Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
I found using a character Lora that I trained with flux on flux krea is giving me the textures of krea with the character. Vs the finetune I was getting fuzzy images
I was trying to generate using my trained dreambooth model on Runpod. It shown this error in SwarmUI. When I run it in massedcompute, it's working fine. Do you what is the cause of this error?
@Dr. Furkan Gözükara Hey Dr, is there a theoratical limit with checkpoint training regarding dataset ? I have a good 350 images, is that too much or I would just need to train it longer ?
Hi Furkan, I want to confirm something about your captioning theory. For a small and very consistent dataset (around 50 solid product photos on white background), is it still best practice to only use the token + class as caption (like CCCSNOOO bag), and let the images carry all visual attributes? Or in such small homogeneous datasets, could adding more detailed captions (e.g. color, material, shape) actually help stabilize training with T5?
Good question! AFAIk depends on what you want. iI you dont caption a certain thing, it will always generate it in that thing, unless you really force it in a prompt. If you caption something (like color, material) you can more easily change the color , material later. I think Furkan will confirm this
Thanks for the clarification! If T5 is active with such a small and homogeneous dataset, could relying only on token + class captions cause it to fall back to it's pretraining bias (e.g. anime/fantasy)? In that case, would the safer option be to disable T5?
Also, around what epoch should the results typically start to become visible? I’ve tested the token + class approach, but even after 190 epochs I still mostly get strange anime-like outputs. Does that indicate that the LoRA simply needs more training, or that the captioning strategy itself is unsuitable for this setup?
Yes, 5e-5 looks low compared to typical SDXL LoRAs. But for Flux1 it’s the standard recommendation (e.g. Furkan’s config). It trains slower, but keeps things stable since Flux is more sensitive than SDXL/1.5. But maybe I'm wrong.
try to find out if you can generate images while it's training (that means , the training algorithm stops for a moment to generate an image based on a prompt set)
have you tried creating character checkpoints from krea? I'm at 10000 steps and the model is clearly ruined by now: all stylized outputs became blurry mangled and photorealistic
 K
K T
T F
F Z
Z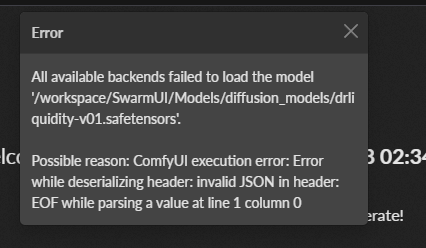
 S
S U
U
 S
S E
E J
J
 P
P
 A
A



 X
X T
T






