Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
Good morning, gentlemen, i've been using Tier1_48_GB_Faster_v2.json for dreambooth on runpod and constantly getting the training terminated on text encoders training part So, subprocess.CalledProcessError: Command '['/opt/environments/python/kohya/bin/python3.10', '/workspace/kohya_ss/sd-scripts/sdxl_train.py', '--config_file', '/workspace/kohya_ss/outputs/config_dreambooth-20250719-133856.toml', '--max_grad_norm=0.0', '--no_half_vae', '--train_text_encoder', , '--learning_rate_te2=0']' returned non-zero exit status 2.
As i understand kohya wants non-zero parameter for text_encoder2 should i insert the same as on te1, 0.000003?
Hey guys. I'm currently training a flux style finetune using kohya with a dataset consisting of around 1800 images total. When leaving the max epoch to 0 (default) it was automatically set to 6. This seemed strange to me, I've never used a dataset this large. I'm using the "Batch_Size_7_48GB_GPU_46250MB_29.1_second_it_Tier_1" preset as provided by Dr. Furkan. Should I tweak another variable like learning rate for a dataset this big? I set max epochs to 10 and it says it will train for 20 hours on an A6000 GPU. I thought I'd ask before I have it train for 20 hours for it to end up being trash.
Thanks for the response! They are high quality screenshots from a show with a unique art style, consistent in style only. All of them are uniquely captioned in the same format to describe the image, with a triggerword for the style at the start of the caption. I'll try as you suggested. One more question: Can I train 10 epochs, and with the resulting model, continue training for another 5 epochs in a separate instance (using the resulting model as a base) to get the same or similar result as if I were training 15 epochs from the start? A checkpoint per epoch would require me to regularly offload the models onto another server due to disk space, risking messing this up and epochs not saving.
Also, although maybe not particularly relevant. They are actually 2 sets of the same 900 images in different aspect ratios, according to my own testing and other testing I've seen, training on different aspect ratios improves results. Particularly with style finetunes. Never tried it with this many images though.
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacity of 79.20 GiB of which 16.62 MiB is free. Process 2510593 has 79.18 GiB memory in use.,
training was successful on batch size=2 on h100 sxm This thing is demanding indeed, consumed like 77gb vram
I was wondering if you have a python code that I can refer/modify for finetuning instead of using the kohya gui? I want to load the parameters and train without having to open the interface and load the parameters all the time.
 F
F A
A L
L L
L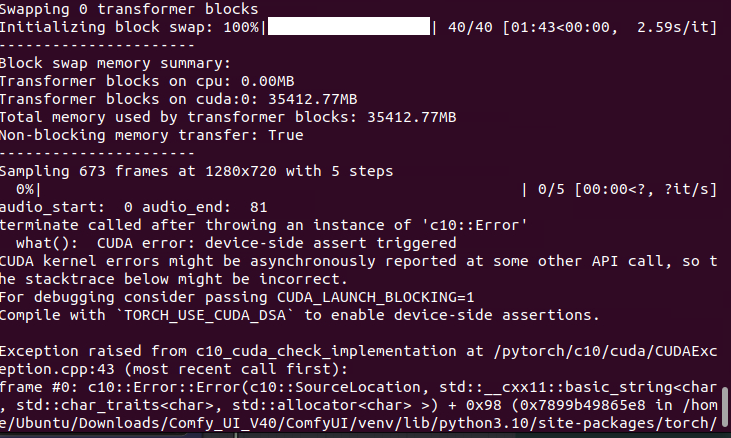
 U
U