Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
Did anyone run into this issue where if you have solid background (mainly gray / white / blue) the part of the image the runs through the k-sampler has a weird color shift. It only happens with solid background. I assume it's somewhere in a rgb/srgb color shift?
all sdxl character loras i've trained on civitai end up with extra limbs and many deformities, will a onetrainer sdxl fine-tune into a lora solve this issue? i guess it's best to finetune on sdxl base? or does other realistic checkpoints work as well. i'd like the lora to be flexible and to be used with multiple checkpoints, so then it's best to use sdxl base, yes? @Dr. Furkan Gözükara
ok, thanks doc. I've done some flux finetunes for character. problem with flux fine tunes is to carry over skin textures properly. and it also feels like the face inpainting in swarmui makes skin more plastic. feels like the skin textures in my training images were not learned properly. would close-ups be a solution, and should face always be visible on all photos, or could you use a photo of only stomach i.e. with detailed skin etc?
Video editing using diffusion models has achieved remarkable results in generating high-quality edits for videos. However, current methods often rely on large-scale pretraining, limiting flexibility for specific ed...
@Dr. Furkan Gözükara quick question, i'm training a model in flux and i wanna use 24 images instead of 12 images for training, what settings do i need to change in epochs / iterations? i remember u mentioned it in one of the tutorials but having trouble finding that part of your video again
@Dr. Furkan Gözükara does any of your apps extract first the first frame from a video to save as png? best would be to run through batch of videos in a folder, then save first frame of each video in a separate folder as png
I am running the forgev9 installer and love how smooth and fast it is. I get this error message whenever I use a face model from Reactor: RuntimeError: D:\a_work\1\s\onnxruntime\python\onnxruntime_pybind_state.cc:857 onnxruntime::python::CreateExecutionProviderInstance CUDA_PATH is set but CUDA wasnt able to be loaded. Please install the correct version of CUDA andcuDNN as mentioned in the GPU requirements page (https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements), make sure they're in the PATH, and that your GPU is supported.
I have been able to use reactor in the past with older versions of forgeUI and it currently works inside ComfyUI. I have a RTX 5070 ti 16gb as my primary GPU. I have manually updated cuda, cudnn, onnyxruntime and onnyxruntime-gpu inside the venv folder and have also updated the PATH variables. What am I missing?
 C
C
 �
� F
F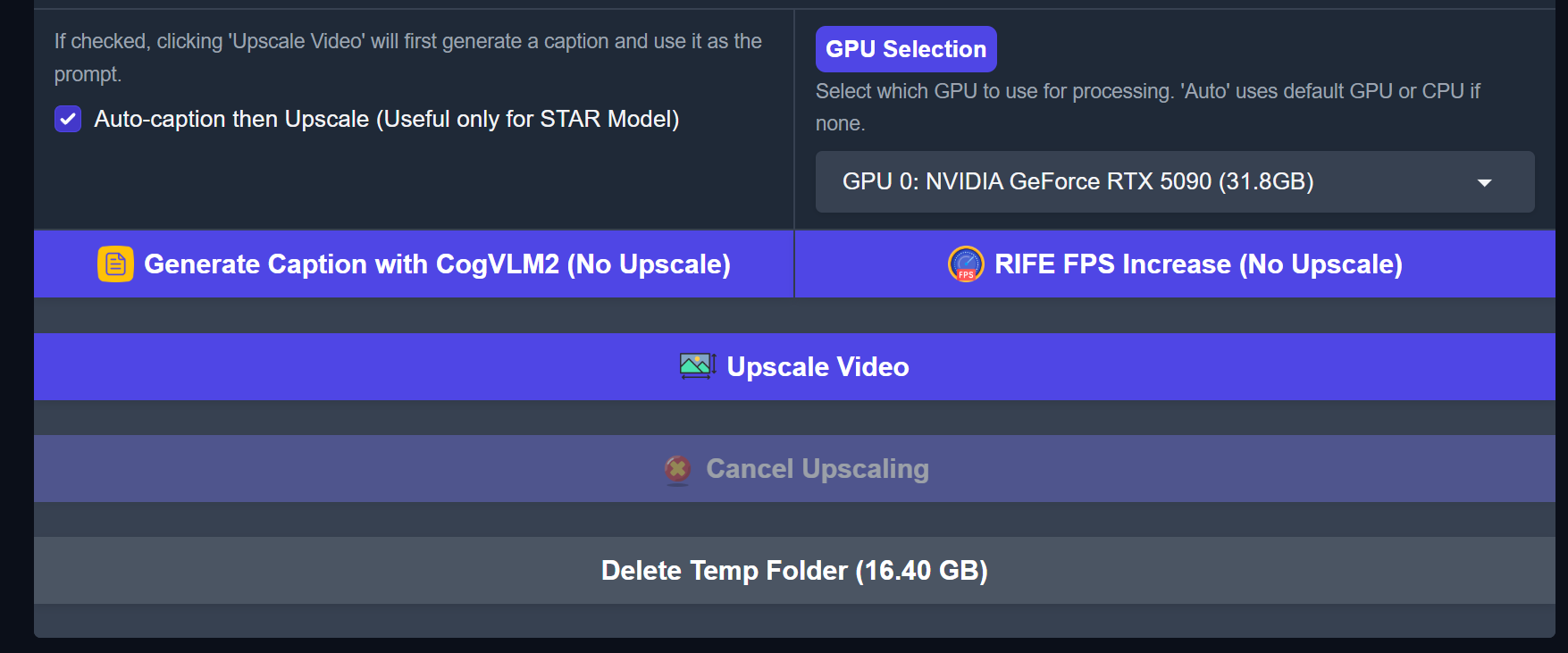

 A
A S
S

 J
J

 A
A






