make sure to save once every n steps
make sure to save once every n steps
 E
E
 F
F E
E FFFE
FFFE �
� FFFFFE
FFFFFE TEF
TEF FFE
FFE FF
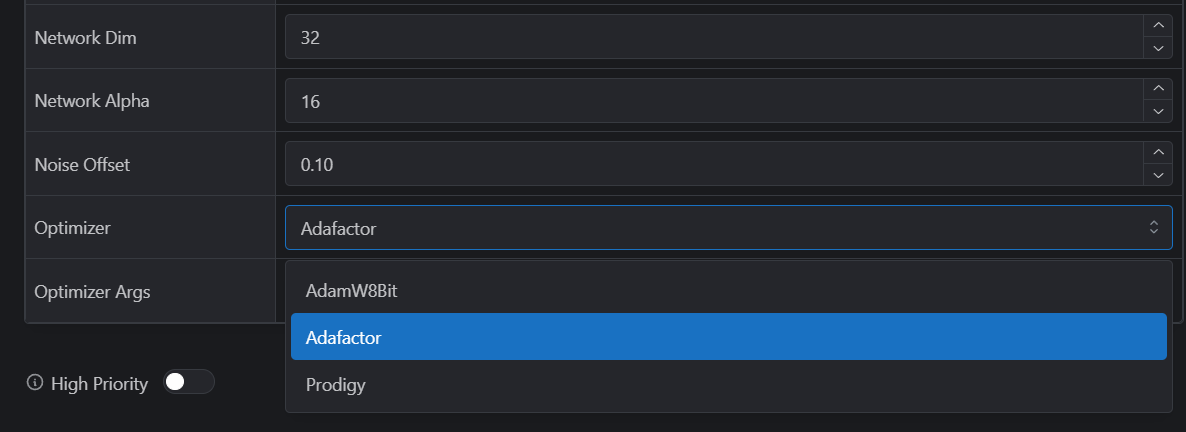
FF JFFJE It's crucial to use the good settings for extracting the lora and finetuning the model though. For extracting the LORA, the settings can be found in an image at the very bottom of this patreon post However, do note that in the image, the Clamp Quantile and Minimum difference don't have red rectangels around them, but they do have different values than the default and you have to use those precisely.
JFFJE It's crucial to use the good settings for extracting the lora and finetuning the model though. For extracting the LORA, the settings can be found in an image at the very bottom of this patreon post However, do note that in the image, the Clamp Quantile and Minimum difference don't have red rectangels around them, but they do have different values than the default and you have to use those precisely.
 U
U
 P
P P
P P
P FFFPFJ
FFFPFJ SFFSE
SFFSE EE
EE SFFFF
SFFFF




