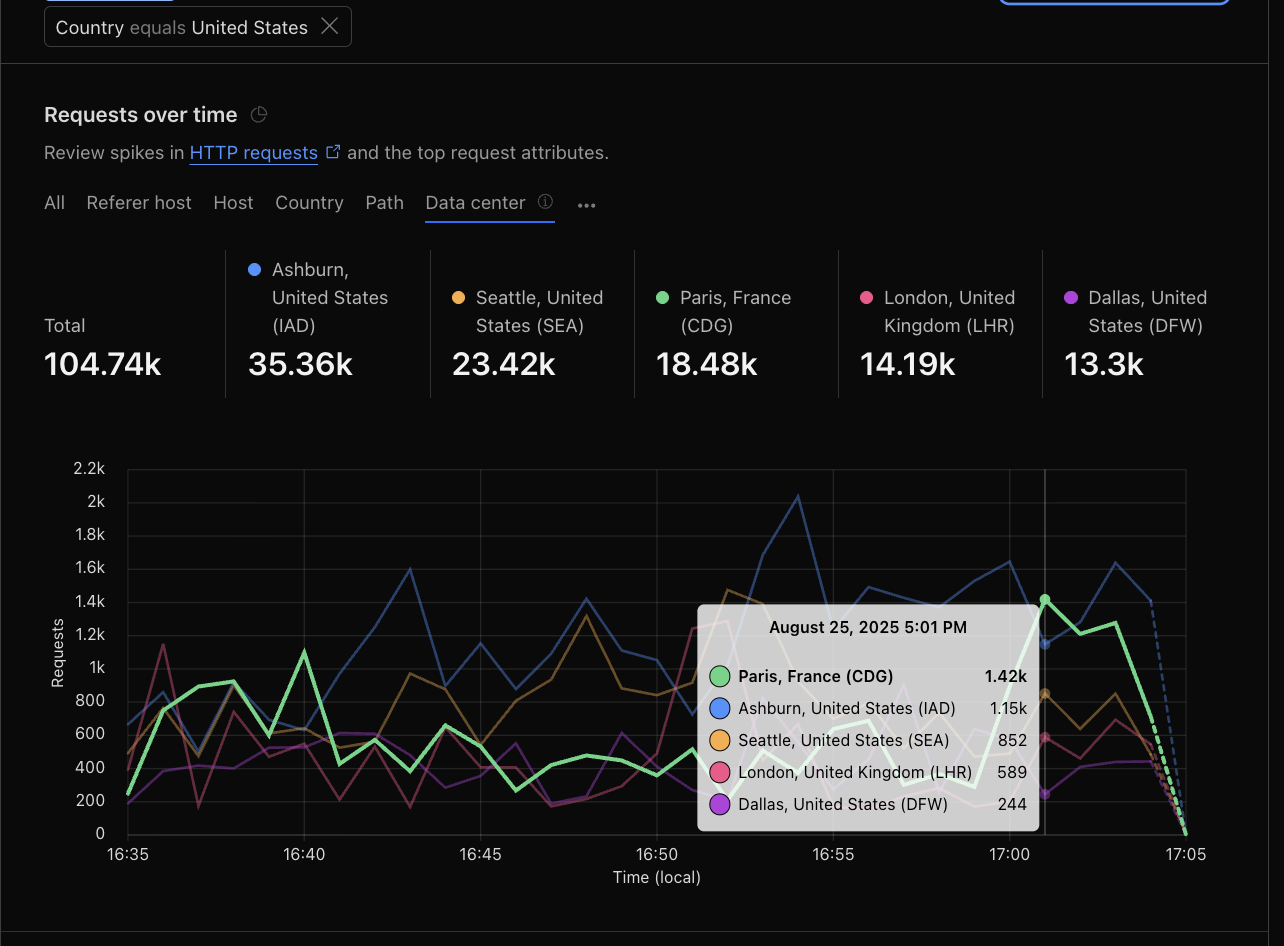
US traffic is being served by London and France datacenter
around 13:00 UTC most of the US traffic is being pointed to Cloudflare France and London datacenters. This causes our Europe region to sustain "undesigned" traffic and that region goes down or slows down a lot.
This repeats daily till about 01:00 UTC and US traffic is again served by US datacenters.
As the traffic goes over seas the ping for end user increases.
The only solution to controll that was to shut down the EU Load Balancer pool, but that does not resolve increased latency.
This can be seen in HTTP Traffic chart, filtering out US and selecting to group by Datacenter.
The chart directly corelates with what we see in our internal traffic analysis.
This repeats daily till about 01:00 UTC and US traffic is again served by US datacenters.
As the traffic goes over seas the ping for end user increases.
The only solution to controll that was to shut down the EU Load Balancer pool, but that does not resolve increased latency.
This can be seen in HTTP Traffic chart, filtering out US and selecting to group by Datacenter.
The chart directly corelates with what we see in our internal traffic analysis.

Welcome to the official Cloudflare Developers server. Here you can ask for help and stay updated with the latest news
86,942Members
Resources
Similar Threads
Was this page helpful?