folder name means
folder name means
 F
F
 J
J FF
FF U
U The finetuned checkpoint is about 23gb, is there a way to reduce the size without losing the quality?FFUF
The finetuned checkpoint is about 23gb, is there a way to reduce the size without losing the quality?FFUF EEFFFFEFFFFEFUU
EEFFFFEFFFFEFUU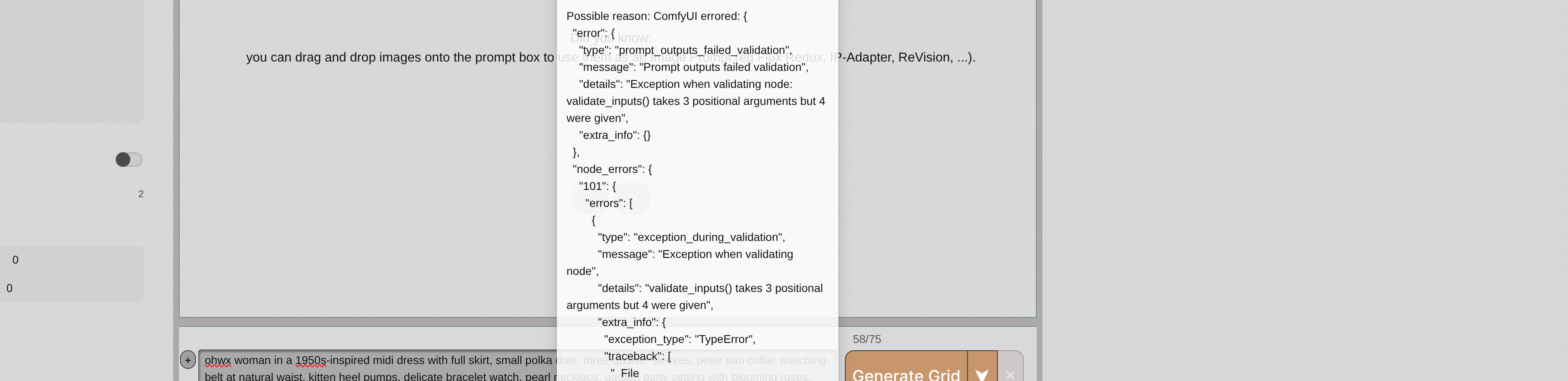 FFUUFFUFFFUFFUFU
FFUUFFUFFFUFFUFU I completely misunderstood. Thanks for the clarification.UFF
I completely misunderstood. Thanks for the clarification.UFF U I will take a look!UFFU for 15 image dataset, were you able to figure what the unet learning rate was ideal?FF
U I will take a look!UFFU for 15 image dataset, were you able to figure what the unet learning rate was ideal?FF


