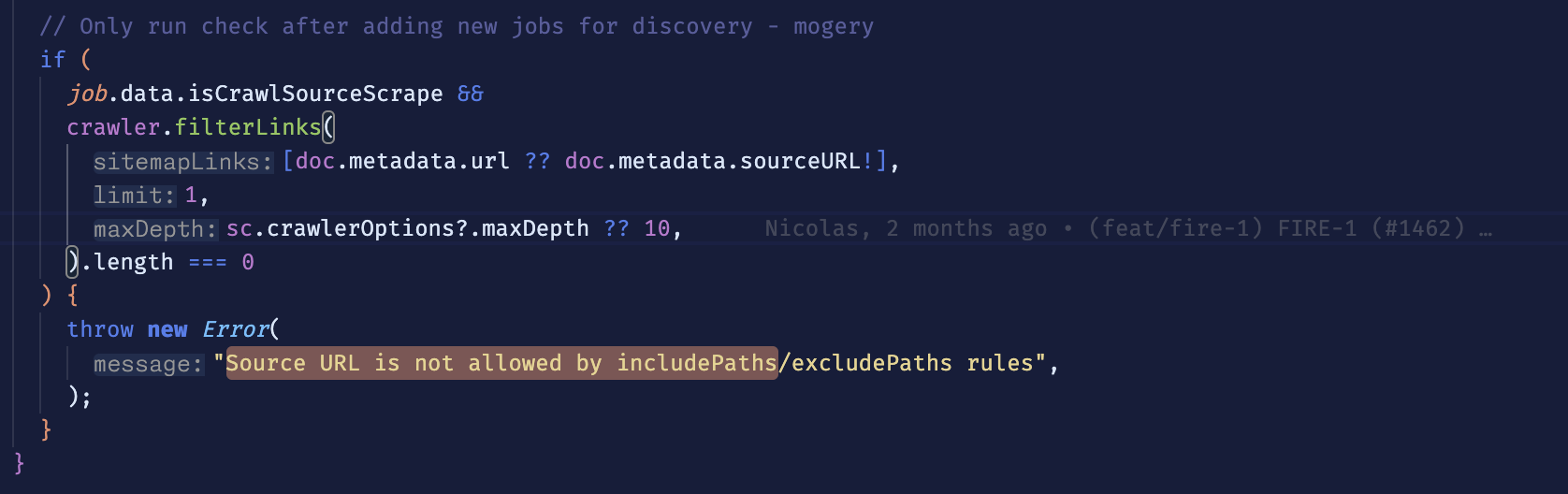
Source URL is not allowed by includePaths/excludePaths
I am trying to crawl this website here, but I noticed I get the same error on other websites if I try to crawl a url with many subpages in the URL. The error being "Source URL is not allowed by includePaths/excludePaths".
https://www.dhl.com/se-sv/home/frakt/hjalpcenter-for-europeisk-vag-och-jarnvag/anvandbar-information-och-hamtningsbara-filer.html
I get the same error with this URL:
https://demo.cyotek.com/features/authentication.php
Is it not possible to start a crawl from X amount of links deep? It works fine if I start crawling from the landingpages of those websites. I get the error regardless of parameters. For example limit 10 and depth 3.
3 Replies
Have you set crawlerOptions?.maxDepth?
i think you are referring to scrapeOptions? i followed the docs here: https://docs.firecrawl.dev/api-reference/endpoint/crawl-post and that one has a scrapeOptions. my parameters that i start a crawl with are modeled like this:
url: HttpUrl
namespace: str
maxDepth: int = 1
limit: int = 1
ignoreSitemap: bool = False
ignoreQueryParameters: bool = False
allowBackwardLinks: bool = False
allowExternalLinks: bool = False
includePaths: List[str] = []
excludePaths: List[str] = []
maxDiscoveryDepth: Optional[int] = None scrapeOptions: Optional[Dict] = {"formats": ["markdown", "screenshot"], "blockAds": True, "onlyMainContent": True} I have tried with different parameters, mostly I have experimented with having limit and maxDepth increasted to anywhere between 10-100 with varying results. if i set backwardlinks to true and a really high maxDepth and limit, it seems I can get some of the content that I expect, but I also get a lot of other pages that I dont want. to clarify: im trying to crawl that DHL-page I linked to, and all the PDF's that are linked on that page. nothing else.
maxDepth: int = 1
limit: int = 1
ignoreSitemap: bool = False
ignoreQueryParameters: bool = False
allowBackwardLinks: bool = False
allowExternalLinks: bool = False
includePaths: List[str] = []
excludePaths: List[str] = []
maxDiscoveryDepth: Optional[int] = None scrapeOptions: Optional[Dict] = {"formats": ["markdown", "screenshot"], "blockAds": True, "onlyMainContent": True} I have tried with different parameters, mostly I have experimented with having limit and maxDepth increasted to anywhere between 10-100 with varying results. if i set backwardlinks to true and a really high maxDepth and limit, it seems I can get some of the content that I expect, but I also get a lot of other pages that I dont want. to clarify: im trying to crawl that DHL-page I linked to, and all the PDF's that are linked on that page. nothing else.
Firecrawl Docs
Crawl - Firecrawl Docs