Question about PDF Scraping
Hey team  ,
,
I'm working on a data scraping task and had a question about Firecrawl's capabilities for a specific use case.
My Goal: To extract interest rates for Certificates of Deposit (CDTs) from a bank's website.
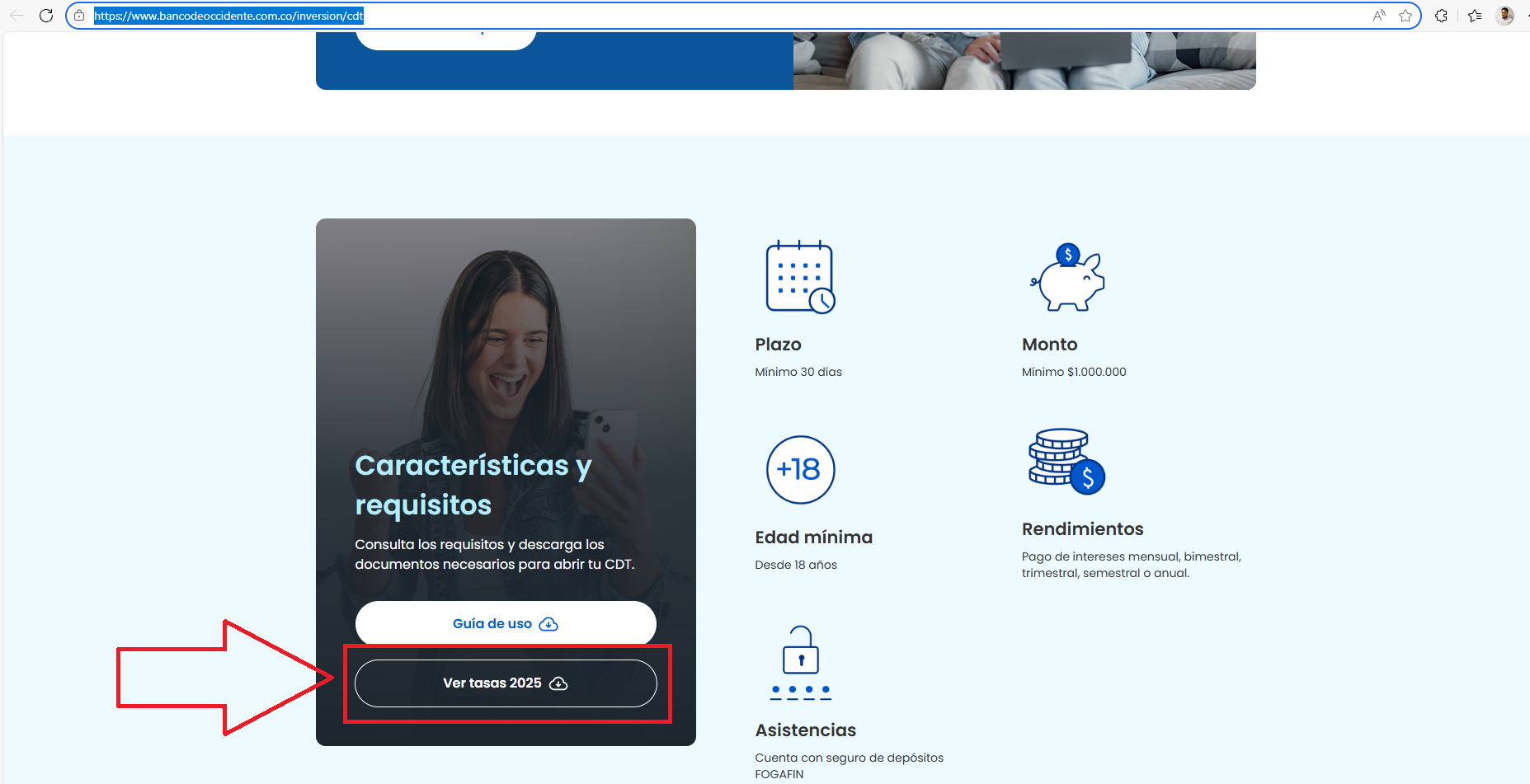
The Challenge: The data I need isn't in an HTML table. It's located inside a PDF file that users have to download from their investment page: https://www.bancodeoccidente.com.co/inversion/cdt.
I've attached a screenshot showing the page and the button that links to the PDF.
I was planning to use the /extract endpoint since it's excellent for pulling structured data. My main question is: Can Firecrawl's /extract endpoint process a URL that points directly to a PDF file?
If it can ingest the PDF content and pass it to the underlying LLM, it would be a super-efficient way to extract the structured data I need (like investment term, amount range, and interest rate).
I know the alternative is a multi-step process (download the PDF, use a library like pdfplumber to extract text, then process it), but a single-step extraction directly with Firecrawl would be a game-changer.
Has anyone tried this before or have any insights on Firecrawl's capabilities with PDFs?
Thanks for any help or suggestions!
,I'm working on a data scraping task and had a question about Firecrawl's capabilities for a specific use case.
My Goal: To extract interest rates for Certificates of Deposit (CDTs) from a bank's website.
The Challenge: The data I need isn't in an HTML table. It's located inside a PDF file that users have to download from their investment page: https://www.bancodeoccidente.com.co/inversion/cdt.
I've attached a screenshot showing the page and the button that links to the PDF.
I was planning to use the /extract endpoint since it's excellent for pulling structured data. My main question is: Can Firecrawl's /extract endpoint process a URL that points directly to a PDF file?
If it can ingest the PDF content and pass it to the underlying LLM, it would be a super-efficient way to extract the structured data I need (like investment term, amount range, and interest rate).
I know the alternative is a multi-step process (download the PDF, use a library like pdfplumber to extract text, then process it), but a single-step extraction directly with Firecrawl would be a game-changer.
Has anyone tried this before or have any insights on Firecrawl's capabilities with PDFs?
Thanks for any help or suggestions!