Hey everyone, Kicking off a new training run for my Qwen-Image likeness LoRA today. This time, I'm
Hey everyone,
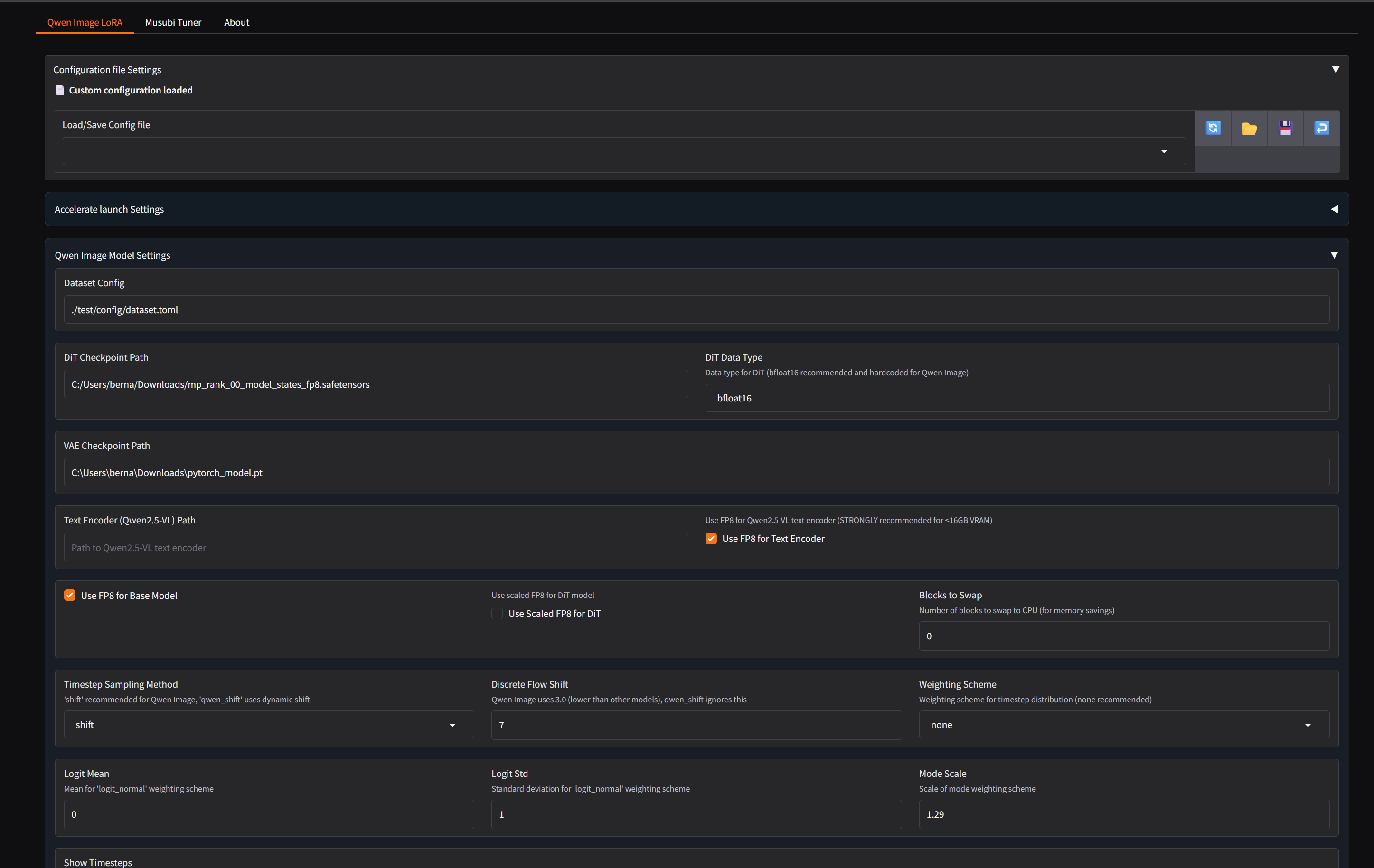
Kicking off a new training run for my Qwen-Image likeness LoRA today. This time, I'm diving into some of the newer, more advanced parameters available in Musubi-Tuner to see if they can improve the final quality.
Here's what I'm experimenting with:
LoRA+: Using a loraplus_lr_ratio of 4, which is supposed to make the training more efficient by using a higher learning rate on part of the network.
PyTorch Dynamo: Enabled the inductor backend. I'm curious to see if the JIT compiler gives any extra speed boost on top of the performance gains from WSL.
New Timestep Sampler: Switched to the qinglong_qwen sampler. It's a hybrid method that's reportedly better for style and likeness learning.
Post-Hoc EMA Merging: After the training is done, I'll also be using the new script to merge the best checkpoints into one final model instead of just picking a single one. The goal is a more stable and accurate LoRA.
The training is running in WSL2 (Ubuntu) using the Musubi-Tuner scripts on an RTX 4090.
I'm really curious to see what effect these new parameters will have on the final result. I'll let you know how it goes!
Kicking off a new training run for my Qwen-Image likeness LoRA today. This time, I'm diving into some of the newer, more advanced parameters available in Musubi-Tuner to see if they can improve the final quality.
Here's what I'm experimenting with:
LoRA+: Using a loraplus_lr_ratio of 4, which is supposed to make the training more efficient by using a higher learning rate on part of the network.
PyTorch Dynamo: Enabled the inductor backend. I'm curious to see if the JIT compiler gives any extra speed boost on top of the performance gains from WSL.
New Timestep Sampler: Switched to the qinglong_qwen sampler. It's a hybrid method that's reportedly better for style and likeness learning.
Post-Hoc EMA Merging: After the training is done, I'll also be using the new script to merge the best checkpoints into one final model instead of just picking a single one. The goal is a more stable and accurate LoRA.
The training is running in WSL2 (Ubuntu) using the Musubi-Tuner scripts on an RTX 4090.
I'm really curious to see what effect these new parameters will have on the final result. I'll let you know how it goes!