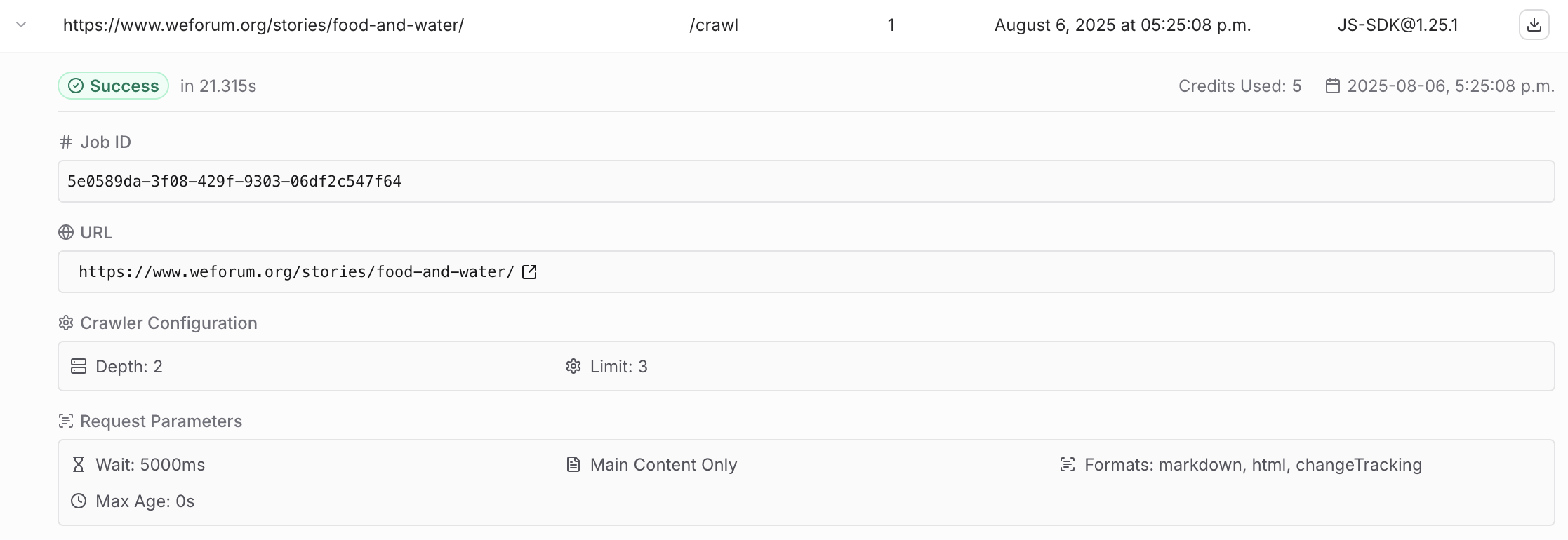
Crawl status tool is returning 500, need help to verify whats wrong with the request.
I am calling firecrawl_check_crawl_status tool in remote mcp with the following argument. {"id": job_id}. Acticity logs shows just one page being crawled although I set depth 2, limit 3. Posted a screenshot of activity logs (showing a different jobid). I have set a depth and limit but the log says one one page is crawl and 5 credit is used.
Response:
{'result': {'content': [{'type': 'text', 'text': 'Error: Failed to check crawl status. Status code: 500. Error: An unexpected error occurred. Please contact help@firecrawl.com for help. Your exception ID is 59b6e23c4a03481fa61b958c7b08c15c'}], 'isError': True}, 'jsonrpc': '2.0', 'id': 1754498520281}
Response:
{'result': {'content': [{'type': 'text', 'text': 'Error: Failed to check crawl status. Status code: 500. Error: An unexpected error occurred. Please contact help@firecrawl.com for help. Your exception ID is 59b6e23c4a03481fa61b958c7b08c15c'}], 'isError': True}, 'jsonrpc': '2.0', 'id': 1754498520281}