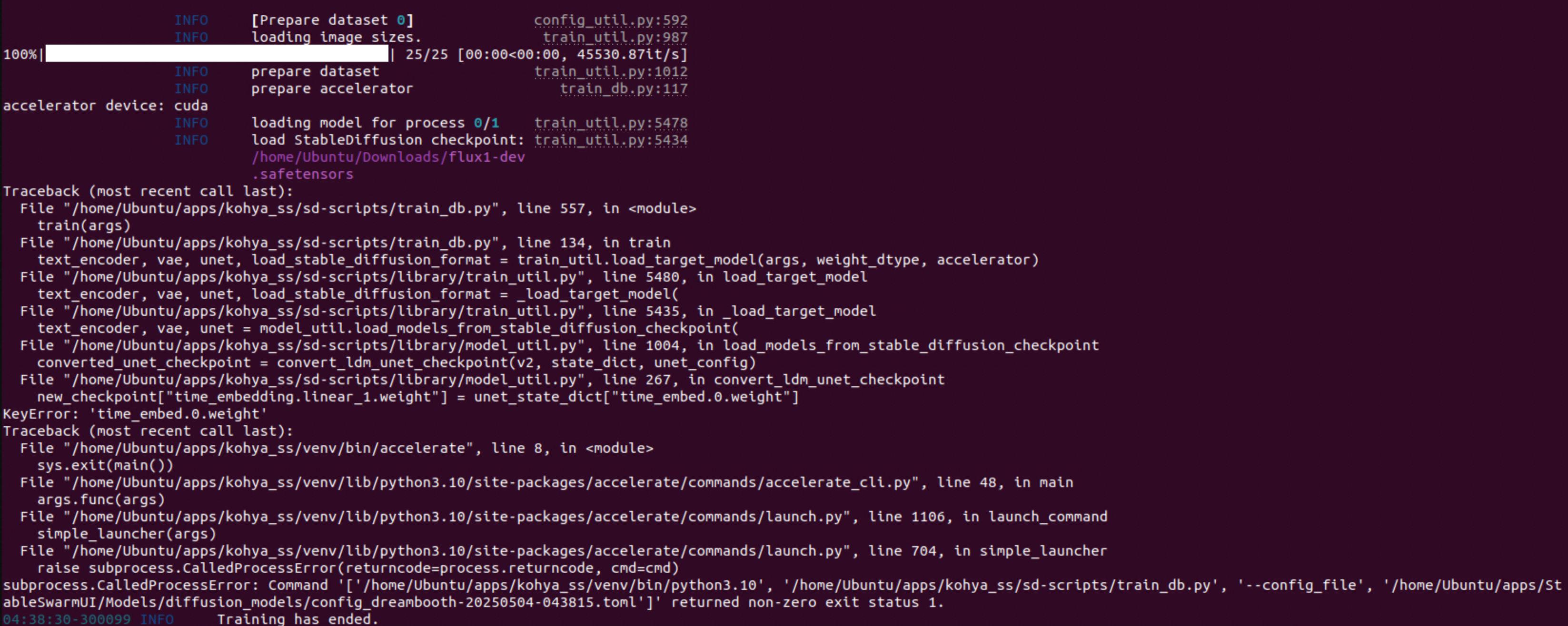
do I still need regularization images when training checkpoint/lora for a woman using sdxl checkpoin
do I still need regularization images when training checkpoint/lora for a woman using sdxl checkpoint?
 JJ
JJ
 J
J ��
��
 ��
�� FFF�
FFF� maybe I'll try masked training too.�
maybe I'll try masked training too.�
 PFFFF
PFFFF FPFFFF
FPFFFF https://www.patreon.com/SECourses
https://www.patreon.com/SECourses ��F
��F J��JJ
J��JJ S
S SFFFFFFSFFFF
SFFFFFFSFFFF SSF
SSF




