Struggling with paginated sources - Firecrawl amazing for details, painful for lists
Hey team! Love Firecrawl for single page extraction (the JSON schema feature is amazing), but I'm hitting a wall with paginated list pages.
My use case: Monitoring Italian government tender dashboards that update daily. Need to track new tenders across multiple paginated pages.
The problem:
- These dashboards have 10-20 pages with ~20 tenders each
- Pagination is usually ?page=0, ?page=1 etc (sometimes differs)
- The crawl endpoint just... doesn't work reliably for this (especially self-hosted)
- Can't figure out how to extract multiple items from a single page
Currently I have a "hacky solution", using BeautifulSoup for list pages, Firecrawl for detail pages. Feels wrong having two different scraping tools :)
Example: https://www.consip.it/imprese/bandi - typical paginated dashboard
Questions:
1. Am I missing something obvious for handling pagination?
2. Any example or existing implementation I can look into?
3. Any best practices for monitoring dashboards that update frequently?
Really want to go all in on Firecrawl but this pagination thing is killing me. Any guidance would be appreciated thank you :)
6 Replies
Hey there! Can you share an example of a URL you are trying to crawl? I can help you figure out how to scrape it on our cloud version of Firecrawl if you are interested.
That would really helpful thanks! I was using self-hosted to play around without wasting credits.
I have a few:
https://www.consip.it/imprese/bandi?f%5B0%5D=stato%3A51
https://europa.provincia.bz.it/it/bandi-e-avvisi
https://www.lazioeuropa.it/bandi/
I need to extract the tenders from the lists, and scrape their detail page.
I tried with /crawl but had so many issues. For some sources it returned too many pages, sometimes it returned the same page only (e.g. 50 times, and I did tweak the params to avoid it).
Quite messy, and patching around it (especially initially) would have been harder than just finding another way, and since I have quite a few of these (not just 3) to track, I switched to extracting the lists with custom code, and then scrape the "detail" using /scrape json (which works great!)
Bonus: I frequently re-run everything to catch changes in the number of records or changes within them. I expect something can be done with the diff feature, but had not much luck with that.
I also used Observer to see if it would work, but unfortunately it didn't. Problem is always the multiple pages of records.
Happy to share more or answer any question, and to use the cloud version if it works.
LazioEuropa
Bandi Archive - LazioEuropa
Forgot to mention you! my bad. Let me know when you have some time for this :) thanks
Sorry for the delayed response. If you want to crawl only the links on that starting page you could try crawlEntireDomain=true, maxDiscoveryDepth=1, and ignoreSitemap=true.
hello, is there a way to extract all addresses of restaurants from a source like this, for example - https://www.kfc.co.th/find-store
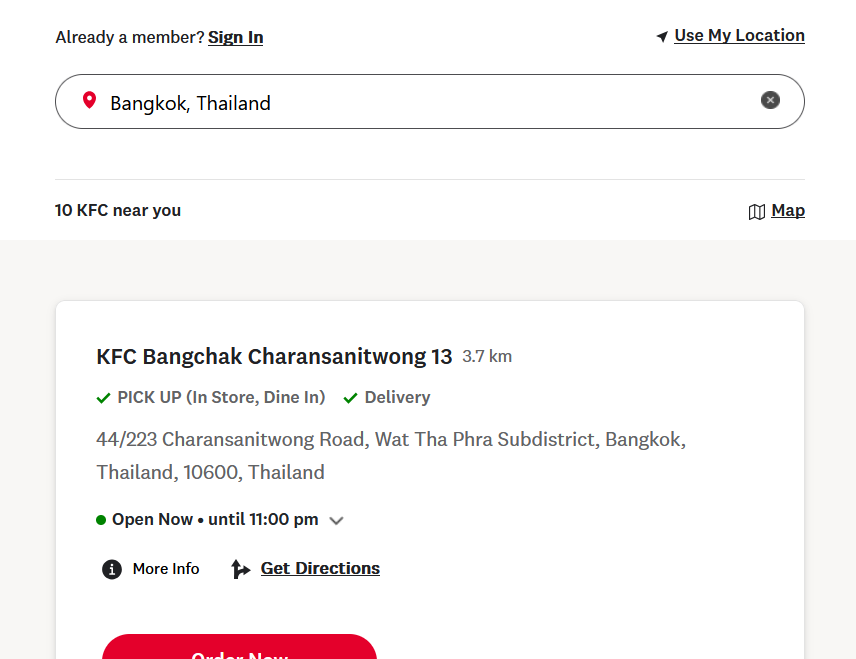
You should check out our JSON scraping mode, which is supported by endpoints like /scrape and /crawl.